分析函数用来计算一组行的聚合值,与聚集函数不同的是分析函数为每组行返回多条记录。由分析函数语法定义的行集就叫做窗口,窗口决定了对于当前行而言进行计算的行的范围,窗口的范围则可能基于物理的行数或者逻辑间隔。
函数语法
analytic_function([ arguments ]) OVER (analytic_clause)
- OVER() 是开窗函数,这是开启分析函数的起点
- PARTITION BY 是窗口
- ORDER BY 是窗口规则(排序)
- ROW|RANGE BETWEEN 是窗口范围
analytic_function
analytic_function 指定分析函数的名称,如 RANK 、LAG 等 ...
analytic_clause
analytic_clause 用来确定分析函数的操作规则,包括 query_partition_clause 、order_by_clause 和 windowing_clause 三个子句。
# analytic_clause 语法: [ query_partition_clause ] [ order_by_clause [ windowing_clause ] ]
-
query_partition_clause 记录集分组子句,类似于 GROUP BY 分组
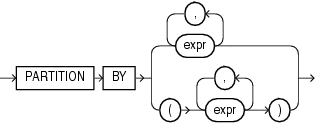
-
order_by_clause 记录集排序子句, 类似于 ORDER BY 排序
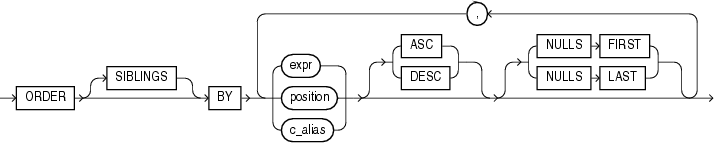
-
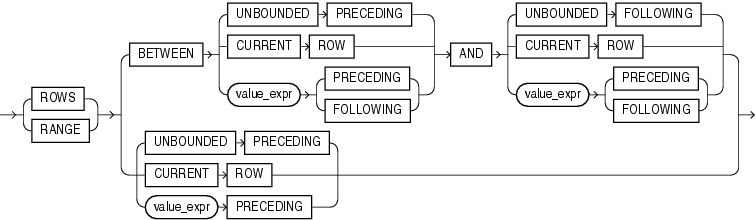
windowing_clause 记录集窗口范围子句
函数目录
| 序号 | 函数分类 | 函数名称 | 函数简介 |
| 1 | 常规统计函数 | MAX | 在一个分组的数据窗口中查找表达式的最大值 |
| 2 | MIN | 在一个分组的数据窗口中查找表达式的最小值 | |
| 3 | AVG | 计算分组中表达式的平均值 | |
| 4 | SUM | 计算分组中表达式的累积和 | |
| 5 | COUNT | 对一组内发生的事情进行累计计数 | |
| 6 | 数据排序函数 | RANK | 根据 order by 排序结果,计算组间相对位置,有跳号 |
| 7 | DENSE_RANK | 根据 order by 排序结果,计算组间相对位置,无跳号 | |
| 8 | ROW_NUMBER | 返回有序组中一行的偏移量,按特定的顺序分配行号 | |
| 9 | FIRST | 从 DENSE_RANK 结果中返回最前面的一行 | |
| 10 | FIRST_VALUE | 返回分组中数据窗口的第一个值 | |
| 11 | LAST | 从 DENSE_RANK 结果中返回最后面的一行 | |
| 12 | LAST_VALUE | 返回分组中数据窗口的最后一个值 | |
| 13 | LAG | 访问结果集中的其他行,即当前行之前的行 | |
| 14 | LEAD | 访问结果集中的其他行,即当前行之后的行 | |
| 15 | 数据分布函数 | NTILE | 将一个分组分为"表达式"的散列表示 |
| 16 | CUME_DIST | 计算一行在分组中的相对位置 | |
| 17 | PERCENT_RANK | 与 CUME_DIST 类似,计算规则稍有差别 | |
| 18 | PERCENTILE_CONT | 返回一个与输入的百分比值相对应的数据值 | |
| 19 | PERCENTILE_DISC | 返回一个与输入的百分比值相对应的数据值 | |
| 20 | RATIO_TO_REPORT | 计算当前值对应于总数据的百分比 | |
| 21 | REGR_SLOPE | 线性回归函数(适合最小二乘法回归线) | |
| 22 | REGR_INTERCEPT | ||
| 23 | REGR_COUNT | ||
| 24 | REGR_R2 | ||
| 25 | REGR_AVGX | ||
| 26 | REGR_AVGY | ||
| 27 | REGR_SXX | ||
| 28 | REGR_SYY | ||
| 29 | REGR_SXY | ||
| 30 | 统计分析函数 | CORR | 返回一堆表达式的相对系数 |
| 31 | COVAR_POP | 返回一堆表达式的总体协方差 | |
| 32 | COVAR_SAMP | 返回一堆表达式的样本协方差 | |
| 33 | STDDEV | 计算当前行关于分组的标准偏离 | |
| 34 | STDDEV_POP | 计算总体标准偏离,并返回总体变量的平方根 | |
| 35 | STDDEV_SAMP | 计算累计样本标准偏离,并返回总体变量的平方根 | |
| 36 | VAR_POP | 返回非空集合的总体方差 | |
| 37 | VAR_SAMP | 返回非空集合的样本方差 | |
| 38 | VARIANCE | 返回表达式的变量 | |
| 39 | 其它函数 | LISTAGG | 字符串拼接 |
| 40 | MEDIAN | 返回一组数据的中间值(中位数) | |
| 41 | NTH_VALUE | 返回排序后结果集中任意一行 |
窗口范围
windowing_clause 用来指定分组中当前行的计算范围,无论是 rows 还是 range 窗口,窗口总是在分组中从上至下滑动的,窗口范围由 betwen ... and ... 限定,而不用的话都表示窗口到当前行结束。
rows关键字,指定窗口由 物理行 构成,即物理座位排数;range关键字,指定窗口由 逻辑偏移量 构成,即符合指定的逻辑条件的范围;between ... and ...关键字,用来指定窗口的起始点和终结点;unbonded preceding关键字,指明窗口开始于分组的第一行;current row如果作为起始点,用来指明窗口开始于当前行或当前值;如果作为终结点,用来指明窗口结束于当前行或当前值;unbonded following关键字,指明窗口结束于分组的最后一行;value_expr为物理或逻辑偏移量表达式
默认窗口范围
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date) sum_sal1, --分组第一行和当前行
sum(t.salary) over(partition by t.dept_id) sum_sal2, --分组第一行和分组最后一行
sum(t.salary) over(order by t.hire_date) sum_sal3 --未分组,结果集第一行和最后一行
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY SUM_SAL1 SUM_SAL2 SUM_SAL3
---------- --------------- ---------- ---------- ---------- ---------- ---------- ----------
101 Kochhar Neena 90 1989-09-21 17000 17000 34000 17000
102 De Haan Lex 90 1993-01-13 17000 34000 34000 34000
122 Kaufling Payam 50 1995-05-01 7900 7900 35400 41900
120 Weiss Matthew 50 1996-07-18 8000 15900 35400 49900
121 Fripp Adam 50 1997-04-10 8200 24100 35400 58100
123 Vollman Shanta 50 1997-10-10 6500 30600 35400 64600
124 Mourgos Kevin 50 1999-11-16 4800 35400 35400 69400
rows
rows 窗口,是由分组排序后分组中若干连续的行构成的窗口
rows 窗口目录树:
rows between unbounded preceding and unbounded following
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between unbounded preceding and unbounded following) rows01
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS01
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 35400
120 Weiss Matthew 50 1996-07-18 8000 35400
121 Fripp Adam 50 1997-04-10 8200 35400
123 Vollman Shanta 50 1997-10-10 6500 35400
124 Mourgos Kevin 50 1999-11-16 4800 35400
101 Kochhar Neena 90 1989-09-21 17000 34000
102 De Haan Lex 90 1993-01-13 17000 34000
rows between unbounded preceding and current row/rows unbounded preceding
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between unbounded preceding and current row) rows02,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows unbounded preceding) rows02
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS02 ROWS02
---------- --------------- ---------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 7900 7900
120 Weiss Matthew 50 1996-07-18 8000 15900 15900
121 Fripp Adam 50 1997-04-10 8200 24100 24100
123 Vollman Shanta 50 1997-10-10 6500 30600 30600
124 Mourgos Kevin 50 1999-11-16 4800 35400 35400
101 Kochhar Neena 90 1989-09-21 17000 17000 17000
102 De Haan Lex 90 1993-01-13 17000 34000 34000
rows between unbounded preceding and value_expr preceding
# 该分组的第一行和当前行的前 1 行
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between unbounded preceding and 1 preceding) rows03
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS03
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900
120 Weiss Matthew 50 1996-07-18 8000 7900
121 Fripp Adam 50 1997-04-10 8200 15900
123 Vollman Shanta 50 1997-10-10 6500 24100
124 Mourgos Kevin 50 1999-11-16 4800 30600
101 Kochhar Neena 90 1989-09-21 17000
102 De Haan Lex 90 1993-01-13 17000 17000
rows between current row and value_expr following
# 该分组的第一行和当前行的后 1 行
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between current row and 1 following) rows04 from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS04
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 15900
120 Weiss Matthew 50 1996-07-18 8000 16200
121 Fripp Adam 50 1997-04-10 8200 14700
123 Vollman Shanta 50 1997-10-10 6500 11300
124 Mourgos Kevin 50 1999-11-16 4800 4800
101 Kochhar Neena 90 1989-09-21 17000 34000
102 De Haan Lex 90 1993-01-13 17000 17000
rows between current row and unbounded following
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between current row and unbounded following) rows05
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS05
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 35400
120 Weiss Matthew 50 1996-07-18 8000 27500
121 Fripp Adam 50 1997-04-10 8200 19500
123 Vollman Shanta 50 1997-10-10 6500 11300
124 Mourgos Kevin 50 1999-11-16 4800 4800
101 Kochhar Neena 90 1989-09-21 17000 34000
102 De Haan Lex 90 1993-01-13 17000 17000
rows between current row and current row/rows current row
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between current row and current row) rows06,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows current row) rows06
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS06 ROWS06
---------- --------------- ---------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 7900 7900
120 Weiss Matthew 50 1996-07-18 8000 8000 8000
121 Fripp Adam 50 1997-04-10 8200 8200 8200
123 Vollman Shanta 50 1997-10-10 6500 6500 6500
124 Mourgos Kevin 50 1999-11-16 4800 4800 4800
101 Kochhar Neena 90 1989-09-21 17000 17000 17000
102 De Haan Lex 90 1993-01-13 17000 17000 17000
rows between current row and value_expr following
# 当前行和当前行的后 1 行
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between current row and 1 following) rows07 from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS07
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 15900
120 Weiss Matthew 50 1996-07-18 8000 16200
121 Fripp Adam 50 1997-04-10 8200 14700
123 Vollman Shanta 50 1997-10-10 6500 11300
124 Mourgos Kevin 50 1999-11-16 4800 4800
101 Kochhar Neena 90 1989-09-21 17000 34000
102 De Haan Lex 90 1993-01-13 17000 17000
rows between value_expr preceding and unbounded following
# 当前行的前 1 行和分组最后一行
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between 1 preceding and unbounded following) rows08
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS08
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 35400
120 Weiss Matthew 50 1996-07-18 8000 35400
121 Fripp Adam 50 1997-04-10 8200 27500
123 Vollman Shanta 50 1997-10-10 6500 19500
124 Mourgos Kevin 50 1999-11-16 4800 11300
101 Kochhar Neena 90 1989-09-21 17000 34000
102 De Haan Lex 90 1993-01-13 17000 34000
rows between value_expr preceding and current row/rows value_expr preceding
# 当前行的前 1 行和当前行
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between 1 preceding and current row) rows09
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS09
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 7900
120 Weiss Matthew 50 1996-07-18 8000 15900
121 Fripp Adam 50 1997-04-10 8200 16200
123 Vollman Shanta 50 1997-10-10 6500 14700
124 Mourgos Kevin 50 1999-11-16 4800 11300
101 Kochhar Neena 90 1989-09-21 17000 17000
102 De Haan Lex 90 1993-01-13 17000 34000
rows between value_expr1 preceding and value_expr2 preceding
# 当前行的前 2 行和当前行的前 1 行(value_expr1 >= value_expr2)
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between 2 preceding and 1 preceding) rows10
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS10
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900
120 Weiss Matthew 50 1996-07-18 8000 7900
121 Fripp Adam 50 1997-04-10 8200 15900
123 Vollman Shanta 50 1997-10-10 6500 16200
124 Mourgos Kevin 50 1999-11-16 4800 14700
101 Kochhar Neena 90 1989-09-21 17000
102 De Haan Lex 90 1993-01-13 17000 17000
rows between value_expr1 preceding and value_expr2 following
# 当前行的前 1 行和当前行的后 1 行
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between 1 preceding and 1 following) rows11
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS11
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 15900
120 Weiss Matthew 50 1996-07-18 8000 24100
121 Fripp Adam 50 1997-04-10 8200 22700
123 Vollman Shanta 50 1997-10-10 6500 19500
124 Mourgos Kevin 50 1999-11-16 4800 11300
101 Kochhar Neena 90 1989-09-21 17000 34000
102 De Haan Lex 90 1993-01-13 17000 34000
rows between value_expr following and unbounded following
# 当前行的后 1 行和分组最后一行
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between 1 following and unbounded following) rows12
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS12
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 27500
120 Weiss Matthew 50 1996-07-18 8000 19500
121 Fripp Adam 50 1997-04-10 8200 11300
123 Vollman Shanta 50 1997-10-10 6500 4800
124 Mourgos Kevin 50 1999-11-16 4800
101 Kochhar Neena 90 1989-09-21 17000 17000
102 De Haan Lex 90 1993-01-13 17000
rows between value_expr1 following and value_expr2 following
# 当前行的后 1 行和当前行的后 2 行(value_expr1 <= value_expr2)
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date rows between 1 following and 2 following) rows13
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROWS13
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 16200
120 Weiss Matthew 50 1996-07-18 8000 14700
121 Fripp Adam 50 1997-04-10 8200 11300
123 Vollman Shanta 50 1997-10-10 6500 4800
124 Mourgos Kevin 50 1999-11-16 4800
101 Kochhar Neena 90 1989-09-21 17000 17000
102 De Haan Lex 90 1993-01-13 17000
range
range 窗口,相当于给 order_by_clause 中的 expr 加一个 where 限定条件,分组中满足条件:
- 当 order by expr asc 时,where expr between a and b
- 当 order by expr desc 时, where expr between b and a
满足以上条件的所有行构成一个逻辑窗口,其中 a 由分组中第 ra 行的值计算而来,b 由分组中第 rb 行的值计算而来,且 ra <= rb
range 窗口目录树(默认升序排序):
range between unbounded preceding and unbounded following
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date range between unbounded preceding and unbounded following) range01
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE01
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 35400
120 Weiss Matthew 50 1996-07-18 8000 35400
121 Fripp Adam 50 1997-04-10 8200 35400
123 Vollman Shanta 50 1997-10-10 6500 35400
124 Mourgos Kevin 50 1999-11-16 4800 35400
101 Kochhar Neena 90 1989-09-21 17000 34000
102 De Haan Lex 90 1993-01-13 17000 34000
range between unbounded preceding and current row/range unbounded preceding
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date range between unbounded preceding and current row) range02
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE02
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 7900
120 Weiss Matthew 50 1996-07-18 8000 15900
121 Fripp Adam 50 1997-04-10 8200 24100
123 Vollman Shanta 50 1997-10-10 6500 30600
124 Mourgos Kevin 50 1999-11-16 4800 35400
101 Kochhar Neena 90 1989-09-21 17000 17000
102 De Haan Lex 90 1993-01-13 17000 34000
range between unbounded preceding and value_expr preceding
# 该分组的第一行和当前行hire_date-365天
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date range between unbounded preceding and 365 preceding) range03
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE03
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900
120 Weiss Matthew 50 1996-07-18 8000 7900
121 Fripp Adam 50 1997-04-10 8200 7900
123 Vollman Shanta 50 1997-10-10 6500 15900
124 Mourgos Kevin 50 1999-11-16 4800 30600
101 Kochhar Neena 90 1989-09-21 17000
102 De Haan Lex 90 1993-01-13 17000 17000
range between unbounded preceding and value_expr following
# 该分组的第一行和当前行hire_date+365天
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date range between unbounded preceding and 365 following) range04
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE04
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 7900
120 Weiss Matthew 50 1996-07-18 8000 24100
121 Fripp Adam 50 1997-04-10 8200 30600
123 Vollman Shanta 50 1997-10-10 6500 30600
124 Mourgos Kevin 50 1999-11-16 4800 35400
101 Kochhar Neena 90 1989-09-21 17000 17000
102 De Haan Lex 90 1993-01-13 17000 34000
range between current row and unbounded following
5
range between current row and current row/range current row
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date range between current row and current row) range06
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE06
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 7900
120 Weiss Matthew 50 1996-07-18 8000 8000
121 Fripp Adam 50 1997-04-10 8200 8200
123 Vollman Shanta 50 1997-10-10 6500 6500
124 Mourgos Kevin 50 1999-11-16 4800 4800
101 Kochhar Neena 90 1989-09-21 17000 17000
102 De Haan Lex 90 1993-01-13 17000 17000
range between current row and value_expr following
# 该分组当前行和当前行hire_date+365天
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date range between current row and 365 following) range07
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE07
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 7900
120 Weiss Matthew 50 1996-07-18 8000 16200
121 Fripp Adam 50 1997-04-10 8200 14700
123 Vollman Shanta 50 1997-10-10 6500 6500
124 Mourgos Kevin 50 1999-11-16 4800 4800
101 Kochhar Neena 90 1989-09-21 17000 17000
102 De Haan Lex 90 1993-01-13 17000 17000
range between value_expr preceding and unbounded following
# 该分组当前行的值-365天和最后一个值
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date range between 365 preceding and unbounded following) range08
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE08
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 35400
120 Weiss Matthew 50 1996-07-18 8000 27500
121 Fripp Adam 50 1997-04-10 8200 27500
123 Vollman Shanta 50 1997-10-10 6500 19500
124 Mourgos Kevin 50 1999-11-16 4800 4800
101 Kochhar Neena 90 1989-09-21 17000 34000
102 De Haan Lex 90 1993-01-13 17000 17000
range between value_expr preceding and current row/range value_expr preceding
# 该分组当前行的值-365天和当前行的值
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date range between 365 preceding and current row) range09
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE09
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 7900
120 Weiss Matthew 50 1996-07-18 8000 8000
121 Fripp Adam 50 1997-04-10 8200 16200
123 Vollman Shanta 50 1997-10-10 6500 14700
124 Mourgos Kevin 50 1999-11-16 4800 4800
101 Kochhar Neena 90 1989-09-21 17000 17000
102 De Haan Lex 90 1993-01-13 17000 17000
range between value_expr1 preceding and value_expr2 preceding
# 该分组当前行的值-365天和当前行的值-30天(value_expr1 >= value_expr2)
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date
range between 365 preceding and 30 preceding) range10
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE10
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900
120 Weiss Matthew 50 1996-07-18 8000
121 Fripp Adam 50 1997-04-10 8200 8000
123 Vollman Shanta 50 1997-10-10 6500 8200
124 Mourgos Kevin 50 1999-11-16 4800
101 Kochhar Neena 90 1989-09-21 17000
102 De Haan Lex 90 1993-01-13 17000
range between value_expr1 preceding and value_expr2 following
# 该分组当前行的值hire_date-365天和当前行的值hire_date+365天
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date range between 365 preceding and 365 following) range11
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE11
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 7900
120 Weiss Matthew 50 1996-07-18 8000 16200
121 Fripp Adam 50 1997-04-10 8200 22700
123 Vollman Shanta 50 1997-10-10 6500 14700
124 Mourgos Kevin 50 1999-11-16 4800 4800
101 Kochhar Neena 90 1989-09-21 17000 17000
102 De Haan Lex 90 1993-01-13 17000 17000
range between value_expr following and unbounded following
# 该分组当前行的值hire_date+365天和最后一个值
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date range between 365 following and unbounded following) range12
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE12
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900 27500
120 Weiss Matthew 50 1996-07-18 8000 11300
121 Fripp Adam 50 1997-04-10 8200 4800
123 Vollman Shanta 50 1997-10-10 6500 4800
124 Mourgos Kevin 50 1999-11-16 4800
101 Kochhar Neena 90 1989-09-21 17000 17000
102 De Haan Lex 90 1993-01-13 17000
range between value_expr1 following and value_expr2 following
# 该分组当前行的值hire_date+30天和当前行的值hire_date+365天
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by t.hire_date range between 30 following and 365 following) range13
from EMPLOYEE t
where t.dept_id in (50, 90);
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANGE13
---------- --------------- ---------- ---------- ---------- ----------
122 Kaufling Payam 50 1995-05-01 7900
120 Weiss Matthew 50 1996-07-18 8000 8200
121 Fripp Adam 50 1997-04-10 8200 6500
123 Vollman Shanta 50 1997-10-10 6500
124 Mourgos Kevin 50 1999-11-16 4800
101 Kochhar Neena 90 1989-09-21 17000
102 De Haan Lex 90 1993-01-13 17000
数据准备
# employee.sql DROP TABLE EMPLOYEE PURGE; CREATE TABLE employee ( EMP_ID NUMBER CONSTRAINT PK_EMPLOYEE PRIMARY KEY, EMP_NAME VARCHAR2(20) NOT NULL, DEPT_ID NUMBER NOT NULL, HIRE_DATE DATE, SALARY NUMBER ); ALTER SESSION SET nls_date_format='YYYY-MM-DD'; INSERT INTO employee VALUES (100,'Wang John',10,'1990-01-01',20000); INSERT INTO employee VALUES (101,'Kochhar Neena',90,'1989-09-21',17000); INSERT INTO employee VALUES (102,'De Haan Lex',90,'1993-01-13',17000); INSERT INTO employee VALUES (103,'Hunold Alexander',60,'1990-01-03',9000); INSERT INTO employee VALUES (104,'Ernst Bruce',60,'1991-05-21',6000); INSERT INTO employee VALUES (105,'Austin David',60,'1997-06-25',4800); INSERT INTO employee VALUES (106,'Pataballa',60,'1998-02-05',4800); INSERT INTO employee VALUES (107,'Lorentz Diana',60,'1999-02-07',4200); INSERT INTO employee VALUES (108,'Greenberg Nancy',100,'1994-08-17',12000); INSERT INTO employee VALUES (109,'Faviet Daniel',100,'1994-08-16',9000); INSERT INTO employee VALUES (110,'Chen John',100,'1997-09-28',8200); INSERT INTO employee VALUES (111,'Sciarra Ismael',100,'1997-09-30',7700); INSERT INTO employee VALUES (112,'Urman Jose Manuel',100,'1998-03-07',7800); INSERT INTO employee VALUES (113,'Popp Luis',100,'1999-12-07',6900); INSERT INTO employee VALUES (114,'Raphaely Den',30,'1994-12-07',11000); INSERT INTO employee VALUES (120,'Weiss Matthew',50,'1996-07-18',8000); INSERT INTO employee VALUES (121,'Fripp Adam',50,'1997-04-10',8200); INSERT INTO employee VALUES (122,'Kaufling Payam',50,'1995-05-01',7900); INSERT INTO employee VALUES (123,'Vollman Shanta',50,'1997-10-10',6500); INSERT INTO employee VALUES (124,'Mourgos Kevin',50,'1999-11-16',4800); INSERT INTO employee VALUES (145,'Russell John',80,'1996-10-01',14000); INSERT INTO employee VALUES (146,'Russell John',80,'1997-01-05',13500); INSERT INTO employee VALUES (147,'Russell John',80,'1997-03-10',12000); INSERT INTO employee VALUES (148,'Russell John',80,'1999-10-15',11000); INSERT INTO employee VALUES (149,'Russell John',80,'2000-01-19',10500); COMMIT;
# sales.sql
DROP TABLE sales PURGE;
CREATE TABLE sales
(
country varchar2(5),
sales_month date,
sales_number integer,
sales_value number(8,0)
);
ALTER SESSION SET nls_date_format='YYYY-MM-DD';
insert into sales values ('USA','2008-1-1',1200,'500000.00');
insert into sales values ('USA','2008-2-1',1150,'450000.00');
insert into sales values ('USA','2008-3-1',1300,'520000.00');
insert into sales values ('USA','2008-4-1',1280,'510000.00');
insert into sales values ('USA','2008-5-1',1350,'530000.00');
insert into sales values ('USA','2008-6-1',1400,'535000.00');
insert into sales values ('USA','2008-7-1',1300,'510000.00');
insert into sales values ('USA','2008-8-1',1250,'460000.00');
insert into sales values ('USA','2008-9-1',1400,'530000.00');
insert into sales values ('USA','2008-10-1',1380,'520000.00');
insert into sales values ('USA','2008-11-1',1450,'540000.00');
insert into sales values ('USA','2008-12-1',1500,'545000.00');
insert into sales values ('USA','2009-1-1',1600,'550000.00');
insert into sales values ('USA','2009-2-1',1390,'532000.00');
insert into sales values ('USA','2009-3-1',1730,'570000.00');
insert into sales values ('USA','2009-4-1',1900,'600000.00');
insert into sales values ('USA','2009-5-1',1850,'585000.00');
insert into sales values ('USA','2009-6-1',3800,'780000.00');
insert into sales values ('USA','2009-7-1',1700,'560000.00');
insert into sales values ('USA','2009-8-1',1490,'542000.00');
insert into sales values ('USA','2009-9-1',1830,'580000.00');
insert into sales values ('USA','2009-10-1',2000,'610000.00');
insert into sales values ('USA','2009-11-1',1950,'595000.00');
insert into sales values ('USA','2009-12-1',1900,'590000.00');
commit;
函数用法
常规统计函数
- MAX
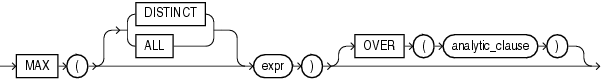
# 获取每个部门中工资最高的员工
select * from (
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
max(t.salary) over(partition by t.dept_id) max_sal
from employee t
) where salary = max_sal order by dept_id, emp_id;
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY MAX_SAL
--------- -------------------- ---------- ---------- ---------- ----------
100 Wang John 10 1990-01-01 20000 20000
114 Raphaely Den 30 1994-12-07 11000 11000
121 Fripp Adam 50 1997-04-10 8200 8200
103 Hunold Alexander 60 1990-01-03 9000 9000
145 Russell John 80 1996-10-01 14000 14000
101 Kochhar Neena 90 1989-09-21 17000 17000
102 De Haan Lex 90 1993-01-13 17000 17000
108 Greenberg Nancy 100 1994-08-17 12000 12000
- MIN

# 分析函数中使用 ORDER BY 子句
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
min(t.salary) over(partition by t.dept_id order by t.hire_date) min_sal
from employee t order by t.dept_id, t.hire_date;
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY MIN_SAL
---------- -------------------- ---------- ---------- ---------- ----------
100 Wang John 10 1990-01-01 20000 20000
114 Raphaely Den 30 1994-12-07 11000 11000
122 Kaufling Payam 50 1995-05-01 7900 7900
120 Weiss Matthew 50 1996-07-18 8000 7900
121 Fripp Adam 50 1997-04-10 8200 7900
123 Vollman Shanta 50 1997-10-10 6500 6500
124 Mourgos Kevin 50 1999-11-16 4800 4800
103 Hunold Alexander 60 1990-01-03 9000 9000
104 Ernst Bruce 60 1991-05-21 6000 6000
105 Austin David 60 1997-06-25 4800 4800
106 Pataballa 60 1998-02-05 4800 4800
107 Lorentz Diana 60 1999-02-07 4200 4200
# 分析函数中不使用 ORDER BY 子句
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
min(t.salary) over(partition by t.dept_id) min_sal
from employee t order by t.dept_id, t.hire_date;
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY MIN_SAL
---------- -------------------- ---------- ---------- ---------- ----------
100 Wang John 10 1990-01-01 20000 20000
114 Raphaely Den 30 1994-12-07 11000 11000
122 Kaufling Payam 50 1995-05-01 7900 4800
120 Weiss Matthew 50 1996-07-18 8000 4800
121 Fripp Adam 50 1997-04-10 8200 4800
123 Vollman Shanta 50 1997-10-10 6500 4800
124 Mourgos Kevin 50 1999-11-16 4800 4800
103 Hunold Alexander 60 1990-01-03 9000 4200
104 Ernst Bruce 60 1991-05-21 6000 4200
105 Austin David 60 1997-06-25 4800 4200
106 Pataballa 60 1998-02-05 4800 4200
107 Lorentz Diana 60 1999-02-07 4200 4200
差异原因: 1. 不使用 ORDER BY 子句,默认窗口为该分组的第一行和该分组的最后一行,所以 MIN(salary) 会等于分组中的最小值; 2. 使用 ORDER BY 子句,会根据 hire_date 排序,然后获取小于等于当前行的 hire_date 的所有 salary,然后再取出其中的 min(salary)。
- AVG
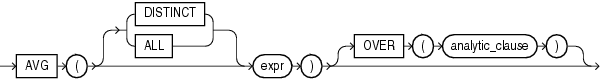
# 获取部门平均薪水
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
avg(t.salary) over(partition by t.dept_id) avg_sal
from employee t order by t.dept_id;
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY AVG_SAL
---------- -------------------- ---------- ---------- ---------- ----------
100 Wang John 10 1990-01-01 20000 20000
114 Raphaely Den 30 1994-12-07 11000 11000
121 Fripp Adam 50 1997-04-10 8200 7080
122 Kaufling Payam 50 1995-05-01 7900 7080
124 Mourgos Kevin 50 1999-11-16 4800 7080
120 Weiss Matthew 50 1996-07-18 8000 7080
123 Vollman Shanta 50 1997-10-10 6500 7080
107 Lorentz Diana 60 1999-02-07 4200 5760
106 Pataballa 60 1998-02-05 4800 5760
103 Hunold Alexander 60 1990-01-03 9000 5760
104 Ernst Bruce 60 1991-05-21 6000 5760
105 Austin David 60 1997-06-25 4800 5760
- SUM
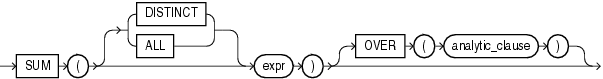
# 获取分组内的薪水和(窗口范围为该分区的第一行和当前行)
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
sum(t.salary) over(partition by t.dept_id order by salary
range between unbounded preceding and current row) sum_sal
from employee t order by t.dept_id, t.salary;
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY SUM_SAL
---------- -------------------- ---------- ---------- ---------- ----------
100 Wang John 10 1990-01-01 20000 20000
114 Raphaely Den 30 1994-12-07 11000 11000
124 Mourgos Kevin 50 1999-11-16 4800 4800
123 Vollman Shanta 50 1997-10-10 6500 11300
122 Kaufling Payam 50 1995-05-01 7900 19200
120 Weiss Matthew 50 1996-07-18 8000 27200
121 Fripp Adam 50 1997-04-10 8200 35400
107 Lorentz Diana 60 1999-02-07 4200 4200
106 Pataballa 60 1998-02-05 4800 13800
105 Austin David 60 1997-06-25 4800 13800
104 Ernst Bruce 60 1991-05-21 6000 19800
103 Hunold Alexander 60 1990-01-03 9000 28800
- COUNT

# 窗口范围为该分区当前行的 hire_date-365*2 和 当前行的 hire_date+30*2 之间的累计计数
即: 统计当前行2年前至当前行3个月后这段时间内的累计计数。
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
count(*) over(partition by t.dept_id order by t.hire_date
range between 365*2 preceding and 30*3 following) sum_cnt
from employee t order by t.dept_id, t.hire_date;
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY SUM_CNT
---------- -------------------- ---------- ---------- ---------- ----------
100 Wang John 10 1990-01-01 20000 1
114 Raphaely Den 30 1994-12-07 11000 1
122 Kaufling Payam 50 1995-05-01 7900 1
120 Weiss Matthew 50 1996-07-18 8000 2
121 Fripp Adam 50 1997-04-10 8200 3
123 Vollman Shanta 50 1997-10-10 6500 3
124 Mourgos Kevin 50 1999-11-16 4800 1
103 Hunold Alexander 60 1990-01-03 9000 1
104 Ernst Bruce 60 1991-05-21 6000 2
105 Austin David 60 1997-06-25 4800 1
106 Pataballa 60 1998-02-05 4800 2
107 Lorentz Diana 60 1999-02-07 4200 3
说明:
1. preceding("-")
2. following("+")
如 "107 Lorentz Diana" 统计的就是 "1997-02-07 ~ 1999-05-07" 之间的累计计数。
数据排序函数
- RANK

# 根据 ORDER BY 子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置(排名跳号不连续)
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
rank() over(partition by t.dept_id order by t.salary) rank
from employee t where t.dept_id = 60 order by rank;
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY RANK
---------- -------------------- ---------- ---------- ---------- ----------
107 Lorentz Diana 60 1999-02-07 4200 1
105 Austin David 60 1997-06-25 4800 2
106 Pataballa 60 1998-02-05 4800 2
104 Ernst Bruce 60 1991-05-21 6000 4
103 Hunold Alexander 60 1990-01-03 9000 5
- DENSE_RANK

# 根据 ORDER BY 子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置(排名不跳号连续)
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
dense_rank() over(partition by t.dept_id order by t.salary) dense_rank
from employee t where t.dept_id = 60 order by dense_rank;
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY DENSE_RANK
---------- -------------------- ---------- ---------- ---------- ----------
107 Lorentz Diana 60 1999-02-07 4200 1
105 Austin David 60 1997-06-25 4800 2
106 Pataballa 60 1998-02-05 4800 2
104 Ernst Bruce 60 1991-05-21 6000 3
103 Hunold Alexander 60 1990-01-03 9000 4
- ROW_NUMBER

# 返回有序分组中一行的偏移量
select
t.emp_id, t.emp_name, t.dept_id, t.hire_date, t.salary,
row_number() over(partition by t.dept_id order by t.salary) row_number
from employee t where t.dept_id = 60 order by row_number;
EMP_ID EMP_NAME DEPT_ID HIRE_DATE SALARY ROW_NUMBER
---------- -------------------- ---------- ---------- ---------- ----------
107 Lorentz Diana 60 1999-02-07 4200 1
105 Austin David 60 1997-06-25 4800 2
106 Pataballa 60 1998-02-05 4800 3
104 Ernst Bruce 60 1991-05-21 6000 4
103 Hunold Alexander 60 1990-01-03 9000 5
- FIRST
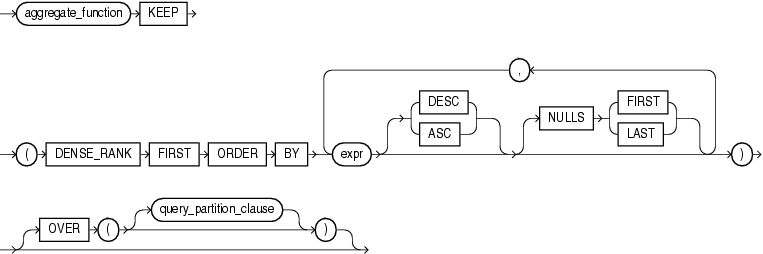
# 从 DENSE_RANK 返回的结果集中取出排在最前面的一个值的行(可能多行,因为值可能相等)
select
t.dept_id,
min(t.salary) keep(dense_rank first order by t.salary) first,
max(t.salary) keep(dense_rank last order by t.salary) last
from employee t group by t.dept_id;
DEPT_ID FIRST LAST
---------- ---------- ----------
10 20000 20000
30 11000 11000
50 4800 8200
60 4200 9000
80 10500 14000
90 17000 17000
- FIRST_VALUE
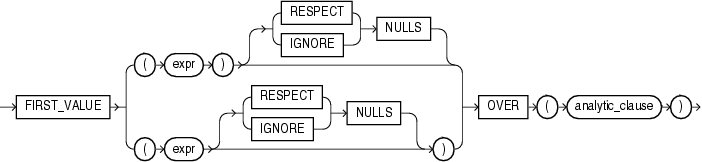
# 返回分组中数据窗口的第一个值
select
t.emp_id, t.emp_name, t.dept_id, t.salary,
first_value(t.salary) over(partition by t.dept_id order by t.salary) first_val,
first_value(t.salary) over(partition by t.dept_id order by t.salary desc) last_val
from employee t;
EMP_ID EMP_NAME DEPT_ID SALARY FIRST_VAL LAST_VAL
---------- -------------------- ---------- ---------- ---------- ----------
100 Wang John 10 20000 20000 20000
114 Raphaely Den 30 11000 11000 11000
124 Mourgos Kevin 50 4800 4800 8200
123 Vollman Shanta 50 6500 4800 8200
122 Kaufling Payam 50 7900 4800 8200
120 Weiss Matthew 50 8000 4800 8200
121 Fripp Adam 50 8200 4800 8200
107 Lorentz Diana 60 4200 4200 9000
105 Austin David 60 4800 4200 9000
106 Pataballa 60 4800 4200 9000
104 Ernst Bruce 60 6000 4200 9000
103 Hunold Alexander 60 9000 4200 9000
- LAST
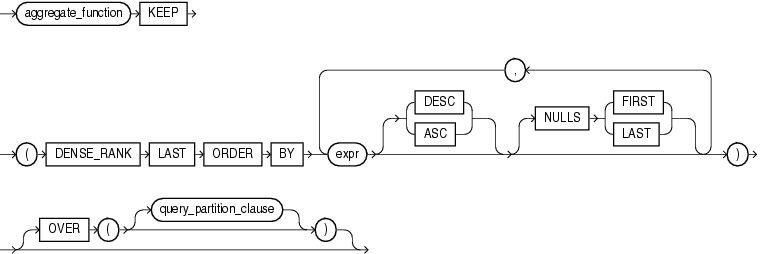
# 从 DENSE_RANK 返回的结果集中取出排在最后面的一个值的行(可能多行,因为值可能相等)
- LAST_VALUE
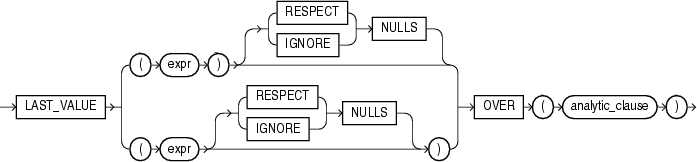
# 返回分组中数据窗口的最后个值
- LAG
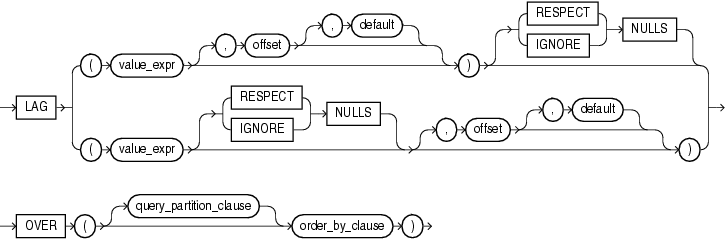
# 在给定的分组中可以访问当前行之前的行,默认偏移量为1
select
t.emp_id, t.salary, t.hire_date,
lag(salary, 1, 0) over(order by t.hire_date) prev_lag,
lag(salary, 2, -1) over(order by t.hire_date) prev_lag2
from employee t where t.dept_id = 60
order by t.hire_date;
EMP_ID SALARY HIRE_DATE PREV_LAG PREV_LAG2
---------- ---------- ---------- ---------- ----------
103 9000 1990-01-03 0 -1
104 6000 1991-05-21 9000 -1
105 4800 1997-06-25 6000 9000
106 4800 1998-02-05 4800 6000
107 4200 1999-02-07 4800 4800
- LEAD
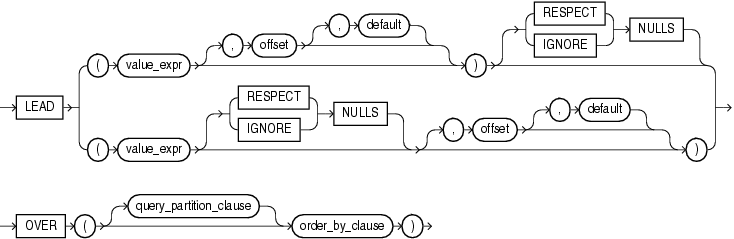
# 在给定的分组中可以访问当前行之后的行,默认偏移量为1
select
t.emp_id, t.salary, t.hire_date,
lead(salary, 1, 0) over(order by t.hire_date) next_lead
from employee t where t.dept_id = 60
order by t.hire_date;
EMP_ID SALARY HIRE_DATE NEXT_LEAD
---------- ---------- ---------- ----------
103 9000 1990-01-03 6000
104 6000 1991-05-21 4800
105 4800 1997-06-25 4800
106 4800 1998-02-05 4200
107 4200 1999-02-07 0
数据分布函数
- NTILE

# 将一个分组分为 "表达式" 的散列显示。例如表达式为=4,则给分组中的每一行分配一个数(1~4),如果分组中有20行,则给前5行分配1,给下5行分配2等
select
t.emp_id, t.emp_name, t.dept_id, t.salary,
ntile(4) over(partition by t.dept_id order by t.salary) quartile
from employee t where t.dept_id in (60, 100)
order by t.dept_id, t.salary, quartile;
EMP_ID EMP_NAME DEPT_ID SALARY QUARTILE
---------- -------------------- ---------- ---------- ----------
107 Lorentz Diana 60 4200 1
105 Austin David 60 4800 1
106 Pataballa 60 4800 2
104 Ernst Bruce 60 6000 3
103 Hunold Alexander 60 9000 4
113 Popp Luis 100 6900 1
111 Sciarra Ismael 100 7700 1
112 Urman Jose Manuel 100 7800 2
110 Chen John 100 8200 2
109 Faviet Daniel 100 9000 3
108 Greenberg Nancy 100 12000 4
说明:
1. 将数据分为部门60和部门100两个分组,部门60有5条数据,因此将另外一个值(5/4余数)分配给 "buckets 1";
部门100有6条数据,因此将另外两个值(6/4余数)分配给 "buckets 1" 和 "buckets 2"。
- CUME_DIST

# 计算一行在分组中的相对位置,CUME_DIST 返回的值范围是>0到<=1
select
t.emp_id, t.emp_name, t.dept_id, t.salary,
cume_dist() over(partition by t.dept_id order by t.salary) cume_dist
from employee t where t.dept_id = 50
order by t.salary;
EMP_ID EMP_NAME DEPT_ID SALARY CUME_DIST
---------- -------------------- ---------- ---------- ----------
124 Mourgos Kevin 50 4800 .2
123 Vollman Shanta 50 6500 .4
122 Kaufling Payam 50 7900 .6
120 Weiss Matthew 50 8000 .8
121 Fripp Adam 50 8200 1
select t.emp_id, t.emp_name, t.dept_id, t.salary
from employee t where t.dept_id = 50 order by t.salary;
EMP_ID EMP_NAME DEPT_ID SALARY
---------- -------------------- ---------- ----------
124 Mourgos Kevin 50 4800
123 Vollman Shanta 50 6500
122 Kaufling Payam 50 7900
120 Weiss Matthew 50 8000
121 Fripp Adam 50 8200
说明:
以 "123 Vollman Shanta" 为例,部门50的员工,有40%的工资低于或等于 Vollman Shanta(含自己)的工资。
- PERCENT_RANK

# 对于一个给定的分组来说,在计算那行的序号时,先减1,然后除以n-1(n为分组中所有的行数),该函数总是返回0~1(包括1)之间的数
select
t.emp_id, t.emp_name, t.dept_id, t.salary,
percent_rank() over(partition by t.dept_id order by t.salary) pr
from employee t where t.dept_id in (10, 50)
order by t.dept_id, pr, t.salary;
EMP_ID EMP_NAME DEPT_ID SALARY PR
---------- -------------------- ---------- ---------- ----------
100 Wang John 10 20000 0
124 Mourgos Kevin 50 4800 0
123 Vollman Shanta 50 6500 .25
122 Kaufling Payam 50 7900 .5
120 Weiss Matthew 50 8000 .75
121 Fripp Adam 50 8200 1
说明:
计算每个员工在部门内的工资等级百分比。
- PERCENTILE_CONT

# 返回一个与输入的分布百分比相对应的数据值,根据 PERCENT_RANK 可以获的分布百分比
select
t.emp_id, t.emp_name, t.dept_id, t.salary,
percent_rank() over(partition by t.dept_id order by t.salary) pr,
percentile_cont(0.5) within group (order by t.salary) over(partition by t.dept_id) pd
from employee t where t.dept_id = 50
order by t.dept_id, pr, t.salary;
EMP_ID EMP_NAME DEPT_ID SALARY PR PD
---------- -------------------- ---------- ---------- ---------- ----------
124 Mourgos Kevin 50 4800 0 7900
123 Vollman Shanta 50 6500 .25 7900
122 Kaufling Payam 50 7900 .5 7900
120 Weiss Matthew 50 8000 .75 7900
121 Fripp Adam 50 8200 1 7900
- PERCENTILE_DISC

# 返回一个与输入的分布百分比值相对应的数据值,根据 CUME_DIST 可以获取分布百分比,如果找不到就取大于该分布值的下一个值
select
t.emp_id, t.dept_id, t.salary,
cume_dist() over(partition by t.dept_id order by t.salary) cd,
percentile_disc(0.6) within group (order by t.salary) over(partition by t.dept_id) pd,
percentile_disc(0.1) within group (order by t.salary) over(partition by t.dept_id) pd2
from employee t where t.dept_id = 50
order by t.dept_id, pd, t.salary;
EMP_ID DEPT_ID SALARY CD PD PD2
---------- ---------- ---------- ---------- ---------- ----------
124 50 4800 .2 7900 4800
123 50 6500 .4 7900 4800
122 50 7900 .6 7900 4800
120 50 8000 .8 7900 4800
121 50 8200 1 7900 4800
说明:
1. 找到0.6这个分布值,则取值
2. 找不到0.1这个分布在,则取大于分布值的下一个值(0.2)
- RATIO_TO_REPORT

# 该函数计算 expression/(sum(expression)) 的值,它给出相对于总数的百分比
select * from (
select
t.emp_id, t.dept_id, t.salary,
sum(salary) over() sum_sal,
sum(salary) over(partition by t.dept_id) sum_d_sal,
round(ratio_to_report(salary) over(), 4) rtr,
round(ratio_to_report(salary) over(partition by t.dept_id), 4) rtr2
from employee t
) where dept_id = 60 order by salary;
EMP_ID DEPT_ID SALARY SUM_SAL SUM_D_SAL RTR RTR2
---------- ---------- ---------- ---------- ---------- ---------- ----------
107 60 4200 241800 28800 .0174 .1458
106 60 4800 241800 28800 .0199 .1667
105 60 4800 241800 28800 .0199 .1667
104 60 6000 241800 28800 .0248 .2083
103 60 9000 241800 28800 .0372 .3125
说明:
1. 计算部门60下每个员工的工资占所有员工工资总额的百分比;
2. 计算部门60下每个员工的工资占部门员工工资总额的百分比。
- REGR_ (Linear Regression) Functions
REGR_ (Linear Regression) Functions 这些线性回归函数适合最小二乘法回归线,有9个不同的函数可使用
统计分析函数
- CORR

# 返回一对表达式的相关系数,通过返回-1~1之间的一个数,相关系数给出了关联的强度,0表示不相关
SELECT
t.emp_id, t.dept_id,
TO_CHAR((SYSDATE - hire_date) YEAR TO MONTH ) "Yrs-Mns",
t.salary,
CORR(SYSDATE-hire_date, salary) OVER(PARTITION BY t.dept_id) Correlation
FROM employee t
WHERE t.dept_id in (50, 80)
ORDER BY t.dept_id, t.emp_id;
EMP_ID DEPT_ID Yrs-Mns SALARY CORRELATION
---------- ---------- ------- ---------- -----------
120 50 +22-01 8000 .876156086
121 50 +21-04 8200 .876156086
122 50 +23-03 7900 .876156086
123 50 +20-10 6500 .876156086
124 50 +18-09 4800 .876156086
145 80 +21-10 14000 .912198993
146 80 +21-07 13500 .912198993
147 80 +21-05 12000 .912198993
148 80 +18-10 11000 .912198993
149 80 +18-07 10500 .912198993
说明:
结果集展示了员工在公司工作的时间长短和员工所属部门的薪水之间的相关关系。
- COVAR_POP
# 返回一对表达式的总体协方差,用于表示的是两个变量的总体的误差
select
p.product_id, p.supplier_id,
round(covar_pop(p.list_price, p.min_price) over(order by p.product_id, p.supplier_id), 4) covar_pop
from oe.product_information p where p.category_id = 29
order by p.product_id, p.supplier_id;
PRODUCT_ID SUPPLIER_ID COVAR_POP
---------- ----------- ----------
1774 103088 0
1775 103087 1473.25
1794 103096 1702.7778
1825 103093 1926.25
2004 103086 1591.4
2005 103086 1512.5
2416 103088 1475.9796
2417 103088 1478.7031
2449 103088 1326.8642
3101 103086 1195.2
3170 103089 1590.0744
3171 103089 1718.25
- COVAR_SAMP
# 返回一对表达式的样本协方差,用于表示的是两个变量的总体的误差
select
p.product_id, p.supplier_id,
round(covar_samp(p.list_price, p.min_price) over(order by p.product_id, p.supplier_id), 4) covar_samp
from oe.product_information p where p.category_id = 29
order by p.product_id, p.supplier_id;
PRODUCT_ID SUPPLIER_ID COVAR_SAMP
---------- ----------- ----------
1774 103088
1775 103087 2946.5
1794 103096 2554.1667
1825 103093 2568.3333
2004 103086 1989.25
2005 103086 1815
2416 103088 1721.9762
2417 103088 1689.9464
2449 103088 1492.7222
3101 103086 1328
3170 103089 1749.0818
3171 103089 1874.4545
- STDDEV

# 计算当前行关于分组的标准偏离(标准差) select t.last_name, t.salary, round(stddev(t.salary) over (order by t.hire_date), 4) StdDev from hr.employees t where t.department_id = 30 order by t.last_name, t.salary, StdDev; LAST_NAME SALARY STDDEV ------------ ---------- ---------- Baida 2900 4035.2612 Colmenares 2500 3362.5883 Himuro 2600 3649.2465 Khoo 3100 5586.1436 Raphaely 11000 0 Tobias 2800 4650.0896
- STDDEV_POP

# 该函数计算累积总体标准偏离,并返回总体变量的平方根,其返回值与VAR_POP函数的平方根相同
select
t.department_id, t.last_name, t.salary,
stddev_pop(t.salary) over (partition by t.department_id) as pop_std
from hr.employees t
order by t.department_id, t.last_name, t.salary, pop_std;
DEPARTMENT_ID LAST_NAME SALARY POP_STD
------------- ------------ ---------- ----------
10 Whalen 4400 0
20 Fay 6000 3500
20 Hartstein 13000 3500
30 Baida 2900 3069.6091
30 Colmenares 2500 3069.6091
30 Himuro 2600 3069.6091
30 Khoo 3100 3069.6091
30 Raphaely 11000 3069.6091
30 Tobias 2800 3069.6091
40 Mavris 6500 0
说明:
返回样本中员工工资的总体标准差。
- STDDEV_SAMP

# 该函数计算累积样本标准偏离,并返回总体变量的平方根,其返回值与VAR_POP函数的平方根相同
select
department_id, last_name, hire_date, salary,
stddev_samp(salary) over (partition by department_id order by hire_date
rows between unbounded preceding and current row) as cum_sdev
from hr.employees
order by department_id, last_name, hire_date, salary, cum_sdev;
DEPARTMENT_ID LAST_NAME HIRE_DATE SALARY CUM_SDEV
------------- ------------ ---------- ---------- ----------
10 Whalen 2003-09-17 4400
20 Fay 2005-08-17 6000 4949.74747
20 Hartstein 2004-02-17 13000
30 Baida 2005-12-24 2900 4035.26125
30 Colmenares 2007-08-10 2500 3362.58829
30 Himuro 2006-11-15 2600 3649.2465
30 Khoo 2003-05-18 3100 5586.14357
30 Raphaely 2002-12-07 11000
30 Tobias 2005-07-24 2800 4650.0896
40 Mavris 2002-06-07 6500
说明:
返回员工表中工资的样本标准差。
- VAR_POP

# 该函数返回非空集合的总体方差(忽略null) SUM((expr - (SUM(expr) / COUNT(expr)))2) / COUNT(expr) select t.calendar_month_desc, var_pop(sum(s.amount_sold)) over (order by t.calendar_month_desc) var_pop from sh.sales s, sh.times t where s.time_id = t.time_id and t.calendar_year = 1998 group by t.calendar_month_desc order by t.calendar_month_desc, var_pop; CALENDAR VAR_POP -------- ---------- 1998-01 0 1998-02 2269111326 1998-03 5.5849E+10 1998-04 4.8252E+10 1998-05 6.0020E+10 1998-06 5.4091E+10 1998-07 4.7150E+10 说明: 计算1998年月销售额的累积总体方差。
- VAR_SAMP

# 该函数返回非空集合的样本方差(忽略null) (SUM(expr - (SUM(expr) / COUNT(expr)))2) / (COUNT(expr) - 1) select t.calendar_month_desc, var_samp(sum(s.amount_sold)) over (order by t.calendar_month_desc) var_samp from sh.sales s, sh.times t where s.time_id = t.time_id and t.calendar_year = 1998 group by t.calendar_month_desc order by t.calendar_month_desc, var_samp; CALENDAR VAR_SAMP -------- ---------- 1998-01 1998-02 4538222653 1998-03 8.3774E+10 1998-04 6.4336E+10 1998-05 7.5025E+10 1998-06 6.4909E+10 1998-07 5.5009E+10 说明: 计算1998年月销售额的样本方差。
- VARIANCE
# 该函数返回表达式的变量,如果表达式中行数为1,则返回0,如果表达式中行数大于1,则返回 VAR_SAMP select last_name, salary, round(variance(salary) over (order by hire_date), 4) variance from hr.employees where department_id = 30 order by last_name, salary, variance; LAST_NAME SALARY VARIANCE ------------ ---------- ---------- Baida 2900 16283333.3 Colmenares 2500 11307000 Himuro 2600 13317000 Khoo 3100 31205000 Raphaely 11000 0 Tobias 2800 21623333.3 说明: 返回按雇佣日期排序的部门30的员工工资的累积方差。
其它函数
- LISTAGG

# 在每个分组内,LISTAGG 根据 order by 子句对列值进行排序,将排序后的结果拼接起来(多行合并一行)
select
department_id dept_id, hire_date, last_name,
listagg(last_name, '; ') within group (order by hire_date, last_name)
over (partition by department_id) Emp_list
from hr.employees
where hire_date < '2003-09-01'
order by 1, 2, 3;
DEPT_ID HIRE_DATE LAST_NAME EMP_LIST
---------- ---------- --------------- --------------------
30 2002-12-07 Raphaely Raphaely; Khoo
30 2003-05-18 Khoo Raphaely; Khoo
40 2002-06-07 Mavris Mavris
50 2003-05-01 Kaufling Kaufling; Ladwig
50 2003-07-14 Ladwig Kaufling; Ladwig
70 2002-06-07 Baer Baer
90 2001-01-13 De Haan De Haan; King
90 2003-06-17 King De Haan; King
100 2002-08-16 Faviet Faviet; Greenberg
100 2002-08-17 Greenberg Faviet; Greenberg
110 2002-06-07 Gietz Gietz; Higgins
110 2002-06-07 Higgins Gietz; Higgins
说明:
按部门分组, 找出 hire_date < '2003-09-01' 的所有员工,并将其 last_name 拼接起来。
- MEDIAN

# 获取一个数值或日期时间值,并返回中间值或一个内插值,该值在值排序后将成为中间值(忽略null)
select
t.emp_id, t.dept_id, salary,
median(t.salary) over (partition by t.dept_id) "Median by Dept"
from employee t
where t.dept_id > 60
order by t.dept_id, t.salary;
EMP_ID DEPT_ID SALARY Median by Dept
---------- ---------- ---------- --------------
149 80 10500 12000
148 80 11000 12000
147 80 12000 12000
146 80 13500 12000
145 80 14000 12000
101 90 17000 17000
102 90 17000 17000
113 100 6900 8000
111 100 7700 8000
112 100 7800 8000
110 100 8200 8000
109 100 9000 8000
108 100 12000 8000
说明:
查询结果返回部门中的每个员工的工资中值。
1. 部门80有奇数个员工,所以根据salary排序后,中值=(n/2+1)的数值
2. 部门100有偶数个员工,所以根据salary排序后,中值=((n/2的数值)+(n/2+1的数值))/2
- NTH_VALUE

# 获取排序后结果集中任意一行,根据偏移量获取,而不会仅仅第一行或最后一行
select
t.emp_id, t.dept_id, t.salary,
nth_value(t.salary, 1) over() "first",
nth_value(t.salary, 5) from first over() "fifth",
nth_value(t.salary, 2) from last over() "second_desc"
from employee t where t.dept_id in (50, 60)
order by t.salary;
EMP_ID DEPT_ID SALARY first fifth second_desc
---------- ---------- ---------- ---------- ---------- -----------
107 60 4200 4200 6000 8200
105 60 4800 4200 6000 8200
106 60 4800 4200 6000 8200
124 50 4800 4200 6000 8200
104 60 6000 4200 6000 8200
123 50 6500 4200 6000 8200
122 50 7900 4200 6000 8200
120 50 8000 4200 6000 8200
121 50 8200 4200 6000 8200
103 60 9000 4200 6000 8200
说明(未分组):
1. NTH_VALUE 中的第二个参数是指这个函数取排名第几的记录
2. from first 表示从排名第一往后取(如第五)
3. from last 表示从排名最末往前取(如倒数第二)
# 分组
select
t.emp_id, t.dept_id, t.salary,
nth_value(t.salary, 1) over(partition by t.dept_id) "first",
nth_value(t.salary, 5) from first over(partition by t.dept_id) "fifth",
nth_value(t.salary, 2) from last over(partition by t.dept_id) "second_desc"
from employee t where t.dept_id in (50, 60)
order by t.dept_id, t.salary;
EMP_ID DEPT_ID SALARY first fifth second_desc
---------- ---------- ---------- ---------- ---------- -----------
124 50 4800 4800 8200 8000
123 50 6500 4800 8200 8000
122 50 7900 4800 8200 8000
120 50 8000 4800 8200 8000
121 50 8200 4800 8200 8000
107 60 4200 4200 9000 6000
105 60 4800 4200 9000 6000
106 60 4800 4200 9000 6000
104 60 6000 4200 9000 6000
103 60 9000 4200 9000 6000
分析函数应用
目录
| 序号 | 应用分类 | 明细分类 |
| 1 | 现状分析 | 众数分析 |
| 2 | 80/20 分析 | |
| 3 | 比重分析 | |
| 5 | 离散趋势分析 | |
| 6 | TOPN 分析 | |
| 7 | 强度分析 | |
| 8 | 发展分析 | 环比分析 |
| 9 | 同比分析 | |
| 10 | 基比分析 |
现状分析
- 众数分析
众数是一组数据中出现次数最多的数值,在统计分布上具有明显集中趋势点的数值,代表数据的一般水平
select
salary
from (
select
salary,
rank() over(order by repeat_num desc) rk_repeat_num
from (
select
t.salary, count(*) repeat_num
from employee t group by t.salary
)
) where rk_repeat_num = 1;
SALARY
----------
4800
- 80/20 分析
80/20集合分析源自于帕累托二八定律,也就是80/20法则
select
ename, sal, deptno, sal_ratio, commu_ratio,
case when commu_ratio >= 0.8 then 0 else 1 end as "80/20分析"
from (
select
ename, sal, deptno, sal_ratio,
sum(sal_ratio) over(order by sal_ratio desc) commu_ratio
from (
select
t.ename, t.sal, t.deptno,
ratio_to_report(t.sal) over() sal_ratio
from scott.emp t
)
);
ENAME SAL DEPTNO SAL_RATIO COMMU_RATIO 80/20分析
---------- ---------- ---------- ---------- ----------- ----------
KING 5000 10 .172265289 .172265289 1
FORD 3000 20 .103359173 .378983635 1
SCOTT 3000 20 .103359173 .378983635 1
JONES 2975 20 .102497847 .481481481 1
BLAKE 2850 30 .098191214 .579672696 1
CLARK 2450 10 .084409991 .664082687 1
ALLEN 1600 30 .055124892 .71920758 1
TURNER 1500 30 .051679587 .770887166 1
MILLER 1300 10 .044788975 .815676141 0
WARD 1250 30 .043066322 .901808786 0
MARTIN 1250 30 .043066322 .901808786 0
ADAMS 1100 20 .037898363 .939707149 0
JAMES 950 30 .032730405 .972437554 0
SMITH 800 20 .027562446 1 0
说明:
结果集中 "80/20分析=1" 字段反映了,80%的薪水是由他们构成的。
- 比重分析
比重分析主要用于分析业务整体中各要素在整体中所占的比重,并对这些比重进行排序,`便于决策者了解业务的整体结构
select
t.emp_id, t.dept_id, t.hire_date, t.salary,
ratio_to_report(t.salary) over() sal_ratio,
row_number() over(order by t.salary desc) row_num
from employee t;
EMP_ID DEPT_ID HIRE_DATE SALARY SAL_RATIO ROW_NUM
---------- ---------- ---------- ---------- ---------- ----------
100 10 1990-01-01 20000 .082712986 1
101 90 1989-09-21 17000 .070306038 2
102 90 1993-01-13 17000 .070306038 3
145 80 1996-10-01 14000 .05789909 4
146 80 1997-01-05 13500 .055831266 5
147 80 1997-03-10 12000 .049627792 6
108 100 1994-08-17 12000 .049627792 7
148 80 1999-10-15 11000 .045492142 8
114 30 1994-12-07 11000 .045492142 9
149 80 2000-01-19 10500 .043424318 10
- 离散趋势分析
离散趋势分析主要是进行标准差系数(变异系数)的分析,离散分析的主要作用在于分析样本指标的离散程度
在统计学中,我们通常是用标准差系数来体现指标样本的波动情况,标准差系数越大,表示平均值数的代表性越小,反之,则代表性越大
select
round(stddev_samp, 4) AS "标准差",
round(stddev_samp/avg_sales_number, 4) AS "标准差系数",
max_sales_number AS "最大值",
min_sales_number AS "最小值",
max_sales_number-min_sales_number AS "全距",
total_sales_number AS "样本记录数"
from (
select
distinct
stddev_samp(s.sales_number) over() stddev_samp, --累积样本标准偏离
avg(s.sales_number) over() avg_sales_number,
max(s.sales_number) over() max_sales_number,
min(s.sales_number) over() min_sales_number,
count(s.sales_number) over() total_sales_number
from sales s
);
标准差 标准差系数 最大值 最小值 全距 样本记录数
--------- ---------- ---------- ---------- ---------- ----------
530.438 .3256 3800 1150 2650 24
- TOPN 分析
TOPN 分析能快速抽取指标中前N和后N名的数据,满足用户只想看报表中某个指标的最大和最小的几个值的需求
select * from (
select
s.country, s.sales_month, s.sales_value,
row_number() over(order by s.sales_value) row_num
from sales s
) where row_num <= 3 or row_num >= (select count(*) from sales) - 2;
COUNT SALES_MONT SALES_VALUE ROW_NUM
----- ---------- ----------- ----------
USA 2008-02-01 450000 1
USA 2008-08-01 460000 2
USA 2008-01-01 500000 3
USA 2009-04-01 600000 22
USA 2009-10-01 610000 23
USA 2009-06-01 780000 24
- 强度分析
用一行指标数据作为基数,计算其它各个指标与基数的比值,用这个值来反映它们之间的差距
强度分析可以用于在不同时间或地区同类数字之间进行比较,产生比较相对指标,用以揭示不同单位之间的差异
select
emp_id||'--'||first_emp_id,
salary, first_salary,
round(salary/first_salary, 2) salary_diff
from (
select
t.emp_id, t.emp_name, t.dept_id, t.salary,
first_value(t.emp_id) over(order by t.emp_id) first_emp_id, --基数数据
first_value(t.salary) over(order by t.emp_id) first_salary --基数数据
from employee t
);
EMP_ID||'--'||FIRST_EMP_ID SALARY FIRST_SALARY SALARY_DIFF
-------------------------- ---------- ------------ -----------
100--100 20000 20000 1
101--100 17000 20000 .85
102--100 17000 20000 .85
103--100 9000 20000 .45
104--100 6000 20000 .3
105--100 4800 20000 .24
106--100 4800 20000 .24
107--100 4200 20000 .21
108--100 12000 20000 .6
109--100 9000 20000 .45
110--100 8200 20000 .41
说明:
以 "EMP_ID=100" 作为基数,每一个 "EMP_ID"的 "salary" 和它进行对比,得出比值。
发展分析
- 环比分析
环比就是现在的统计周期和上一个统计周期比较,例如,2018年7月份与2018年6月份相比较
select
country,
to_char(sales_month, 'YYYYMM') ||' ~ '|| to_char(add_months(sales_month, -1), 'YYYYMM') "环比周期",
sales_number "当期销售量",
prev_sales_number "环比销售量",
round(sales_number/prev_sales_number, 4) as "环比分析"
from (
select
country, sales_month, sales_number, sales_value,
--获取第一个月日期、第一个月的销售量
first_value(sales_month) over(order by sales_month) first_sales_month,
first_value(sales_number) over(order by sales_month) first_sales_number,
prev_sales_number,
prev12_sales_number
from (
select
s.country, s.sales_month, s.sales_number, s.sales_value,
--获取上个月、上年销售量
lag(s.sales_number, 1, 0) over(order by s.sales_month) prev_sales_number,
lag(s.sales_number, 12, 0) over(order by s.sales_month) prev12_sales_number
from sales s
)
where sales_month >= to_date('2009-01-01', 'YYYY-MM-DD')
);
COUNTRY 环比周期 当期销售量 环比销售量 环比分析
---------- ----------------- ---------- ---------- ----------
USA 200901 ~ 200812 1600 1500 1.0667
USA 200902 ~ 200901 1390 1600 .8688
USA 200903 ~ 200902 1730 1390 1.2446
USA 200904 ~ 200903 1900 1730 1.0983
USA 200905 ~ 200904 1850 1900 .9737
USA 200906 ~ 200905 3800 1850 2.0541
USA 200907 ~ 200906 1700 3800 .4474
USA 200908 ~ 200907 1490 1700 .8765
USA 200909 ~ 200908 1830 1490 1.2282
USA 200910 ~ 200909 2000 1830 1.0929
USA 200911 ~ 200910 1950 2000 .975
USA 200912 ~ 200911 1900 1950 .9744
说明:
以 "200912 ~ 200911" 为例, "200912" 为当前统计周期, "200911" 为上一个统计周期(环比周期)。
- 同比分析
同比就是与历史同期相比,例如,2018年8月份与2017年8月份相比较
select
country,
to_char(sales_month, 'YYYYMM') ||' ~ '|| to_char(add_months(sales_month, -12), 'YYYYMM') "同比周期",
sales_number "当期销售量",
prev12_sales_number "同比销售量",
round(sales_number/prev12_sales_number, 4) as "同比分析"
from (
select
country, sales_month, sales_number, sales_value,
--获取第一个月日期、第一个月的销售量
first_value(sales_month) over(order by sales_month) first_sales_month,
first_value(sales_number) over(order by sales_month) first_sales_number,
prev_sales_number,
prev12_sales_number
from (
select
s.country, s.sales_month, s.sales_number, s.sales_value,
--获取上个月、上年销售量
lag(s.sales_number, 1, 0) over(order by s.sales_month) prev_sales_number,
lag(s.sales_number, 12, 0) over(order by s.sales_month) prev12_sales_number
from sales s
)
where sales_month >= to_date('2009-01-01', 'YYYY-MM-DD')
);
COUNTRY 同比周期 当期销售量 同比销售量 同比分析
---------- --------------- ---------- ---------- ----------
USA 200901 ~ 200801 1600 1200 1.3333
USA 200902 ~ 200802 1390 1150 1.2087
USA 200903 ~ 200803 1730 1300 1.3308
USA 200904 ~ 200804 1900 1280 1.4844
USA 200905 ~ 200805 1850 1350 1.3704
USA 200906 ~ 200806 3800 1400 2.7143
USA 200907 ~ 200807 1700 1300 1.3077
USA 200908 ~ 200808 1490 1250 1.192
USA 200909 ~ 200809 1830 1400 1.3071
USA 200910 ~ 200810 2000 1380 1.4493
USA 200911 ~ 200811 1950 1450 1.3448
USA 200912 ~ 200812 1900 1500 1.2667
- 基比分析(定基比分析)
基比发展速度也叫总速度,是报告期水平与某一个固定时期水平之比,表明这种现象在较长时期内的发展速度
select
country,
to_char(sales_month, 'YYYYMM') ||' ~ '|| to_char(first_sales_month, 'YYYYMM') "基比周期",
sales_number "当期销售量",
first_sales_number "基比初始值",
round(sales_number/first_sales_number, 4) as "基比分析"
from (
select
country, sales_month, sales_number, sales_value,
--获取第一个月日期、第一个月的销售量
first_value(sales_month) over(order by sales_month) first_sales_month,
first_value(sales_number) over(order by sales_month) first_sales_number,
prev_sales_number,
prev12_sales_number
from (
select
s.country, s.sales_month, s.sales_number, s.sales_value,
--获取上个月、上年销售量
lag(s.sales_number, 1, 0) over(order by s.sales_month) prev_sales_number,
lag(s.sales_number, 12, 0) over(order by s.sales_month) prev12_sales_number
from sales s
)
where sales_month >= to_date('2009-01-01', 'YYYY-MM-DD')
);
COUNTRY 基比周期 当期销售量 基比初始值 基比分析
---------- --------------- ---------- ---------- ----------
USA 200901 ~ 200901 1600 1600 1
USA 200902 ~ 200901 1390 1600 .8688
USA 200903 ~ 200901 1730 1600 1.0813
USA 200904 ~ 200901 1900 1600 1.1875
USA 200905 ~ 200901 1850 1600 1.1563
USA 200906 ~ 200901 3800 1600 2.375
USA 200907 ~ 200901 1700 1600 1.0625
USA 200908 ~ 200901 1490 1600 .9313
USA 200909 ~ 200901 1830 1600 1.1438
USA 200910 ~ 200901 2000 1600 1.25
USA 200911 ~ 200901 1950 1600 1.2188
USA 200912 ~ 200901 1900 1600 1.1875
自定义聚集函数
用户可以通过实现 Oracle 的 Extensibility Framework 中的 ODCIAggregate interface 来创建自定义聚集函数
接口函数
- static function ODCIAggregateInitialize(sctx IN OUT str_conn_type) return number
自定义聚集函数初始化操作,从这儿开始一个聚集函数
- member function ODCIAggregateIterate(self IN OUT str_conn_type, value IN varchar2) return number
自定义聚集函数的最主要步骤,这个函数定义我们聚集函数做什么操作(如取最大值,最小值,平均值),self 为当前聚集函数的指针,用来与前面的计算结果进行关联
- member function ODCIAggregateMerge(self IN OUT str_conn_type, ctx2 str_conn_type) return number
用来合并两个聚集函数的两个不同指针对应的结果
- member function ODCIAggregateTerminate(self IN str_conn_type, returnValue OUT varchar2, flags IN number) return number
终止聚集函数的处理,返回聚集函数处理的结果
创建自定义聚集函数
- 创建 OBJECT TYPE
create or replace type secmax_context as object( firmax number, -- 保存最大值 secmax number, -- 保存第二大值 static function odciaggregateinitialize(sctx in out secmax_context) return number, --初始化函数 member function odciaggregateiterate(self in out secmax_context,value in number) return number, --迭代运算函数 member function odciaggregatemerge(self in out secmax_context, ctx2 in secmax_context)return number, --合并两个上下文到一个上下文中 member function odciaggregateterminate(self in secmax_context, returnvalue out number, flags in number) return number --对结果进行处理并返回处理结果 );
- 实现该 OBJECT TYPE
create or replace type body secmax_context is
static function ODCIAggregateInitialize(sctx IN OUT secmax_context) return number is
begin
sctx := secmax_context(0, 0);
return ODCIConst.Success;
end;
member function ODCIAggregateIterate(self IN OUT secmax_context, value IN number) return number is
begin
if value > self.firmax then
self.secmax := self.firmax;
self.firmax := value;
elsif value > self.secmax then
self.secmax := value;
end if;
return ODCIConst.Success;
end;
member function ODCIAggregateTerminate(self IN secmax_context, returnValue OUT number, flags IN number) return number is
begin
returnValue := self.secmax;
return ODCIConst.Success;
end;
member function ODCIAggregateMerge(self IN OUT secmax_context, ctx2 IN secmax_context) return number is
begin
if ctx2.firmax > self.firmax then
if ctx2.secmax > self.firmax then
self.secmax := ctx2.secmax;
else
self.secmax := self.firmax;
end if;
self.firmax := ctx2.firmax;
elsif ctx2.firmax > self.secmax then
self.secmax := ctx2.firmax;
end if;
return ODCIConst.Success;
end;
end;
- 创建聚合函数
create or replace function f_secmax (input number) return number parallel_enable aggregate using secmax_context;
- 数据测试
select f_secmax(sal) from scott.emp;
F_SECMAX(SAL)
-------------
3000
select * from (
select
t.emp_id, t.dept_id, t.hire_date, t.salary,
f_secmax(t.salary) over(partition by t.dept_id) max_sal
from employee t
) where salary = max_sal order by dept_id, emp_id;
EMP_ID DEPT_ID HIRE_DATE SALARY MAX_SAL
---------- ---------- ---------- ---------- ----------
120 50 1996-07-18 8000 8000
104 60 1991-05-21 6000 6000
146 80 1997-01-05 13500 13500
101 90 1989-09-21 17000 17000
102 90 1993-01-13 17000 17000
109 100 1994-08-16 9000 9000
原创文章,转载请注明出处:http://www.opcoder.cn/article/3/
qingshan
1楼 - 7 年,3 月 之前