在 MaxCompute SQL 中处理大数据量表时,数据倾斜是一个常见的性能瓶颈。当两张大表进行 JOIN 操作时,如果关联键分布不均,某些节点可能会承担过多的数据处理任务,导致任务执行效率低下。为了解决这一问题,需要从 JOIN 键的选择、技术手段的应用以及 SQL 优化等多方面入手。
MAPJOIN HINT
当对一个大表和一个或多个小表执行 join 操作时,可以在 select 语句中显式指定 mapjoin Hint 提示以提升查询性能。
功能介绍
- 整个 join 过程包含 Map、Shuffle 和 Reduce三个阶段。通常情况下,join 操作在 Reduce 阶段执行表连接
- mapjoin 在 Map 阶段执行表连接,而非等到 Reduce 阶段才执行表连接,可以缩短大量数据传输时间,提升系统资源利用率,从而起到优化作业的作用
- 在对大表和一个或多个小表执行 join 操作时,mapjoin 会将指定的小表全部加载到执行 join 操作的程序的内存中, 在Map 阶段完成表连接从而加快 join 的执行速度
此外,MaxCompute SQL 不支持在普通 join 的 on 条件中使用不等值表达式、or 等逻辑复杂的 join 条件,但是在 mapjoin 中可以进行上述操作。
使用限制
mapjoin 操作的使用限制如下:
使用方法
需要在 select 语句中使用 Hint 提示 /*+ mapjoin(<table_name>) */ 才会执行 mapjoin。需要注意的是:
- 引用小表或子查询时,需要引用别名
- mapjoin 支持小表为子查询
- 在 mapjoin 中,可以使用不等值连接或 or 连接多个条件。可以通过不写 on 语句而通过
mapjoin on 1 = 1的形式,实现笛卡尔乘积的计算。例如select /*+ mapjoin(a) */ a.id from shop a join table_name b on 1=1;,但此操作可能带来数据量膨胀问题 - mapjoin 中多个小表用英文逗号(,)分隔,例如
/*+ mapjoin(a, b, c) */
示例数据
为便于理解,本文提供如下源数据,基于源数据提供相关示例。创建表 sale_detail 和 sale_detail_sj,并添加数据,命令示例如下:
-- 1. 创建分区表 create table if not exists sale_detail ( shop_name string, customer_id string, total_price double ) partitioned by (sale_date string, region string); create table if not exists sale_detail_sj ( shop_name string, customer_id string, total_price double ) partitioned by (sale_date string, region string); -- 2. 向源表增加分区 alter table sale_detail add partition (sale_date='2013', region='china'); alter table sale_detail_sj add partition (sale_date='2013', region='china'); -- 3. 向源表追加数据 insert into sale_detail partition (sale_date='2013', region='china') values ('s1', 'c1', 100.1), ('s2', 'c2', 100.2), ('s3', 'c3', 100.3); insert into sale_detail_sj partition (sale_date='2013', region='china') values ('s1', 'c1', 100.1), ('s2', 'c2', 100.2), ('s5', 'c2', 100.2), ('s2', 'c2', 100.2);
使用示例
对表 sale_detail 和 sale_detail_sj 执行 join 操作,满足 sale_detail_sj 中的 total_price 小于 sale_detail 中的 total_price 或 sale_detail_sj 中的 total_price 与 sale_detail 中的 total_price 之和小于 500 的条件,命令示例如下:
-- 允许分区表的全表扫描 SET odps.sql.allow.fullscan=true; -- 使用 mapjoin 查询 select /*+ mapjoin(a) */ a.shop_name, a.total_price, b.total_price from sale_detail_sj a join sale_detail b on a.total_price < b.total_price or a.total_price + b.total_price < 500;
返回结果如下:
+-----------+-------------+--------------+ | shop_name | total_price | total_price2 | +-----------+-------------+--------------+ | s1 | 100.1 | 100.1 | | s2 | 100.2 | 100.1 | | s5 | 100.2 | 100.1 | | s2 | 100.2 | 100.1 | | s1 | 100.1 | 100.2 | | s2 | 100.2 | 100.2 | | s5 | 100.2 | 100.2 | | s2 | 100.2 | 100.2 | | s1 | 100.1 | 100.3 | | s2 | 100.2 | 100.3 | | s5 | 100.2 | 100.3 | | s2 | 100.2 | 100.3 | +-----------+-------------+--------------+
附:如何用 MAPJOIN 缓存多张小表
MAPJOIN 是一种优化技术,可以通过将小表缓存到内存中来加速查询。可以在 MAPJOIN 中填写表的别名。
假设项目中存在一张表 iris,表结构如下:
-- drop table if exists iris; create table if not exists iris ( sepal_length double, sepal_width double, petal_length double, petal_width double, category string ); +---------------+-------------+--------------+--------------+ | Field | Type | Label | Comment | +---------------+-------------+--------------+--------------+ | sepal_length | double | | | | sepal_width | double | | | | petal_length | double | | | | petal_width | double | | | | category | string | | | +---------------+-------------+--------------+--------------+
使用 MAPJOIN 实现缓存多张小表的命令示例如下:
select /*+ mapjoin(b, c) */ a.category ,b.cnt as cnt_category ,c.cnt as cnt_all from iris a inner join ( select count(*) as cnt, category from iris group by category ) b on a.category = b.category inner join ( select count(*) as cnt from iris ) c;
SUBQUERY_MAPJOIN HINT
MaxCompute 支持子查询操作,部分子查询在执行过程中会被转换成 JOIN 进行计算。可以在子查询 SUBQUERY 语句中使用 SUBQUERY_MAPJOIN HINT,以显式指定使用 MAPJOIN 算法,从而提升子查询的执行效率。下面介绍如何使用 SUBQUERY_MAPJOIN HINT。
使用限制
- 仅适用于 SCALAR、IN、NOT IN、EXISTS 和 NOT EXISTS 子查询,不适用于基础子查询
- 使用 SUBQUERY_MAPJOIN HINT 时不需要手动指定小表,系统默认以 SUBQUERY 的计算结果作为 MAPJOIN 的小表
- 部分场景下,子查询不会被转换成 JOIN 来执行,此时使用 SUBQUERY_MAPJOIN HINT 时,系统会输出 Warning 进行提示
- 若 SUBQUERY 的计算结果数据量过大,可能会导致 MAPJOIN 运行时出现内存溢出(Out of Memory)的情况,请确认 SUBQUERY 的计算结果为小表时再使用此 HINT
使用方法
在 SUBQUERY 语句中,需要使用 HINT 提示 /*+ subquery_mapjoin */ 来指定 MAPJOIN 算法的执行,且 HINT 必须紧贴于 SUBQUERY 对应的左括号之后书写。用法如下:
假设 t1、t2 两张表的定义如下:
CREATE TABLE t1(a BIGINT, b BIGINT); CREATE TABLE t2(a BIGINT, b BIGINT);
- SCALAR SUBQUERY
SELECT a, (/*+ subquery_mapjoin */ SELECT b FROM t2 WHERE a = t1.a) FROM t1;
- IN 和 NOT IN SUBQUERY
SELECT * FROM t1 WHERE a IN (/*+ subquery_mapjoin */ SELECT a FROM t2 WHERE b = t1.b); SELECT * FROM t1 WHERE a NOT IN (/*+ subquery_mapjoin */ SELECT a FROM t2 WHERE b = t1.b);
- EXISTS 和 NOT EXISTS SUBQUERY
SELECT * FROM t1 WHERE EXISTS (/*+ subquery_mapjoin */ SELECT * FROM t2 WHERE b = t1.b); SELECT * FROM t1 WHERE NOT EXISTS (/*+ subquery_mapjoin */ SELECT * FROM t2 WHERE b = t1.b);
- 错误写法
-- 如下代码为错误格式,SUBQUERY_MAPJOIN HINT 没有紧贴于 SUBQUERY 对应的左括号之后书写 SELECT * FROM t1 WHERE a IN (SELECT /*+ subquery_mapjoin */ a FROM t2 WHERE b = t1.b);
示例数据
- 创建表 sale_detail 和 shop_detail,并添加数据,命令示例如下:
-- 1. 创建一张分区表 sale_detail CREATE TABLE if NOT EXISTS sale_detail ( shop_name STRING, customer_id STRING, total_price DOUBLE ) PARTITIONED BY (sale_date STRING, region STRING); -- 2. 向 sale_detail 表增加分区 ALTER TABLE sale_detail ADD PARTITION (sale_date='2013', region='china') PARTITION (sale_date='2014', region='shanghai'); -- 3. 向sale_detail表追加数据 INSERT INTO sale_detail PARTITION (sale_date='2013', region='china') VALUES ('s1', 'c1', 100.1), ('s2', 'c2', 100.2), ('s3', 'c3', 100.3); INSERT INTO sale_detail PARTITION (sale_date='2014', region='shanghai') VALUES ('null' , 'c5', null), ('s6' , 'c6', 100.4), ('s7' , 'c7', 100.5); -- 4. 创建一张 shop_detail 表,插入 sale_detail 表分区为 2013 下的数据 SET odps.sql.allow.fullscan=true; CREATE TABLE shop_detail AS SELECT shop_name, customer_id, total_price FROM sale_detail WHERE sale_date='2013'AND region='china';
- 查询分区表 sale_detail 中的数据,命令示例如下:
SET odps.sql.allow.fullscan=true; SELECT * FROM sale_detail; +------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s3 | c3 | 100.3 | 2013 | china | | null | c5 | NULL | 2014 | shanghai | | s6 | c6 | 100.4 | 2014 | shanghai | | s7 | c7 | 100.5 | 2014 | shanghai | +------------+-------------+-------------+------------+------------+
- 查询 shop_detail 表中的数据,命令示例如下:
SELECT * FROM shop_detail; +------------+-------------+-------------+ | shop_name | customer_id | total_price | +------------+-------------+-------------+ | s1 | c1 | 100.1 | | s2 | c2 | 100.2 | | s3 | c3 | 100.3 | +------------+-------------+-------------+
使用示例
- SCALAR SUBQUERY 使用 SUBQUERY_MAPJOIN HINT
SET odps.sql.allow.fullscan=true; SELECT * FROM shop_detail WHERE (/*+ subquery_mapjoin */ SELECT COUNT(*) FROM sale_detail WHERE sale_detail.shop_name = shop_detail.shop_name) >= 1; +------------+-------------+-------------+ | shop_name | customer_id | total_price | +------------+-------------+-------------+ | s1 | c1 | 100.1 | | s2 | c2 | 100.2 | | s3 | c3 | 100.3 | +------------+-------------+-------------+
- IN 子 SUBQUERY 使用 SUBQUERY_MAPJOIN HINT
SET odps.sql.allow.fullscan=true; SELECT * FROM sale_detail WHERE total_price IN (/*+ subquery_mapjoin */ SELECT total_price FROM shop_detail WHERE customer_id = shop_detail.customer_id); +------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s3 | c3 | 100.3 | 2013 | china | +------------+-------------+-------------+------------+------------+
- EXISTS SUBQUERY 使用 SUBQUERY_MAPJOIN HINT
SET odps.sql.allow.fullscan=true; SELECT * FROM sale_detail WHERE EXISTS (/*+ subquery_mapjoin */ SELECT * FROM shop_detail WHERE customer_id = sale_detail.customer_id); +------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s3 | c3 | 100.3 | 2013 | china | +------------+-------------+-------------+------------+------------+
- 不支持基础子查询指定使用 SUBQUERY_MAPJOIN HINT
如下 Query 会报错,因为 subquery_mapjoin 不支持基础子查询。
SET odps.sql.allow.fullscan=true; SELECT * FROM (/*+ subquery_mapjoin */ SELECT shop_name FROM sale_detail) a; -- 报错信息 FAILED: ODPS-0130161:[1,16] Parse exception - invalid subquery_mapjoin hint, should only be used for scalar/in/exists subquery
- 未转成 JOIN 的子查询,系统会在输出查询结果的同时,进行报错提示(即 WARNING 信息)
-- 在表 shop_detail 中增加一列,并添加数据 ALTER TABLE shop_detail ADD columns if not exists(sale_date STRING); INSERT OVERWRITE TABLE shop_detail VALUES ('s1', 'c1', 100.1, '2013'), ('s2', 'c2', 100.2, '2013'), ('s3', 'c3', 100.3, '2013'); -- 该 flag 允许系统输出 warning,假如 project 的默认配置已经满足要求,则不需要设置 SET odps.compiler.warning.disable=false; -- 以下查询由于涉及到分区表,系统为了支持分区裁剪,没有把 subquery 转成join, 使用 SUBQUERY_MAPJOIN HINT 时,系统会输出 waring 信息 SELECT * FROM sale_detail WHERE sale_date IN (/*+ subquery_mapjoin */ SELECT sale_date FROM shop_detail);
返回结果如下:
+------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s3 | c3 | 100.3 | 2013 | china | +------------+-------------+-------------+------------+------------+
WARNING 信息如下:
WARNING:[1,47] subquery_mapjoin hint does not work because the subquery is not converted to join
DISTRIBUTED MAPJOIN
Distributed MapJoin 是 MapJoin 的升级版,适用于大表 Join 中表的场景,二者的核心目的都是为了减少大表侧的 Shuffle 和排序。
注意事项
- Join 两侧的表数据量要求不同,大表侧数据在 10 TB 以上,中表侧数据在 [1 GB, 100 GB] 范围内
- 小表侧的数据需要均匀分布,没有明显的长尾,否则单个分片会产生过多的数据,导致 OOM(Out Of Memory)及 RPC(Remote Procedure Call)超时问题
- SQL 任务运行时间在 20 分钟以上,建议使用 Distributed MapJoin 进行优化
- 由于在执行任务时,需要占用较多的资源,请避免在较小的 Quota 组运行
使用方法
需要在 select 语句中使用 Hint 提示 /*+ distmapjoin(<table_name>(shard_count=<n>,replica_count=<m>)) */ 才会执行 distmapjoin。shard_count 和 replica_count 共同决定任务运行的并发度,即 并发度=shard_count * replica_count。
参数说明
- table_name:目标表名
- shard_count=
:设置小表数据的分片数,小表数据分片会分布至各个计算节点处理。n 即为分片数,一般按奇数设置
- replica_count=
:设置小表数据的副本数。m 即为副本数,默认为 1
语法示例
-- 推荐,指定 shard_count(replica_count 默认为 1) /*+ distmapjoin(a(shard_count=5)) */ -- 推荐,指定 shard_count 和 replica_count /*+ distmapjoin(a(shard_count=5,replica_count=2)) */ -- distmapjoin 多个小表 /*+ distmapjoin(a(shard_count=5,replica_count=2),b(shard_count=5,replica_count=2)) */ -- distmapjoin 和 mapjoin 混用 /*+ distmapjoin(a(shard_count=5,replica_count=2)),mapjoin(b) */
使用示例
为了便于理解,本文以向分区表 tmall_dump_lasttable 插入数据为例,演示 Distributed MapJoin 的用法。
- 常规写法
insert overwrite table tmall_dump_lasttable partition(ds='20211130') select t1.* from ( select nid ,doc ,type from search_ods.dump_lasttable where ds='20211203' ) t1 inner join ( select distinct item_id from tbcdm.dim_tb_itm where ds='20211130' and bc_type='B' and is_online='Y' ) t2 on t1.nid=t2.item_id;
- 优化后写法
insert overwrite table tmall_dump_lasttable partition (ds='20211130') select /*+ distmapjoin(t2(shard_count=35)) */ t1.* from ( select nid ,doc ,type from search_ods.dump_lasttable where ds='20211203' ) t1 inner join ( select distinct item_id from tbcdm.dim_tb_itm where ds='20211130' and bc_type='B' and is_online='Y' ) t2 on t1.nid=t2.item_id;
SKEWJOIN HINT
当两张表 Join 存在热点,导致出现长尾问题时,可以通过取出热点 key,将数据分为热点数据和非热点数据两部分处理,最后合并的方式,提高 Join 效率。
SkewJoin Hint 可以通过自动或手动方式获取两张表的热点 key,分别计算热点数据和非热点数据的 Join 结果并合并,加快 Join 的执行速度。
使用方法
需要在 select 语句中使用 Hint 提示 /*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])] */ 才会执行 SkewJoin。table_name 为倾斜表名,column_name 为倾斜列名,value 为倾斜 key 值。
-- 方法1:Hint 表名(注意 Hint 的是表的 alias) select /*+ skewjoin(a) */ * from T0 a join T1 b on a.c0 = b.c0 and a.c1 = b.c1; -- 方法2:Hint 表名和认为可能产生倾斜的列,例如表 a 的 c0 和 c1 列存在数据倾斜 select /*+ skewjoin(a(c0, c1)) */ * from T0 a join T1 b on a.c0 = b.c0 and a.c1 = b.c1 and a.c2 = b.c2; -- 方法3:Hint 表名和列,并提供发生倾斜的 key 值。如果是 STRING 类型,需要加上引号。例如(a.c0=1 and a.c1="2") 和 (a.c0=3 and a.c1="4") 的值都存在数据倾斜 select /*+ skewjoin(a(c0, c1)((1, "2"), (3, "4"))) */ * from T0 a join T1 b on a.c0 = b.c0 and a.c1 = b.c1 and a.c2 = b.c2;
注:方法 3 直接指定值的处理效率比方法 1 和方法 2(不指定值)高。
实现原理
热值 Key 指出现次数很多的 key 值。例如下图中红色部分,a.c0=1 and a.c1=2 有 10000 行,a.c0=3 and a.c1 = 4 有 9000 行。
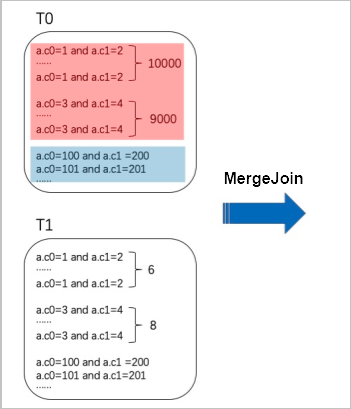
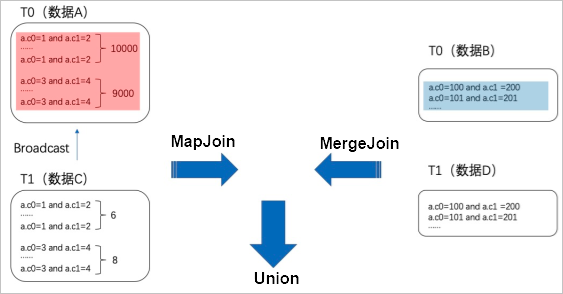
在不加 SkewJoin Hint 的情况下,将表 T0 和表 T1 进行 Join,由于 T0 和 T1 的数量都很大,只能进行 MergeJoin,因此相同的热值都会 Shuffle 到一个节点,导致数据倾斜。加 SkewJoin Hint 后,优化器会运行一个 Aggregate 动态获取重复行数前 20 的热值,并将表 T0 中属于热值的值(数据 A)、T0 中不属于热值的值(数据 B)拆分;将表 T1 中能与 T0 中热值 Join 的值(数据 C)、表 T1 中不能与 T0 中热值 Join 的值(数据 D)进行拆分。然后将数据 A 与数据 C 进行 MapJoin(由于数据 C 量很少,可以进行 MapJoin),将数据 B 和数据 D 进行 MergeJoin。最后将 MapJoin 和 MergeJoin 的结果 Union,生成最后的结果,如下图所示。
注意事项
create table T0(c0 int, c1 int, c2 int, c3 int); create table T1(c0 string, c1 int, c2 int); -- 方法1: select /*+ skewjoin(a) */ * from T0 a join T1 b on cast(a.c0 as string) = cast(b.c0 as string) and a.c1 = b.c1; -- 方法2: select /*+ skewjoin(b) */ * from (select cast(a.c0 as string) as c00 from T0 a) b join T1 c on b.c00 = c.c0;
select /*+ mapjoin(c), skewjoin(a) */ * from T0 a join T1 b on a.c0 = b.c3 join T2 c on a.c0 = c.c7;
参考资料
原创文章,转载请注明出处:http://www.opcoder.cn/article/98/