共19篇
DataWorks/MaxCompute
MaxCompute(ODPS)是适用于数据分析场景的企业级 SaaS(Software as a Service)模式云数据仓库,以 Serverless 架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您可以经济并高效地分析处理海量数据。

 admin
4 月 之前
admin
4 月 之前
MaxCompute 正则函数
MaxCompute提供了一套完整的正则表达式处理函数,支持匹配、替换、提取、验证等常见正则操作,底层兼容 Perl 兼容正则表达式(PCRE)语法。以下是核心正则函数的详细说明、语法、示例,结合实际业务场景(如日志解析、数据清洗)讲解用法。
MaxCompute提供了一套完整的正则表达式处理函数,支持匹配、替换、提取、验证等常见正则操作,底层兼容 Perl 兼容...
 admin
9 月,2 周 之前
admin
9 月,2 周 之前
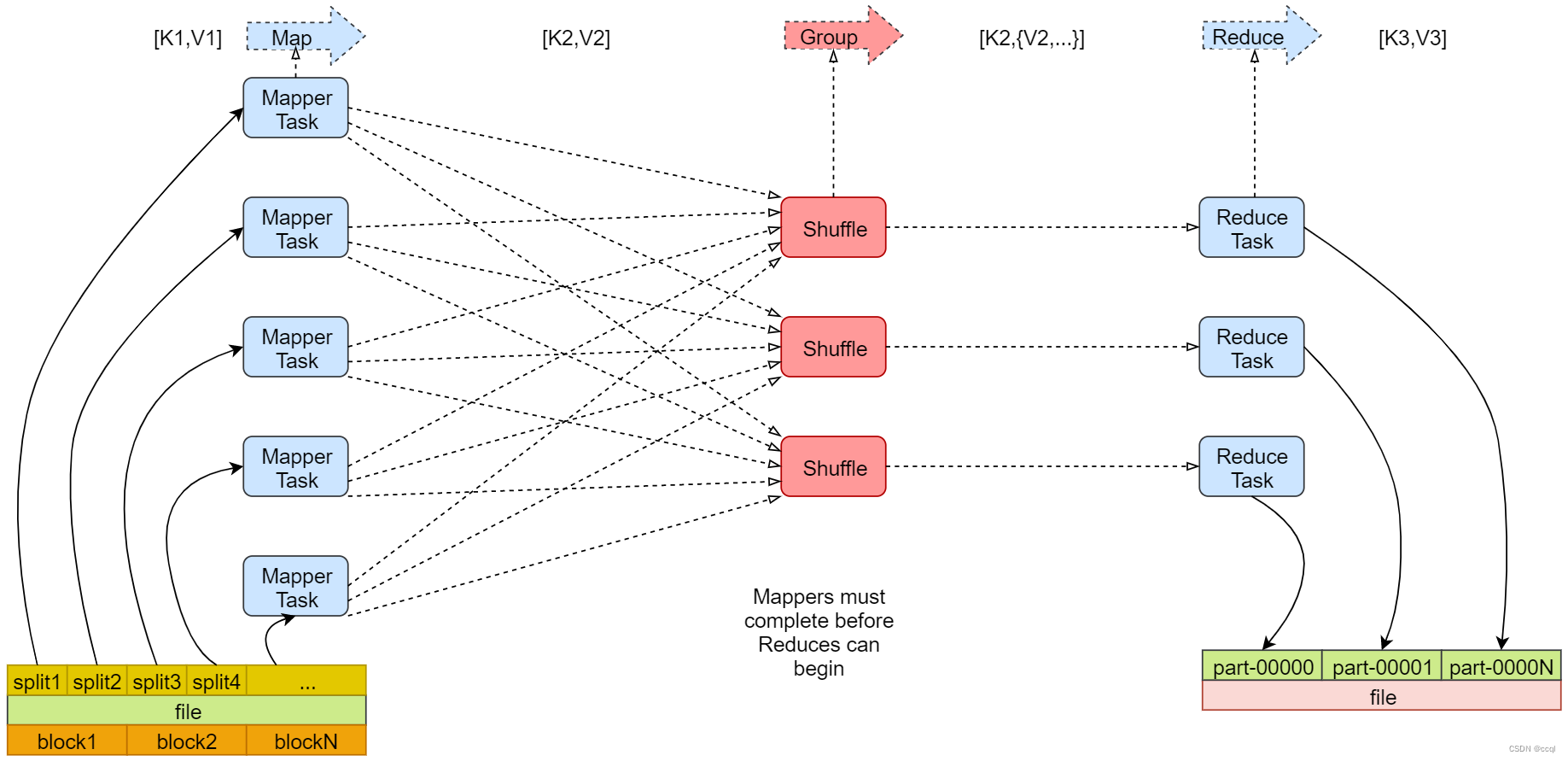
【Hadoop】MapReduce 原理剖析(Map、Shuffle、Reduce 三阶段)
MapReduce 是一种分布式计算模型,是 Google 提出来的,主要用于搜索领域,解决海量数据的计算问题。
MapReduce 是一种分布式计算模型,是 Google 提出来的,主要用于搜索领域,解决海量数据的计算问题。
 admin
9 月,2 周 之前
admin
9 月,2 周 之前
大数据SQL-查询最新有效订单记录
现有订单操作记录表 t_order_log,包含用户 ID,订单 ID,操作状态,操作时间。该表中操作状态包含下单、取消、改单,三种状态,用户取消订单后,则该订单不能再做修改。
现有订单操作记录表 t_order_log,包含用户 ID,订单 ID,操作状态,操作时间。该表中操作状态包含下单、取消、...
 admin
10 月 之前
admin
10 月 之前
MaxCompute SQL 调优之 Join Hint
在 MaxCompute SQL 中处理大数据量表时,数据倾斜是一个常见的性能瓶颈。当两张大表进行 JOIN 操作时,如果关联键分布不均,某些节点可能会承担过多的数据处理任务,导致任务执行效率低下。为了解决这一问题,需要从 JOIN 键的选择、技术手段的...
在 MaxCompute SQL 中处理大数据量表时,数据倾斜是一个常见的性能瓶颈。当两张大表进行 JOIN 操作时,如果...
 admin
1 年,1 月 之前
admin
1 年,1 月 之前
SQL 优化之谓词下推
所谓谓词下推,就是将尽可能多的判断更贴近数据源,以使查询时能跳过无关的数据。用在 SQL 优化上来说,就是先过滤再做聚合等操作。
所谓谓词下推,就是将尽可能多的判断更贴近数据源,以使查询时能跳过无关的数据。用在 SQL 优化上来说,就是先过滤再做聚合等操作。
 admin
1 年,1 月 之前
admin
1 年,1 月 之前
MaxCompute 格式化函数
在 MaxCompute 中,有多种格式化相关的函数,下面详细介绍一些常用的格式化函数及其使用方法。
在 MaxCompute 中,有多种格式化相关的函数,下面详细介绍一些常用的格式化函数及其使用方法。
 admin
1 年,2 月 之前
admin
1 年,2 月 之前
周期任务基本运维操作
周期任务是指在调度系统按照调度配置周期性自动调度的任务。您可以在运维中心 > 周期任务列表查看指定工作空间下的周期任务,并对任务进行运维操作,包括自动调度和手动运行周期任务、查看任务运行详情、暂停任务、下线任务等。本文为您介绍周期任务的运维操作详情。
周期任务是指在调度系统按照调度配置周期性自动调度的任务。您可以在运维中心 > 周期任务列表查看指定工作空间下的周期任务,并...



- Django Web 开发 4
- Oracle 数据库开发 9
- Oracle 性能优化 12
- Python 基础知识 8
- 开发工具配置 5
- Oracle 数据库管理 2
- Oracle 索引技术 2
- Python 数据分析 6
- Hive 1
- DataWorks/MaxCompute 19
- MySQL 5
- Greenplum/AnalyticDB 8
- PyODPS 3
- 数据湖仓 11