MaxCompute 自身预置了诸多函数,可以满足大部分业务场景的数据处理需求。
注意事项
升级到 MaxCompute 2.0 后,产品扩展了部分函数。如果用到的函数涉及新数据类型(TINYINT、SMALLINT、INT、FLOAT、VARCHAR、TIMESTAMP 或 BINARY),在使用扩展函数时,需要执行如下语句开启新数据类型开关:
- Session 级别:如果使用新数据类型,需要在 SQL 语句前加上语句
set odps.sql.type.system.odps2=true;,并与 SQL 语句一起提交执行 - Project 级别:Project Owner 可根据需要对 Project 进行设置,等待 10~15 分钟后才会生效
setproject odps.sql.type.system.odps2=true;
创建示例表
-- drop table emp; create table if not exists emp ( empno bigint ,ename string ,job string ,mgr bigint ,hiredate date ,sal bigint ,comm bigint ,deptno bigint ); insert into emp values (7369, 'SMITH' , 'CLERK' , 7902, date'1980-12-17', 800 , null, 20), (7499, 'ALLEN' , 'SALESMAN' , 7698, date'1981-02-20', 1600, 300 , 30), (7521, 'WARD' , 'SALESMAN' , 7698, date'1981-02-22', 1250, 500 , 30), (7566, 'JONES' , 'MANAGER' , 7839, date'1981-04-02', 2975, null, 20), (7654, 'MARTIN' , 'SALESMAN' , 7698, date'1981-09-28', 1250, 1400, 30), (7698, 'BLAKE' , 'MANAGER' , 7839, date'1981-05-01', 2850, null, 30), (7782, 'CLARK' , 'MANAGER' , 7839, date'1981-06-09', 2450, null, 10), (7788, 'SCOTT' , 'ANALYST' , 7566, date'1987-04-19', 3000, null, 20), (7839, 'KING' , 'PRESIDENT' , null, date'1981-11-17', 5000, null, 10), (7844, 'TURNER' , 'SALESMAN' , 7698, date'1981-09-08', 1500, 0 , 30), (7876, 'ADAMS' , 'CLERK' , 7788, date'1987-05-23', 1100, null, 20), (7900, 'JAMES' , 'CLERK' , 7698, date'1981-12-03', 950 , null, 30), (7902, 'FORD' , 'ANALYST' , 7566, date'1981-12-03', 3000, null, 20), (7934, 'MILLER' , 'CLERK' , 7782, date'1982-01-23', 1300, null, 10), (7948, 'JACCKA' , 'CLERK' , 7782, date'1981-04-12', 5000, null, 10), (7956, 'WELAN' , 'CLERK' , 7649, date'1982-07-20', 2450, null, 10), (7956, 'TEBAGE' , 'CLERK' , 7748, date'1982-12-30', 1300, null, 10);
日期与时间函数
MaxCompute 支持的日期函数,包括日期函数的命令格式、参数说明和使用示例。
函数目录
| 序号 | 函数名称 | 函数功能 |
| 1 | ADD_MONTHS | 计算日期值增加指定月数后的日期。 |
| 2 | DATEADD | 按照指定的单位和幅度修改日期值。 |
| 3 | DATE_ADD | 按照指定的幅度增减天数。 |
| 4 | DATE_SUB | 按照指定的幅度增减天数。 |
| 5 | DATEDIFF | 将一行数据转换为多行数据的计算两个日期的差值并按照指定的单位表示。 |
| 6 | TO_DATE | 将指定格式的字符串转换为日期值。 |
| 7 | DATETRUNC | 返回一个随机提取日期按照指定时间单位截取后的值。 |
| 8 | LAST_DAY | 返回日期值所在月份的最后一天日期。 |
| 9 | MONTHS_BETWEEN | 返回指定日期值间的月数。 |
| 10 | NEXT_DAY | 返回大于日期值且与指定周相匹配的第一个日期。 |
| 11 | QUARTER | 返回日期值所属季度。 |
示例数据
创建表 mf_date_fun_t,并添加数据,命令示例如下。
-- drop table mf_date_fun_t; create table if not exists mf_date_fun_t ( id int ,d_date date ,d_datetime datetime ,t_timestamp timestamp ,s_date string ,b_date bigint ); insert into mf_date_fun_t values (1 , date'2020-02-29' , datetime'2020-02-29 00:01:00', timestamp'2020-02-29 00:00:00.123456789', '2020-02-29', 123456780), (2 , date'2020-03-01' , datetime'2020-03-01 00:02:00', timestamp'2020-03-01 00:00:00.123456789', '2020-03-01', 123456781), (3 , date'2020-06-30' , datetime'2020-06-30 00:03:00', timestamp'2020-06-30 00:00:00.123456789', '2020-06-30', 123456782), (4 , date'2021-02-28' , datetime'2021-02-28 00:04:00', timestamp'2021-02-28 00:00:00.123456789', '2021-02-28', 123456783), (5 , date'2021-03-01' , datetime'2021-03-01 00:05:00', timestamp'2021-03-01 00:00:00.123456789', '2021-03-01', 123456784), (6 , date'2021-12-31' , datetime'2021-12-31 00:06:00', timestamp'2021-12-31 00:00:00.123456789', '2021-12-31', 123456785), (7 , date'2023-02-01' , datetime'2023-02-01 00:07:00', timestamp'2023-02-01 00:00:00.123456789', '2023-02-01', 123456786), (8 , date'2023-02-28' , datetime'2023-02-28 00:08:00', timestamp'2023-02-28 00:00:00.123456789', '2023-02-28', 123456787), (9 , date'2024-02-01' , datetime'2024-02-01 00:09:00', timestamp'2024-02-01 00:00:00.123456789', '2024-02-01', 123456788);
查询表 mf_date_fun_t 中的数据,命令示例如下:
select * from mf_date_fun_t order by id; -- 返回结果 +------------+------------+---------------------+-------------------------+------------+------------+ | id | d_date | d_datetime | t_timestamp | s_date | b_date | +------------+------------+---------------------+-------------------------+------------+------------+ | 1 | 2020-02-29 | 2020-02-29 00:01:00 | 2020-02-29 00:00:00.123 | 2020-02-29 | 123456780 | | 2 | 2020-03-01 | 2020-03-01 00:02:00 | 2020-03-01 00:00:00.123 | 2020-03-01 | 123456781 | | 3 | 2020-06-30 | 2020-06-30 00:03:00 | 2020-06-30 00:00:00.123 | 2020-06-30 | 123456782 | | 4 | 2021-02-28 | 2021-02-28 00:04:00 | 2021-02-28 00:00:00.123 | 2021-02-28 | 123456783 | | 5 | 2021-03-01 | 2021-03-01 00:05:00 | 2021-03-01 00:00:00.123 | 2021-03-01 | 123456784 | | 6 | 2021-12-31 | 2021-12-31 00:06:00 | 2021-12-31 00:00:00.123 | 2021-12-31 | 123456785 | | 7 | 2023-02-01 | 2023-02-01 00:07:00 | 2023-02-01 00:00:00.123 | 2023-02-01 | 123456786 | | 8 | 2023-02-28 | 2023-02-28 00:08:00 | 2023-02-28 00:00:00.123 | 2023-02-28 | 123456787 | | 9 | 2024-02-01 | 2024-02-01 00:09:00 | 2024-02-01 00:00:00.123 | 2024-02-01 | 123456788 | +------------+------------+---------------------+-------------------------+------------+------------+
ADD_MONTHS
命令格式
string add_months(date|datetime|timestamp|string <startdate>, int <num_months>)
命令说明
返回开始日期 startdate 增加 num_months 个月后的日期。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- startdate:必填。DATE、DATETIME、TIMESTAMP 或 STRING 类型,格式为
yyyy-mm-dd、yyyy-mm-dd hh:mi:ss或yyyy-mm-dd hh:mi:ss.ff3。取值为 STRING 类型格式时,至少要包含yyyy-mm-dd且不含多余的字符串 - num_months:必填。INT 型数值
返回值说明
返回 STRING 类型的日期值,格式为 yyyy-mm-dd。返回规则如下:
- startdate 非 DATE、DATETIME、TIMESTAMP 或 STRING 类型,或格式不符合要求时,返回 NULL
- startdate 值为 NULL 时,返回报错
- num_months 值为 NULL 时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 2020-02-29 select add_months('2020-01-31', 1); -- 返回 0020-03-01 select add_months('20-2-1', 1); -- 返回 2020-05-31 select add_months('2020-02-29 21:30:00', 3); -- 返回 2020-02-29 select add_months('2020-03-30', -1); -- 参数为 STRING 类型,且不满足 yyyy-mm-dd 格式,返回 NULL select add_months('20200229', 3); -- 返回 NULL select add_months('2020-02-29 21:30:00', null);
- 示例2:表数据示例
select d_date ,add_months(d_date , 1) as d_date_add_months ,d_datetime ,add_months(d_datetime , 2) as d_datetime_add_months ,t_timestamp ,add_months(t_timestamp , 3) as t_timestamp_add_months ,s_date ,add_months(s_date , 4) as s_date_add_months from mf_date_fun_t; +-------------+--------------------+----------------------+------------------------+--------------------------------+-------------------------+-------------+-------------------+ | d_date | d_date_add_months | d_datetime | d_datetime_add_months | t_timestamp | t_timestamp_add_months | s_date | s_date_add_months | +-------------+--------------------+----------------------+------------------------+--------------------------------+-------------------------+-------------+-------------------+ | 2020-02-29 | 2020-03-31 | 2020-02-29 00:01:00 | 2020-04-30 | 2020-02-29 00:00:00.123456789 | 2020-05-31 | 2020-02-29 | 2020-06-30 | | 2020-03-01 | 2020-04-01 | 2020-03-01 00:02:00 | 2020-05-01 | 2020-03-01 00:00:00.123456789 | 2020-06-01 | 2020-03-01 | 2020-07-01 | | 2020-06-30 | 2020-07-31 | 2020-06-30 00:03:00 | 2020-08-31 | 2020-06-30 00:03:00.123456789 | 2020-09-30 | 2020-06-30 | 2020-10-31 | | 2021-02-28 | 2021-03-31 | 2021-02-28 00:04:00 | 2021-04-30 | 2021-02-28 00:04:00.123456789 | 2021-05-31 | 2021-02-28 | 2021-06-30 | | 2021-03-01 | 2021-04-01 | 2021-03-01 00:05:00 | 2021-05-01 | 2021-03-01 00:05:00.123456789 | 2021-06-01 | 2021-03-01 | 2021-07-01 | | 2021-12-31 | 2022-01-31 | 2021-12-31 00:06:00 | 2022-02-28 | 2021-12-31 00:06:00.123456789 | 2022-03-31 | 2021-12-31 | 2022-04-30 | | 2023-02-01 | 2023-03-01 | 2023-02-01 00:07:00 | 2023-04-01 | 2023-02-01 00:07:00.123456789 | 2023-05-01 | 2023-02-01 | 2023-06-01 | | 2023-02-28 | 2023-03-31 | 2023-02-28 00:08:00 | 2023-04-30 | 2023-02-28 00:08:00.123456789 | 2023-05-31 | 2023-02-28 | 2023-06-30 | | 2024-02-01 | 2024-03-01 | 2024-02-01 00:09:00 | 2024-04-01 | 2024-02-01 00:09:00.123456789 | 2024-05-01 | 2024-02-01 | 2024-06-01 | +-------------+--------------------+----------------------+------------------------+--------------------------------+-------------------------+-------------+-------------------+
DATEADD
命令格式
date|datetime dateadd(date|datetime|timestamp <date>, bigint <delta>, string <datepart>)
命令说明
按照指定的单位 datepart 和幅度 delta 修改 date 的值。
参数说明
- date:必填。日期值,DATE、DATETIME 或 TIMESTAMP 类型。如果参数为 STRING 类型,需符合 DATETIME 类型的格式,即
yyyy-mm-dd hh:mi:ss - delta:必填。修改幅度,BIGINT 类型。如果 delta 大于 0,则增,否则减
- datepart:必填。指定修改的单位,STRING 类型常量。此字段的取值遵循 STRING 与 DATETIME 类型转换的约定,即
yyyy表示年,mm表示月,dd表示天,hour表示小时
返回值说明
返回 DATE 或 DATETIME 类型,格式为 yyyy-mm-dd 或 yyyy-mm-dd hh:mi:ss。返回规则如下:
- date 为非 DATE、DATETIME 或 TIMESTAMP 类型时,返回报错
- date 值为 NULL 时,返回报错
- delta 或 datepart 值为 NULL 时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 2005-03-01 00:00:00。加1天,结果超出当年2月份的最后一天,实际值为下个月的第1天 select dateadd(datetime'2005-02-28 00:00:00', 1, 'dd'); -- 返回 2005-02-27 00:00:00。减1天 select dateadd(datetime'2005-02-28 00:00:00', -1, 'dd'); -- 返回 2006-10-28 00:00:00。加20个月,月份溢出,年份加1 select dateadd(datetime'2005-02-28 00:00:00', 20, 'mm'); -- 返回 2005-03-28 00:00:00 select dateadd(datetime'2005-02-28 00:00:00', 1, 'mm'); -- 返回 2005-02-28 00:00:00。2005年2月没有29日,日期截取至当月最后1天 select dateadd(datetime'2005-01-29 00:00:00', 1, 'mm'); -- 返回 2005-02-28 00:00:00 select dateadd(datetime'2005-03-30 00:00:00', -1, 'mm'); -- 返回 2005-03-18 select dateadd(date'2005-02-18', 1, 'mm'); -- 返回 NULL select dateadd(date'2005-02-18', 1, null);
- 示例2:输入参数为 STRING 类型
-- 如下输入参数为 STRING 类型,但不符合 DATETIME 类型格式,会返回报错
select dateadd('2021-08-27', 1, 'dd');
DATE_ADD
命令格式
date date_add(date|timestamp|string <startdate>, bigint <delta>)
命令说明
按照 delta 幅度增减 startdate 日期的天数。
参数说明
- startdate:必填。起始日期值。支持 DATE、DATETIME 或 STRING 类型
- delta:必填。修改幅度。BIGINT 类型。如果 delta 大于 0,则增;delta 小于 0,则减;delta 等于 0,不增不减
返回值说明
返回 DATE 类型,格式为 yyyy-mm-dd。返回规则如下:
- startdate 非 DATE、DATETIME 或 STRING 类型时,返回报错
- startdate 值为 NULL 时,返回报错
- delta 值为 NULL 时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 2005-03-01。加1天,结果超出当年2月份的最后1天,实际值为下个月的第1天 select date_add(datetime'2005-02-28 00:00:00', 1); -- 返回 2005-02-27。减1天 select date_add(date'2005-02-28', -1); -- 返回 2005-03-20 select date_add('2005-02-28 00:00:00', 20); -- 假设当前时间为 2020-11-17 16:31:44,返回 2020-11-16 select date_add(getdate(), -1); -- 返回 NULL select date_add('2005-02-28 00:00:00', null);
DATE_SUB
命令格式
date date_sub(date|timestamp|string <startdate>, bigint <delta>)
命令说明
按照 delta 幅度增减 startdate 日期的天数。
参数说明
- startdate:必填。起始日期值。支持 DATE、DATETIME 或 STRING 类型
- delta:必填。修改幅度。BIGINT 类型。如果 delta 大于0,则减;delta 小于 0,则增;delta 等于 0,不增不减
返回值说明
返回 DATE 类型,格式为 yyyy-mm-dd。返回规则如下:
- startdate 非 DATE、DATETIME 或 STRING 类型时,返回报错
- startdate 值为 NULL 时,返回报错
- delta 值为 NULL 时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 2005-02-28。减1天,实际值为上个月的最后1天 select date_sub(datetime '2005-03-01 00:00:00', 1); -- 返回 2005-03-01。增1天 select date_sub(date '2005-02-28', -1); -- 返回 2005-02-27。减2天 select date_sub('2005-03-01 00:00:00', 2); -- 返回 NULL select date_sub('2005-03-01 00:00:00', null);
DATEDIFF
命令格式
bigint datediff(date|datetime|timestamp <date1>, date|datetime|timestamp <date2>, string <datepart>)
命令说明
计算两个时间 date1、date2 的差值,将差值以指定的时间单位 datepart 表示。
参数说明
- date1、date2:必填。DATE、DATETIME 或 TIMESTAMP 类型
- datepart:可选。时间单位,STRING 类型常量
返回值说明
返回 BIGINT 类型。返回规则如下:
- date1、date2 非 DATE、DATETIME 或 TIMESTAMP 类型时,返回报错
- 如果 date1 小于 date2,返回值为负数
- date1 或 date2 值为 NULL 时,返回 NULL
- datepart 值为 NULL时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 假设 start=2005-12-31 23:59:59,end=2006-01-01 00:00:00,则: -- 返回 1 select datediff(end, start, 'dd'); -- 返回 1 select datediff(end, start, 'mm'); -- 返回 1 select datediff(end, start, 'yyyy'); -- 返回 1 select datediff(end, start, 'hh'); -- 返回 1 select datediff(end, start, 'mi'); -- 返回 1 select datediff(end, start, 'ss'); -- 返回 1800 select datediff(datetime'2013-05-31 13:00:00', datetime'2013-05-31 12:30:00', 'ss'); -- 返回 -30 select datediff(datetime'2013-05-31 12:00:00', datetime'2013-05-31 12:30:00', 'mi'); -- 返回 NULL select datediff(date'2013-05-21', date'2013-05-10', null); -- 返回 NULL select datediff(date'2013-05-21', null, 'dd');
TO_DATE
命令格式
datetime|date to_date(string <date>[, string <format>])
命令说明
将 date 转换成符合 format 格式的日期值。
参数说明
- date:必填。STRING 类型,要转换的字符串格式的日期值。如果输入为 BIGINT、DOUBLE、DECIMAL 或 DATETIME 类型,则会隐式转换为 STRING 类型后参与运算
- format:可选。STRING 类型常量,日期格式。format 格式:
yyyy为4位数的年,mm为2位数的月,dd为2位数的日,hh为24小时制的时,mi为2位数的分钟,ss为2位数秒
返回值说明
返回 DATE 或 DATETIME 类型。返回规则如下:
- 当函数入参无 format 参数时,且待转换的字符串格式为
yyyy-mm-dd或yyyy-mm-dd hh:mi:ss时,返回 DATE 类型,格式为yyyy-mm-dd;否则,返回 NULL - 当函数入参有 format 参数时,返回 DATETIME 类型,格式为
yyyy-mm-dd hh:mi:ss。date 或 format 值为 NULL 时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 2008-07-18 00:00:00。有 format 参数,返回 DATETIME 类型 select to_date('20080718', 'yyyymmdd'); -- 返回 NULL。无 format 参数,且待转换的字符串格式不为 yyyy-mm-dd 或 yyyy-mm-dd hh:mi:ss select to_date('20080718', 'yyyymmdd'); -- 无法转为标准日期值,引发异常 select to_date('2010-24-01', 'yyyy-mm-dd'); -- 返回 2021-09-24。无 format 参数,返回 DATE 类型 select to_date('2021-09-24'); -- 返回 2021-09-24。无 format 参数,返回 DATE 类型 select to_date('2021-09-24 13:39:34'); -- 返回 NULL select to_date(null, 'yyyymmdd hh-mi-ss.ff3'); -- 返回 NULL select to_date('20181030 15-13-12.345', null);
DATETRUNC
命令格式
date|datetime datetrunc (date|datetime|timestamp <date>, string <datepart>)
命令说明
返回将日期 date 按照 datepart 指定的时间单位进行截取后的日期值。
参数说明
- date:必填。DATE、DATETIME 或 TIMESTAMP 类型
- datepart:必填。STRING 类型常量。此字段的取值遵循 STRING 与 DATETIME 类型转换的约定,即
yyyy表示年,mm表示月,dd表示天,hour表示小时
返回值说明
返回 DATE 或 DATETIME 类型,格式为 yyyy-mm-dd 或 yyyy-mm-dd hh:mi:ss。返回规则如下:
- date 非 DATE、DATETIME 或 TIMESTAMP 类型时,返回报错
- date 值为 NULL时,返回报错
- datepart 值为 NULL时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 2011-01-01 00:00:00 select datetrunc(datetime'2011-12-07 16:28:46', 'yyyy'); -- 返回 2011-12-01 00:00:00 select datetrunc(datetime'2011-12-07 16:28:46', 'month'); -- 返回 2011-12-07 00:00:00 select datetrunc(datetime'2011-12-07 16:28:46', 'dd'); -- 返回 2011-01-01 select datetrunc(date'2011-12-07', 'yyyy'); -- 返回 NULL select datetrunc(date'2011-12-07', null);
LAST_DAY
命令格式
string last_day(date|datetime|timestamp|string <date>)
命令说明
返回该日期所在月份的最后一天日期。
参数说明
- date:必填。DATE、DATETIME、TIMESTAMP 或 STRING 类型日期值。取值为 STRING 类型格式时,至少要包含
yyyy-mm-dd且不含多余的字符串
返回值说明
返回 STRING 类型的日期值,格式为 yyyy-mm-dd。返回规则如下:
- date 非 DATE、DATETIME、TIMESTAMP 或 STRING 类型,或格式不符合要求时,返回 NULL
- date 值为 NULL时,返回报错
使用示例
- 示例1:静态数据示例
-- 返回 2017-03-31 select last_day('2017-03-04'); -- 返回 2017-07-31 select last_day('2017-07-04 11:40:00'); -- 返回 2020-02-29 select last_day(date'2020-02-03'); -- 返回 NULL select last_day('20170304');
MONTHS_BETWEEN
命令格式
double months_between(datetime|timestamp|date|string <date1>, datetime|timestamp|date|string <date2>)
命令说明
返回日期 date1 和 date2 之间的月数。
参数说明
- date1、date2:必填。DATETIME、TIMESTAMP、DATE 或 STRING 类型,格式为
yyyy-mm-dd、yyyy-mm-dd hh:mi:ss或yyyy-mm-dd hh:mi:ss.ff3。取值为 STRING 类型格式时,至少要包含yyyy-mm-dd且不含多余的字符串
返回值说明
返回 DOUBLE 类型。返回规则如下:
- 当 date1 晚于 date2 时,返回值为正。当 date2 晚于 date1 时,返回值为负
- 当 date1 和 date2 分别对应两个月的最后一天,返回整数月;否则计算方式为 date1 减去 date2 的天数除以 31 天
- date1 或 date2 值为 NULL 时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 3.9495967741935485 select months_between('1997-02-28 10:30:00', '1996-10-30'); -- 返回 -3.9495967741935485 select months_between('1996-10-30', '1997-02-28 10:30:00' ); -- 返回 -3.0 select months_between('1996-09-30', '1996-12-31'); -- 返回 1.0 select months_between(date'2020-02-29', date'2020-01-31'); -- 返回 NULL select months_between('1996-09-30', null);
NEXT_DAY
命令格式
string next_day(timestamp|date|datetime|string <startdate>, string <week>)
命令说明
返回大于指定日期 startdate 并且与 week 相匹配的第一个日期,即下周几的具体日期。
参数说明
- startdate:必填。TIMESTAMP、DATE、DATETIME 或 STRING 类型日期值,格式为
yyyy-mm-dd、yyyy-mm-dd hh:mi:ss或yyyy-mm-dd hh:mi:ss.ff3。取值为 STRING 类型格式时,至少要包含yyyy-mm-dd且不含多余的字符串 - week:必填。STRING 类型,一个星期前2个或3个字母,或者一个星期的全名。例如 MO、TUE 或 FRIDAY
| 星期 | 简写 |
| 一 | MONDAY |
| 二 | TUESDAY |
| 三 | WEDNESDAY |
| 四 | THURSDAY |
| 五 | FRIDAY |
| 六 | SATURDAY |
| 日 | SUNDAY |
返回值说明
返回 STRING 类型的日期值,格式为 yyyy-mm-dd。返回规则如下:
- date 为非 TIMESTAMP、DATE、DATETIME 或 STRING 类型,或格式不符合要求时,返回 NULL
- date 值为 NULL 时,返回报错
- week 值为 NULL 时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 2017-08-08 select next_day('2017-08-01', 'TUESDAY'); -- 返回 2017-08-08 select next_day('2017-08-01 23:34:00','TUESDAY'); -- 返回 NULL select next_day('20170801','TUESDAY'); -- 返回 NULL select next_day('2017-08-01 23:34:00', null);
QUARTER
命令格式
int quarter (datetime|timestamp|date|string <date>)
命令说明
返回一个日期的季度,范围是 1~4。
参数说明
- date:必填。DATETIME、TIMESTAMP、DATE 或 STRING 类型,格式为
yyyy-mm-dd、yyyy-mm-dd hh:mi:ss或yyyy-mm-dd hh:mi:ss.ff3。取值为 STRING 类型格式时,至少要包含yyyy-mm-dd且不含多余的字符串
返回值说明
返回 INT 类型。返回规则如下:
- date 为非 DATETIME、TIMESTAMP、DATE 或 STRING 类型,或格式不符合要求时,返回 NULL
- date 值为 NULL时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 4 select quarter('1970-11-12 10:00:00'); -- 返回 4 select quarter('1970-11-12'); -- 返回 NULL select quarter(null);
生成每月月末日期
- 支持 sequence 函数
select last_day(dateadd(getdate(), -diff, 'mm')) as year_month from ( select explode(sequence(0, 11)) diff ); +-------------+ | year_month | +-------------+ | 2024-07-31 | | 2024-06-30 | | 2024-05-31 | | 2024-04-30 | | 2024-03-31 | | 2024-02-29 | | 2024-01-31 | | 2023-12-31 | | 2023-11-30 | | 2023-10-31 | | 2023-09-30 | | 2023-08-31 | +-------------+
- 不支持 sequence 函数
select last_day(dateadd(getdate(), -diff, 'mm')) as year_month from ( select explode(array(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)) diff ); +-------------+ | year_month | +-------------+ | 2024-07-31 | | 2024-06-30 | | 2024-05-31 | | 2024-04-30 | | 2024-03-31 | | 2024-02-29 | | 2024-01-31 | | 2023-12-31 | | 2023-11-30 | | 2023-10-31 | | 2023-09-30 | | 2023-08-31 | +-------------+
数学函数
MaxCompute 支持的数学函数,包括函数的命令格式、参数说明以及使用示例。通过使用这些数学函数,可以进行数据计算、数据转换等各种操作。
函数目录
| 序号 | 函数名称 | 函数功能 |
| 1 | CBRT | 计算立方根值。 |
| 2 | CEIL | 计算向上取整值。 |
| 3 | FLOOR | 计算向下取整值。 |
| 4 | FACTORIAL | 计算阶乘值。 |
| 5 | POW | 计算幂值。 |
| 6 | SIGN | 返回输入参数的符号。 |
| 7 | SQRT | 计算平方根。 |
示例数据
CBRT
命令格式
double cbrt(<number>)
命令说明
计算 number 的立方根。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- number:必填。BIGINT、INT、SMALLINT、TINYINT、DOUBLE、FLOAT、STRING 类型数据
返回值说明
返回 DOUBLE 类型。返回规则如下:
- number 为非 BIGINT、INT、SMALLINT、TINYINT、DOUBLE、FLOAT、STRING 类型时,返回报错
- number 值为 NULL 时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 2.0 select cbrt(8); -- 返回 NULL select cbrt(null);
CEIL
命令格式
bigint ceil(<number>)
命令说明
向上取整,返回不小于输入值 number 的最小整数。
参数说明
- number:必填。DOUBLE 或 DECIMAL 类型。输入为 STRING、BIGINT 类型时,会隐式转换为 DOUBLE 类型后参与运算
返回值说明
返回 BIGINT 类型。number 值为 NULL 时,返回 NULL。
使用示例
- 示例1:静态数据示例
-- 返回 2 select ceil(1.1); -- 返回 -1 select ceil(-1.1); -- 返回 NULL select ceil(null);
FLOOR
命令格式
bigint floor(<number>)
命令说明
向下取整,返回不大于 number 的最大整数值。
参数说明
- number:必填。DOUBLE 或 DECIMAL 类型。输入为 STRING、BIGINT 类型时,会隐式转换为 DOUBLE 类型后参与运算
返回值说明
返回 BIGINT 类型。number 值为 NULL 时,返回 NULL。
使用示例
- 示例1:静态数据示例
-- 返回 1 select floor(1.2); -- 返回 0 select floor(0.1); -- 返回 -2 select floor(-1.2); -- 返回 -1 select floor(-0.1); -- 返回 0 select floor(0.0); -- 返回 0 select floor(-0.0); -- 返回 NULL select floor(null);
FACTORIAL
命令格式
bigint factorial(<number>)
命令说明
返回 number 的阶乘。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- number:必填。BIGINT、INT、SMALLINT、TINYINT 类型,且在 [0,20] 之间
返回值说明
返回 BIGINT 类型。返回规则如下:
- number 值为 0 时,返回 1
- number 值为 NULL 或 [0,20] 之外的值,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 120。5!=5*4*3*2*1=120 select factorial(5); -- 返回 1 select factorial(0); -- 返回 NULL select factorial(null);
POW
命令格式
double|decimal pow(<x>, <y>)
命令说明
计算 x 的 y 次方,即 x^y。
参数说明
- x:必填。DOUBLE 或 DECIMAL 类型。输入为 STRING、BIGINT 类型时,会隐式转换为 DOUBLE 类型后参与运算
- y:必填。DOUBLE 或 DECIMAL 类型。输入为 STRING、BIGINT 类型时,会隐式转换为 DOUBLE 类型后参与运算
返回值说明
返回 DOUBLE 或 DECIMAL 类型。返回规则如下:
- x 或 y 值为 DOUBLE、DECIMAL 类型时会返回相应的类型
- x 或 y 值为 STRING、BIGINT 类型时,返回 DOUBLE 类型
- x 或 y 值为 NULL 时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 65536.0 select pow(2, 16); -- 返回 5.0 select pow(25, 1/2); -- 返回 NULL select pow(2, null);
SIGN
命令格式
double sign(<number>)
命令说明
获取输入参数的符号。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- number:必填。DOUBLE、BIGINT、INT、SMALLINT、TINYINT、FLOAT、DECIMAL、STRING 类型
返回值说明
返回 DOUBLE 类型。返回规则如下:
- number 值为正数时,返回 1.0
- number 值为负数时,返回 -1.0
- number 值为 0 时,返回 0.0
- number 值为 NULL 时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 -1.0 select sign(-2.5); -- 返回 1.0 select sign(2.5); -- 返回 0.0 select sign(0); -- 返回 NULL select sign(null);
SQRT
命令格式
double|decimal sqrt(<number>)
命令说明
计算 number 的平方根。
参数说明
- number:必填。DOUBLE 或 DECIMAL 类型,必须大于 0,小于 0 时返回 NULL。输入为 STRING、BIGINT 类型时,会隐式转换为 DOUBLE 类型后参与运算
返回值说明
返回 DOUBLE 或 DECIMAL类型。返回规则如下:
- number 值为 DOUBLE、DECIMAL 类型时会返回相应的类型
- number 值为 STRING、BIGINT 类型时,返回 DOUBLE 类型
- number 值为 NULL 时,返回 NULL
使用示例
- 示例1:静态数据示例
-- 返回 2.0 select sqrt(4); -- 返回 NULL select sqrt(-1); -- 返回 NULL select sqrt(null);
计算连乘
select exp ( sum ( ln (case when col_name + 1 = 0 then 1 else col_name + 1 end) ) ) - 1 from tab_name;
窗口函数
窗口函数支持在一个动态定义的数据子集上执行聚合操作或其他计算,常用于处理时间序列数据、排名、移动平均等问题。
函数目录
| 序号 | 函数名称 | 函数功能 |
| 1 | CUME_DIST | 计算累计分布。 |
| 2 | FIRST_VALUE | 取当前行所对应窗口的第一条数据的值。 |
| 3 | LAST_VALUE | 取当前行所对应窗口的最后一条数据的值。 |
| 4 | LAG | 取当前行往前第 N 行数据的值。 |
| 5 | LEAD | 取当前行往后第 N 行数据的值。 |
| 6 | ROW_NUMBER | 计算行号。从 1 开始递增。 |
| 7 | RANK | 计算排名。排名可能不连续。 |
| 8 | DENSE_RANK | 计算排名。排名是连续的。 |
| 9 | PERCENT_RANK | 计算排名。输出百分比格式。 |
| 10 | NTILE | 将数据顺序切分成 N 等份,返回数据所在等份的编号(从 1 到 N)。 |
| 11 | NTH_VALUE | 取当前行所对应窗口的第 N 条数据的值。 |
使用限制
窗口函数的使用限制如下:
- 窗口函数只能出现在
select语句中 - 窗口函数中不能嵌套使用窗口函数和聚合函数
- 窗口函数不能和同级别的聚合函数一起使用
窗口范围
在 SELECT 语句中加入窗口函数,计算窗口函数的结果时,数据会按照窗口定义中的 partition by 和 order by 语句进行分区和排序。
如果没有 partition by 语句,则仅有一个分区,包含全部数据。
如果没有 order by 语句,则分区内的数据会按照任意顺序排布,最终生成一个数据流。之后对于每一行数据(当前行),会按照窗口定义中的 frame_clause 从数据流中截取一段数据,构成当前行的窗口。
窗口函数会根据窗口中包含的数据,计算得到窗口函数针对当前行对应的输出结果。窗口范围可参考 Oracle 数据库分析函数总结。
假设表 tbl 结构为 pid: bigint, oid: bigint, rid: bigint,表中包含如下数据:
+------------+------------+------------+ | pid | oid | rid | +------------+------------+------------+ | 1 | NULL | 1 | | 1 | NULL | 2 | | 1 | 1 | 3 | | 1 | 1 | 4 | | 1 | 2 | 5 | | 1 | 4 | 6 | | 1 | 7 | 7 | | 1 | 11 | 8 | | 2 | NULL | 9 | | 2 | NULL | 10 | +------------+------------+------------+
- rows between unbounded preceding and current row
-- 表示分区的第一行和当前行 select pid ,oid ,rid ,collect_list(rid) over(partition by pid order by oid rows between unbounded preceding and current row) as window from tbl; +------------+------------+------------+---------------------------+ | pid | oid | rid | window | +------------+------------+------------+---------------------------+ | 1 | NULL | 1 | [1] | | 1 | NULL | 2 | [1, 2] | | 1 | 1 | 3 | [1, 2, 3] | | 1 | 1 | 4 | [1, 2, 3, 4] | | 1 | 2 | 5 | [1, 2, 3, 4, 5] | | 1 | 4 | 6 | [1, 2, 3, 4, 5, 6] | | 1 | 7 | 7 | [1, 2, 3, 4, 5, 6, 7] | | 1 | 11 | 8 | [1, 2, 3, 4, 5, 6, 7, 8] | | 2 | NULL | 9 | [9] | | 2 | NULL | 10 | [9, 10] | +------------+------------+------------+---------------------------+
- rows between unbounded preceding and unbounded following
-- 表示分区的第一行和最后一行 select pid ,oid ,rid ,collect_list(rid) over(partition by pid order by oid rows between unbounded preceding and unbounded following) as window from tbl; +------------+------------+------------+--------------------------+ | pid | oid | rid | window | +------------+------------+------------+--------------------------+ | 1 | NULL | 1 | [1, 2, 3, 4, 5, 6, 7, 8] | | 1 | NULL | 2 | [1, 2, 3, 4, 5, 6, 7, 8] | | 1 | 1 | 3 | [1, 2, 3, 4, 5, 6, 7, 8] | | 1 | 1 | 4 | [1, 2, 3, 4, 5, 6, 7, 8] | | 1 | 2 | 5 | [1, 2, 3, 4, 5, 6, 7, 8] | | 1 | 4 | 6 | [1, 2, 3, 4, 5, 6, 7, 8] | | 1 | 7 | 7 | [1, 2, 3, 4, 5, 6, 7, 8] | | 1 | 11 | 8 | [1, 2, 3, 4, 5, 6, 7, 8] | | 2 | NULL | 9 | [9, 10] | | 2 | NULL | 10 | [9, 10] | +------------+------------+------------+--------------------------+
- rows between 1 following and 3 following
-- 表示分区当前行的第后一行和当前行的第后三行 select pid ,oid ,rid ,collect_list(rid) over(partition by pid order by oid rows between 1 following and 3 following) as window from tbl; +------------+------------+------------+-----------+ | pid | oid | rid | window | +------------+------------+------------+-----------+ | 1 | NULL | 1 | [2, 3, 4] | | 1 | NULL | 2 | [3, 4, 5] | | 1 | 1 | 3 | [4, 5, 6] | | 1 | 1 | 4 | [5, 6, 7] | | 1 | 2 | 5 | [6, 7, 8] | | 1 | 4 | 6 | [7, 8] | | 1 | 7 | 7 | [8] | | 1 | 11 | 8 | NULL | -- 无后一行,返回 NULL | 2 | NULL | 9 | [10] | | 2 | NULL | 10 | NULL | -- 无后一行,返回 NULL +------------+------------+------------+-----------+
- rows between unbounded preceding and current row exclude current row
-- 表示分区的第一行和当前行,且剔除当前行 select pid ,oid ,rid ,collect_list(rid) over(partition by pid order by oid rows between unbounded preceding and current row exclude current row) as window from tbl; +------------+------------+------------+-----------------------+ | pid | oid | rid | window | +------------+------------+------------+-----------------------+ | 1 | NULL | 1 | NULL | | 1 | NULL | 2 | [1] | | 1 | 1 | 3 | [1, 2] | | 1 | 1 | 4 | [1, 2, 3] | | 1 | 2 | 5 | [1, 2, 3, 4] | | 1 | 4 | 6 | [1, 2, 3, 4, 5] | | 1 | 7 | 7 | [1, 2, 3, 4, 5, 6] | | 1 | 11 | 8 | [1, 2, 3, 4, 5, 6, 7] | | 2 | NULL | 9 | NULL | | 2 | NULL | 10 | [9] | +------------+------------+------------+-----------------------+
- rows between unbounded preceding and current row exclude group
-- 表示分区的第一行和当前行,且剔除整个 GROUP(即:剔除分区中与当前行具有相同 order by 值的所有数据) select pid ,oid ,rid ,collect_list(rid) over(partition by pid order by oid rows between unbounded preceding and current row exclude group) as window from tbl; +------------+------------+------------+-----------------------+ | pid | oid | rid | window | +------------+------------+------------+-----------------------+ | 1 | NULL | 1 | NULL | | 1 | NULL | 2 | NULL | | 1 | 1 | 3 | [1, 2] | | 1 | 1 | 4 | [1, 2] | | 1 | 2 | 5 | [1, 2, 3, 4] | | 1 | 4 | 6 | [1, 2, 3, 4, 5] | | 1 | 7 | 7 | [1, 2, 3, 4, 5, 6] | | 1 | 11 | 8 | [1, 2, 3, 4, 5, 6, 7] | | 2 | NULL | 9 | NULL | | 2 | NULL | 10 | NULL | +------------+------------+------------+-----------------------+
示例数据
CUME_DIST
命令格式
double cume_dist() over([partition_clause] [orderby_clause])
命令说明
求累计分布,相当于求分区中大于等于当前行的数据在分区中的占比。大小关系由 orderby_clause 判定。
返回值说明
返回 DOUBLE 类型。
使用示例
- 示例1:将所有职工根据部门(deptno)分组(作为开窗列),计算薪水(sal)在同一组内的前百分之几
select deptno ,ename ,sal ,concat(round(cume_dist() over(partition by deptno order by sal desc) * 100, 2), '%') as cume_dist from emp; +------------+------------+------------+------------+ | deptno | ename | sal | cume_dist | +------------+------------+------------+------------+ | 10 | JACCKA | 5000 | 33.33% | | 10 | KING | 5000 | 33.33% | | 10 | CLARK | 2450 | 66.67% | | 10 | WELAN | 2450 | 66.67% | | 10 | TEBAGE | 1300 | 100.0% | | 10 | MILLER | 1300 | 100.0% | | 20 | SCOTT | 3000 | 40.0% | | 20 | FORD | 3000 | 40.0% | | 20 | JONES | 2975 | 60.0% | | 20 | ADAMS | 1100 | 80.0% | | 20 | SMITH | 800 | 100.0% | | 30 | BLAKE | 2850 | 16.67% | | 30 | ALLEN | 1600 | 33.33% | | 30 | TURNER | 1500 | 50.0% | | 30 | MARTIN | 1250 | 83.33% | | 30 | WARD | 1250 | 83.33% | | 30 | JAMES | 950 | 100.0% | +------------+------------+------------+------------+
FIRST_VALUE
命令格式
first_value(<expr>[, <ignore_nulls>]) over ([partition_clause] [orderby_clause] [frame_clause])
命令说明
返回表达式 expr 在窗口的第一条数据上进行运算的结果。
参数说明
- expr:必填。待计算返回结果的表达式
- ignore_nulls:可选。BOOLEAN 类型。表示是否忽略 NULL 值。默认值为 False。当参数的值为 True 时,返回窗口中第一条非 NULL 的 expr 值
返回值说明
返回值类型同 expr 类型。
使用示例
- 示例1:不指定 order by,将所有职工根据部门分组,返回每组中的第一行数据
select deptno, ename, sal, first_value(sal) over(partition by deptno) as first_value from emp; +------------+------------+------------+-------------+ | deptno | ename | sal | first_value | +------------+------------+------------+-------------+ | 10 | TEBAGE | 1300 | 1300 | -- 当前窗口的开始行 | 10 | CLARK | 2450 | 1300 | | 10 | KING | 5000 | 1300 | | 10 | MILLER | 1300 | 1300 | | 10 | JACCKA | 5000 | 1300 | | 10 | WELAN | 2450 | 1300 | | 20 | FORD | 3000 | 3000 | -- 当前窗口的开始行 | 20 | SCOTT | 3000 | 3000 | | 20 | SMITH | 800 | 3000 | | 20 | ADAMS | 1100 | 3000 | | 20 | JONES | 2975 | 3000 | | 30 | TURNER | 1500 | 1500 | -- 当前窗口的开始行 | 30 | JAMES | 950 | 1500 | | 30 | ALLEN | 1600 | 1500 | | 30 | WARD | 1250 | 1500 | | 30 | MARTIN | 1250 | 1500 | | 30 | BLAKE | 2850 | 1500 | +------------+------------+------------+-------------+
- 示例2:指定 order by,将所有职工根据部门分组,返回每组中的第一行数据
select deptno, ename, sal, first_value(sal) over(partition by deptno order by sal desc) as first_value from emp; +------------+------------+------------+-------------+ | deptno | ename | sal | first_value | +------------+------------+------------+-------------+ | 10 | JACCKA | 5000 | 5000 | -- 当前窗口的开始行 | 10 | KING | 5000 | 5000 | | 10 | CLARK | 2450 | 5000 | | 10 | WELAN | 2450 | 5000 | | 10 | TEBAGE | 1300 | 5000 | | 10 | MILLER | 1300 | 5000 | | 20 | SCOTT | 3000 | 3000 | -- 当前窗口的开始行 | 20 | FORD | 3000 | 3000 | | 20 | JONES | 2975 | 3000 | | 20 | ADAMS | 1100 | 3000 | | 20 | SMITH | 800 | 3000 | | 30 | BLAKE | 2850 | 2850 | -- 当前窗口的开始行 | 30 | ALLEN | 1600 | 2850 | | 30 | TURNER | 1500 | 2850 | | 30 | MARTIN | 1250 | 2850 | | 30 | WARD | 1250 | 2850 | | 30 | JAMES | 950 | 2850 | +------------+------------+------------+-------------+
LAST_VALUE
命令格式
last_value(<expr>[, <ignore_nulls>]) over([partition_clause] [orderby_clause] [frame_clause])
命令说明
返回表达式 expr 在窗口的最后一条数据上进行运算的结果。
参数说明
- expr:必填。待计算返回结果的表达式
- ignore_nulls:可选。BOOLEAN 类型。表示是否忽略 NULL 值。默认值为 False。当参数的值为 True 时,返回窗口中最后一条非 NULL 的 expr 值
返回值说明
返回值类型同 expr 类型。
使用示例
- 示例1:不指定 order by,当前窗口为第一行到最后一行的范围,返回当前窗口的最后一行的值
select deptno, ename, sal, last_value(sal) over(partition by deptno) as last_value from emp; +------------+------------+------------+-------------+ | deptno | ename | sal | last_value | +------------+------------+------------+-------------+ | 10 | TEBAGE | 1300 | 2450 | | 10 | CLARK | 2450 | 2450 | | 10 | KING | 5000 | 2450 | | 10 | MILLER | 1300 | 2450 | | 10 | JACCKA | 5000 | 2450 | | 10 | WELAN | 2450 | 2450 | -- 当前窗口的最后一行 | 20 | FORD | 3000 | 2975 | | 20 | SCOTT | 3000 | 2975 | | 20 | SMITH | 800 | 2975 | | 20 | ADAMS | 1100 | 2975 | | 20 | JONES | 2975 | 2975 | -- 当前窗口的最后一行 | 30 | TURNER | 1500 | 2850 | | 30 | JAMES | 950 | 2850 | | 30 | ALLEN | 1600 | 2850 | | 30 | WARD | 1250 | 2850 | | 30 | MARTIN | 1250 | 2850 | | 30 | BLAKE | 2850 | 2850 | -- 当前窗口的最后一行 +------------+------------+------------+-------------+
- 示例2:指定 order by,当前窗口为第一行到当前行的范围。返回当前窗口的当前行的值
select deptno, ename, sal, last_value(sal) over(partition by deptno order by sal desc) as last_value from emp; +------------+------------+------------+-------------+ | deptno | ename | sal | last_value | +------------+------------+------------+-------------+ | 10 | JACCKA | 5000 | 5000 | -- 当前窗口的当前行 | 10 | KING | 5000 | 5000 | -- 当前窗口的当前行 | 10 | CLARK | 2450 | 2450 | -- 当前窗口的当前行 | 10 | WELAN | 2450 | 2450 | -- 当前窗口的当前行 | 10 | TEBAGE | 1300 | 1300 | -- 当前窗口的当前行 | 10 | MILLER | 1300 | 1300 | -- 当前窗口的当前行 | 20 | SCOTT | 3000 | 3000 | -- 当前窗口的当前行 | 20 | FORD | 3000 | 3000 | -- 当前窗口的当前行 | 20 | JONES | 2975 | 2975 | -- 当前窗口的当前行 | 20 | ADAMS | 1100 | 1100 | -- 当前窗口的当前行 | 20 | SMITH | 800 | 800 | -- 当前窗口的当前行 | 30 | BLAKE | 2850 | 2850 | -- 当前窗口的当前行 | 30 | ALLEN | 1600 | 1600 | -- 当前窗口的当前行 | 30 | TURNER | 1500 | 1500 | -- 当前窗口的当前行 | 30 | MARTIN | 1250 | 1250 | -- 当前窗口的当前行 | 30 | WARD | 1250 | 1250 | -- 当前窗口的当前行 | 30 | JAMES | 950 | 950 | -- 当前窗口的当前行 +------------+------------+------------+-------------+
注:last_value 和 first_value 在指定 order by 后,窗口的范围有所差异,需要注意。
- 示例3:指定 order by 及窗口范围,当前窗口为第一行到最后一行的范围。返回当前窗口的最后一行的值
select deptno ,ename ,sal ,last_value(sal) over(partition by deptno order by sal desc rows between unbounded preceding and unbounded following) as last_value from emp; +------------+------------+------------+-------------+ | deptno | ename | sal | last_value | +------------+------------+------------+-------------+ | 10 | JACCKA | 5000 | 1300 | | 10 | KING | 5000 | 1300 | | 10 | CLARK | 2450 | 1300 | | 10 | WELAN | 2450 | 1300 | | 10 | TEBAGE | 1300 | 1300 | | 10 | MILLER | 1300 | 1300 | -- 当前窗口的最后一行 | 20 | SCOTT | 3000 | 800 | | 20 | FORD | 3000 | 800 | | 20 | JONES | 2975 | 800 | | 20 | ADAMS | 1100 | 800 | | 20 | SMITH | 800 | 800 | -- 当前窗口的最后一行 | 30 | BLAKE | 2850 | 950 | | 30 | ALLEN | 1600 | 950 | | 30 | TURNER | 1500 | 950 | | 30 | MARTIN | 1250 | 950 | | 30 | WARD | 1250 | 950 | | 30 | JAMES | 950 | 950 | -- 当前窗口的最后一行 +------------+------------+------------+-------------+
LAG
命令格式
lag(<expr>[,bigint <offset>[, <default>]]) over([partition_clause] orderby_clause)
命令说明
返回当前行往前(朝分区头部方向)第 offset 行数据对应的表达式 expr 的值。表达式 expr 可以是列、列运算或者函数运算等。
参数说明
- expr:必填。待计算返回结果的表达式
- offset:可选。偏移量,BIGINT 类型常量,取值大于等于 1。值为 1 时表示前一行,以此类推,默认值为 1。输入值为 STRING 类型、DOUBLE 类型则隐式转换为 BIGINT 类型后进行运算
- default:可选。当 offset 指定的范围越界时的缺省值,常量,默认值为 NULL。需要与 expr 对应的数据类型相同。如果 expr 非常量,则基于当前行进行求值
返回值说明
返回值类型同 expr 类型。
使用示例
- 示例1:将所有职工根据部门(deptno)分组(作为开窗列),每位员工的薪水(sal)做偏移
select deptno, ename, sal, lag(sal, 1) over (partition by deptno order by sal) as sal_new from emp; +------------+------------+------------+------------+ | deptno | ename | sal | sal_new | +------------+------------+------------+------------+ | 10 | TEBAGE | 1300 | NULL | | 10 | MILLER | 1300 | 1300 | | 10 | CLARK | 2450 | 1300 | | 10 | WELAN | 2450 | 2450 | | 10 | KING | 5000 | 2450 | | 10 | JACCKA | 5000 | 5000 | | 20 | SMITH | 800 | NULL | | 20 | ADAMS | 1100 | 800 | | 20 | JONES | 2975 | 1100 | | 20 | SCOTT | 3000 | 2975 | | 20 | FORD | 3000 | 3000 | | 30 | JAMES | 950 | NULL | | 30 | MARTIN | 1250 | 950 | | 30 | WARD | 1250 | 1250 | | 30 | TURNER | 1500 | 1250 | | 30 | ALLEN | 1600 | 1500 | | 30 | BLAKE | 2850 | 1600 | +------------+------------+------------+------------+
LEAD
命令格式
lead(<expr>[, bigint <offset>[, <default>]]) over([partition_clause] orderby_clause)
命令说明
返回当前行往后(朝分区尾部方向)第 offset 行数据对应的表达式 expr 的值。表达式 expr 可以是列、列运算或者函数运算等。
参数说明
- expr:必填。待计算返回结果的表达式
- offset:可选。偏移量,BIGINT 类型常量,取值大于等于 0。值为 0 时表示当前行,为 1 时表示后一行,以此类推。默认值为 1。输入值为 STRING 类型、DOUBLE 类型则隐式转换为BIGINT类型后进行运算
- default:可选。当 offset 指定的范围越界时的缺省值,常量,默认值为 NULL。需要与 expr 对应的数据类型相同。如果 expr 非常量,则基于当前行进行求值
返回值说明
返回值类型同 expr 类型。
使用示例
- 示例1:将所有职工根据部门(deptno)分组(作为开窗列),每位员工的薪水(sal)做偏移
select deptno, ename, sal, lead(sal, 1) over (partition by deptno order by sal) as sal_new from emp; +------------+------------+------------+------------+ | deptno | ename | sal | sal_new | +------------+------------+------------+------------+ | 10 | TEBAGE | 1300 | 1300 | | 10 | MILLER | 1300 | 2450 | | 10 | CLARK | 2450 | 2450 | | 10 | WELAN | 2450 | 5000 | | 10 | KING | 5000 | 5000 | | 10 | JACCKA | 5000 | NULL | | 20 | SMITH | 800 | 1100 | | 20 | ADAMS | 1100 | 2975 | | 20 | JONES | 2975 | 3000 | | 20 | SCOTT | 3000 | 3000 | | 20 | FORD | 3000 | NULL | | 30 | JAMES | 950 | 1250 | | 30 | MARTIN | 1250 | 1250 | | 30 | WARD | 1250 | 1500 | | 30 | TURNER | 1500 | 1600 | | 30 | ALLEN | 1600 | 2850 | | 30 | BLAKE | 2850 | NULL | +------------+------------+------------+------------+
ROW_NUMBER
命令格式
row_number() over([partition_clause] [orderby_clause])
命令说明
计算当前行在分区中的行号,从 1 开始递增。
返回值说明
返回 BIGINT 类型。
使用示例
- 示例1:将所有职工根据部门(deptno)分组(作为开窗列),每个组内根据薪水(sal)做降序排序,获得职工在自己组内的序号
select deptno, ename, sal, row_number() over (partition by deptno order by sal desc) as nums from emp; +------------+------------+------------+------------+ | deptno | ename | sal | nums | +------------+------------+------------+------------+ | 10 | JACCKA | 5000 | 1 | | 10 | KING | 5000 | 2 | | 10 | CLARK | 2450 | 3 | | 10 | WELAN | 2450 | 4 | | 10 | TEBAGE | 1300 | 5 | | 10 | MILLER | 1300 | 6 | | 20 | SCOTT | 3000 | 1 | | 20 | FORD | 3000 | 2 | | 20 | JONES | 2975 | 3 | | 20 | ADAMS | 1100 | 4 | | 20 | SMITH | 800 | 5 | | 30 | BLAKE | 2850 | 1 | | 30 | ALLEN | 1600 | 2 | | 30 | TURNER | 1500 | 3 | | 30 | MARTIN | 1250 | 4 | | 30 | WARD | 1250 | 5 | | 30 | JAMES | 950 | 6 | +------------+------------+------------+------------+
RANK
命令格式
double cume_dist() over([partition_clause] [orderby_clause])
命令说明
计算当前行在分区中按照 orderby_clause 排序后所处的排名。从 1 开始计数。
返回值说明
返回 BIGINT 类型。返回值可能重复、且不连续(跳号)。具体的返回值为该行数据所在 GROUP 的第一条数据的 ROW_NUMBER() 值。未指定 orderby_clause 时,返回结果全为 1。
使用示例
- 示例1:将所有职工根据部门(deptno)分组(作为开窗列),每个组内根据薪水(sal)做降序排序,获得职工自己组内的序号
select deptno, ename, sal, rank() over (partition by deptno order by sal desc) as nums from emp; +------------+------------+------------+------------+ | deptno | ename | sal | nums | +------------+------------+------------+------------+ | 10 | JACCKA | 5000 | 1 | | 10 | KING | 5000 | 1 | | 10 | CLARK | 2450 | 3 | | 10 | WELAN | 2450 | 3 | | 10 | TEBAGE | 1300 | 5 | | 10 | MILLER | 1300 | 5 | | 20 | SCOTT | 3000 | 1 | | 20 | FORD | 3000 | 1 | | 20 | JONES | 2975 | 3 | | 20 | ADAMS | 1100 | 4 | | 20 | SMITH | 800 | 5 | | 30 | BLAKE | 2850 | 1 | | 30 | ALLEN | 1600 | 2 | | 30 | TURNER | 1500 | 3 | | 30 | MARTIN | 1250 | 4 | | 30 | WARD | 1250 | 4 | | 30 | JAMES | 950 | 6 | +------------+------------+------------+------------+
DENSE_RANK
命令格式
bigint dense_rank() over ([partition_clause] [orderby_clause])
命令说明
计算当前行在分区中按照 orderby_clause 排序后所处的排名。从 1 开始计数。分区中具有相同 order by 值的行的排名相等。每当 order by 值发生变化时,排名加 1。
返回值说明
返回 BIGINT 类型。返回值可能重复、且连续。未指定 orderby_clause 时,返回结果全为 1。
使用示例
- 示例1:将所有职工根据部门(deptno)分组(作为开窗列),每个组内根据薪水(sal)做降序排序,获得职工自己组内的序号
select deptno, ename, sal, dense_rank() over (partition by deptno order by sal desc) as nums from emp; +------------+------------+------------+------------+ | deptno | ename | sal | nums | +------------+------------+------------+------------+ | 10 | JACCKA | 5000 | 1 | | 10 | KING | 5000 | 1 | | 10 | CLARK | 2450 | 2 | | 10 | WELAN | 2450 | 2 | | 10 | TEBAGE | 1300 | 3 | | 10 | MILLER | 1300 | 3 | | 20 | SCOTT | 3000 | 1 | | 20 | FORD | 3000 | 1 | | 20 | JONES | 2975 | 2 | | 20 | ADAMS | 1100 | 3 | | 20 | SMITH | 800 | 4 | | 30 | BLAKE | 2850 | 1 | | 30 | ALLEN | 1600 | 2 | | 30 | TURNER | 1500 | 3 | | 30 | MARTIN | 1250 | 4 | | 30 | WARD | 1250 | 4 | | 30 | JAMES | 950 | 5 | +------------+------------+------------+------------+
PERCENT_RANK
命令格式
double percent_rank() over([partition_clause] [orderby_clause])
命令说明
计算当前行在分区中按照 orderby_clause 排序后的百分比排名。
返回值说明
返回 DOUBLE 类型,值域为 [0.0, 1.0]。具体的返回值等于 (rank - 1) / (partition_row_count - 1),其中:rank 为该行数据的 RANK 窗口函数的返回结果,partition_row_count 为该行数据所属分区的数据行数。当分区中只有一行数据时,输出结果为 0.0。
使用示例
- 示例1:计算员工薪水在组内的百分比排名
select deptno, ename, sal, percent_rank() over (partition by deptno order by sal desc) as sal_new from emp; +------------+------------+------------+------------+ | deptno | ename | sal | sal_new | +------------+------------+------------+------------+ | 10 | JACCKA | 5000 | 0.0 | | 10 | KING | 5000 | 0.0 | | 10 | CLARK | 2450 | 0.4 | | 10 | WELAN | 2450 | 0.4 | | 10 | TEBAGE | 1300 | 0.8 | | 10 | MILLER | 1300 | 0.8 | | 20 | SCOTT | 3000 | 0.0 | | 20 | FORD | 3000 | 0.0 | | 20 | JONES | 2975 | 0.5 | | 20 | ADAMS | 1100 | 0.75 | | 20 | SMITH | 800 | 1.0 | | 30 | BLAKE | 2850 | 0.0 | | 30 | ALLEN | 1600 | 0.2 | | 30 | TURNER | 1500 | 0.4 | | 30 | MARTIN | 1250 | 0.6 | | 30 | WARD | 1250 | 0.6 | | 30 | JAMES | 950 | 1.0 | +------------+------------+------------+------------+
NTILE
命令格式
bigint ntile(bigint <N>) over ([partition_clause] [orderby_clause])
命令说明
用于将分区中的数据按照顺序切分成 N 等份,并返回数据所在等份的编号。如果分区中的数据不能被均匀地切分成 N 等份时,最前面的等份(编号较小的)会优先多分配 1 条数据。
参数说明
- N:必填。切片数量。BIGINT 类型
返回值说明
返回 BIGINT 类型。
使用示例
- 示例1:将所有职工根据部门按薪水(sal)从高到低切分为3组,并获得职工自己所在组的序号
select deptno, ename, sal, ntile(3) over (partition by deptno order by sal desc) as nt3 from emp; +------------+------------+------------+------------+ | deptno | ename | sal | nt3 | +------------+------------+------------+------------+ | 10 | JACCKA | 5000 | 1 | | 10 | KING | 5000 | 1 | | 10 | CLARK | 2450 | 2 | | 10 | WELAN | 2450 | 2 | | 10 | TEBAGE | 1300 | 3 | | 10 | MILLER | 1300 | 3 | | 20 | SCOTT | 3000 | 1 | | 20 | FORD | 3000 | 1 | | 20 | JONES | 2975 | 2 | | 20 | ADAMS | 1100 | 2 | | 20 | SMITH | 800 | 3 | | 30 | BLAKE | 2850 | 1 | | 30 | ALLEN | 1600 | 1 | | 30 | TURNER | 1500 | 2 | | 30 | MARTIN | 1250 | 2 | | 30 | WARD | 1250 | 3 | | 30 | JAMES | 950 | 3 |
NTH_VALUE
命令格式
nth_value(<expr>, <number> [, <ignore_nulls>]) over ([partition_clause] [orderby_clause] [frame_clause])
命令说明
返回表达式 expr 在窗口的第 N 条数据进行运算的结果。
参数说明
- expr:必填。待计算返回结果的表达式
- number:必填。BIGINT 类型。大于等于 1 的整数。值为 1 时与
FIRST_VALUE等价 - ignore_nulls:可选。BOOLEAN 类型。表示是否忽略 NULL 值。默认值为 False。当参数的值为 True 时,返回窗口中第 N 条非 NULL 的 expr 值
返回值说明
返回值类型同 expr 类型。
使用示例
- 示例1:将所有职工根据部门分组,返回每组中的第 6 行数据
-- 不指定 order by,当前窗口为第一行到最后一行的范围,返回当前窗口第 6 行的值 select deptno, ename, sal, nth_value(sal,6) over (partition by deptno) as nth_value from emp; +------------+------------+------------+------------+ | deptno | ename | sal | nth_value | +------------+------------+------------+------------+ | 10 | TEBAGE | 1300 | 2450 | | 10 | CLARK | 2450 | 2450 | | 10 | KING | 5000 | 2450 | | 10 | MILLER | 1300 | 2450 | | 10 | JACCKA | 5000 | 2450 | | 10 | WELAN | 2450 | 2450 | -- 当前窗口的第 6 行 | 20 | FORD | 3000 | NULL | | 20 | SCOTT | 3000 | NULL | | 20 | SMITH | 800 | NULL | | 20 | ADAMS | 1100 | NULL | | 20 | JONES | 2975 | NULL | -- 当前窗口的没有第 6 行,返回 NULL | 30 | TURNER | 1500 | 2850 | | 30 | JAMES | 950 | 2850 | | 30 | ALLEN | 1600 | 2850 | | 30 | WARD | 1250 | 2850 | | 30 | MARTIN | 1250 | 2850 | | 30 | BLAKE | 2850 | 2850 | -- 当前窗口的第 6 行 +------------+------------+------------+------------+
- 指定 order by,当前窗口为第一行到当前行的范围,返回当前窗口第 6 行的值
select deptno, ename, sal, nth_value(sal,6) over (partition by deptno order by sal) as nth_value from emp; +------------+------------+------------+------------+ | deptno | ename | sal | nth_value | +------------+------------+------------+------------+ | 10 | TEBAGE | 1300 | NULL | | 10 | MILLER | 1300 | NULL | -- 当前窗口只有 2 行,第 6 行超过了窗口长度 | 10 | CLARK | 2450 | NULL | | 10 | WELAN | 2450 | NULL | | 10 | KING | 5000 | 5000 | | 10 | JACCKA | 5000 | 5000 | | 20 | SMITH | 800 | NULL | | 20 | ADAMS | 1100 | NULL | | 20 | JONES | 2975 | NULL | | 20 | SCOTT | 3000 | NULL | | 20 | FORD | 3000 | NULL | | 30 | JAMES | 950 | NULL | | 30 | MARTIN | 1250 | NULL | | 30 | WARD | 1250 | NULL | | 30 | TURNER | 1500 | NULL | | 30 | ALLEN | 1600 | NULL | | 30 | BLAKE | 2850 | 2850 | +------------+------------+------------+------------+
聚合函数
聚合(Aggregate)函数的输入与输出是多对一的关系,即将多条输入记录聚合成一条输出值,可以与 MaxCompute SQL 中的 group by 语句配合使用。
函数目录
| 序号 | 函数名称 | 函数功能 |
| 1 | ARG_MAX | 返回指定列的最大值对应行的列值。 |
| 2 | ARG_MIN | 返回指定列的最小值对应行的列值。 |
| 3 | COLLECT_LIST | 将指定的列聚合为一个数组。 |
| 4 | COLLECT_SET | 将指定的列聚合为一个无重复元素的数组。 |
| 5 | COUNT_IF | 计算指定表达式为 True 的记录数。 |
| 6 | COVAR_SAMP | 计算指定两个数值列的样本协方差。 |
| 7 | MEDIAN | 计算中位数。 |
| 8 | PERCENTILE | 计算精确百分位数,适用于小数据量。 |
| 9 | STDDEV_SAMP | 计算样本标准差。 |
| 10 | VAR_SAMP | 计算指定数值列的样本方差。 |
| 11 | WM_CONCAT | 用指定的分隔符连接字符串。 |
示例数据
ARG_MAX
命令格式
arg_max(<valueToMaximize>, <valueToReturn>)
命令说明
返回 valueToMaximize 最大值对应行的 valueToReturn。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- valueToMaximize:必填。可以为任意类型
- valueToReturn:必填。可以为任意类型
返回值说明
返回值类型和 valueToReturn 类型相同,如果存在多行最大值时,随机返回最大值中的一行对应的值。valueToMaximize 值为 NULL 时,该行不参与计算。
使用示例
- 示例1:返回薪资最高的员工姓名
select arg_max(sal, ename) from emp; +------------+ | _c0 | +------------+ | KING | +------------+
示例2:与 group by 配合使用,对所有职工按照部门(deptno)进行分组,并返回各组中薪资最高职工姓名
select deptno, arg_max(sal, ename) from emp group by deptno; +------------+------------+ | deptno | _c1 | +------------+------------+ | 10 | KING | | 20 | SCOTT | | 30 | BLAKE | +------------+------------+
ARG_MIN
命令格式
arg_min(<valueToMinimize>, <valueToReturn>)
命令说明
返回 valueToMinimize 最小值对应行的 valueToReturn。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- valueToMinimize:必填。可以为任意类型
- valueToReturn:必填。可以为任意类型
返回值说明
返回值类型和 valueToReturn 类型相同,如果存在多行最小值时,随机返回最小值其中的一行对应的值。valueToMinimize 值为 NULL 时,该行不参与计算。
使用示例
- 示例1:返回薪资最低的员工姓名
select arg_min(sal, ename) from emp; +------------+ | _c0 | +------------+ | SMITH | +------------+
- 示例2:与
group by配合使用,对所有职工按照部门(deptno)进行分组,并返回各组中薪资最低职工姓名
select deptno, arg_min(sal, ename) from emp group by deptno; +------------+------------+ | deptno | _c1 | +------------+------------+ | 10 | MILLER | | 20 | SMITH | | 30 | JAMES | +------------+------------+
COLLECT_LIST
命令格式
array collect_list(<colname>)
命令说明
将 colname 指定的列值聚合为一个数组。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- colname:必填。表的列名称,可为任意类型
返回值说明
返回 ARRAY 类型。colname 值为 NULL 时,该行不参与计算。
使用示例
- 示例1:将所有职工薪资(sal)聚合为一个数组
select collect_list(sal) from emp; +--------------------------------------------------------------------------------------+ | _c0 | +--------------------------------------------------------------------------------------+ | [800,1600,1250,2975,1250,2850,2450,3000,5000,1500,1100,950,3000,1300,5000,2450,1300] | +--------------------------------------------------------------------------------------+
- 示例2:与
group by配合使用,对所有职工按照部门(deptno)进行分组,并将同组的职工薪资(sal)聚合为一个数组
select deptno, collect_list(sal) from emp group by deptno; +------------+---------------------------------+ | deptno | _c1 | +------------+---------------------------------+ | 10 | [2450,5000,1300,5000,2450,1300] | | 20 | [800,2975,3000,1100,3000] | | 30 | [1600,1250,1250,2850,1500,950] | +------------+---------------------------------+
- 示例3:与
group by配合使用,对所有职工按照部门(deptno)进行分组,并将同组的职工薪资(sal)去重后聚合为一个数组
select deptno, collect_list(distinct sal) from emp group by deptno; +------------+---------------------------+ | deptno | _c1 | +------------+---------------------------+ | 10 | [1300,2450,5000] | | 20 | [800,1100,2975,3000] | | 30 | [950,1250,1500,1600,2850] | +------------+---------------------------+
COLLECT_SET
命令格式
array collect_set(<colname>)
命令说明
将 colname 指定的列值聚合为一个无重复元素的数组。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- colname:必填。表的列名称,可以为任意类型
返回值说明
返回 ARRAY 类型。colname 值为 NULL 时,该行不参与计算。
使用示例
- 示例1:将所有职工薪资(sal)聚合为一个无重复值的数组
select collect_set(sal) from emp; +-------------------------------------------------------------+ | _c0 | +-------------------------------------------------------------+ | [800,950,1100,1250,1300,1500,1600,2450,2850,2975,3000,5000] | +-------------------------------------------------------------+
- 示例2:与
group by配合使用,对所有职工按照部门(deptno)进行分组,并将同组的职工薪资(sal)聚合为一个无重复值的数组
select deptno, collect_set(sal) from emp group by deptno; +------------+---------------------------+ | deptno | _c1 | +------------+---------------------------+ | 10 | [1300,2450,5000] | | 20 | [800,1100,2975,3000] | | 30 | [950,1250,1500,1600,2850] | +------------+---------------------------+
COUNT_IF
命令格式
bigint count_if(boolean <expr>)
命令说明
计算 expr 值为 True 的记录数。
参数说明
- expr:必填。BOOLEAN 类型表达式
返回值说明
返回 BIGINT 类型。expr 值为 False 或 expr 中指定的列的值为 NULL 时,该行不参与计算。
使用示例
- 示例1:计算表达式
sal > 1000和sal <= 1000的记录数
select count_if(sal > 1000), count_if(sal <= 1000) from emp; +------------+------------+ | _c0 | _c1 | +------------+------------+ | 15 | 2 | +------------+------------+
COVAR_SAMP
命令格式
double covar_samp(<colname1>, <colname2>)
命令说明
计算指定两个数值列的样本协方差。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- colname1、colname2:必填。数据类型为数值类型的列。其他类型返回 NULL
使用示例
- 示例1:计算 sal 列与 sal_new 列的样本协方差
-- 在示例表 emp 中执行如下命令追加数据 alter table emp add columns (sal_new bigint); insert overwrite table emp select empno, ename, job, mgr, hiredate, sal, comm, deptno, sal+1000 from emp; select covar_samp(sal, sal_new) from emp; +--------------------+ | _c0 | +--------------------+ | 1694209.5588235292 | +--------------------+
- 示例2:与
group by配合使用,对所有职工按照部门(deptno)进行分组,并计算同组职工 sal 列与 sal_new 列的样本协方差
select deptno, covar_samp(sal, sal_new) from emp group by deptno; +------------+--------------------+ | deptno | _c1 | +------------+--------------------+ | 10 | 2868666.6666666665 | | 20 | 1261875.0 | | 30 | 446666.6666666666 | +------------+--------------------+
MEDIAN
命令格式
double median(double <colname>) decimal median(decimal <colname>)
命令说明
计算中位数。
参数说明
- colname:必填。列值可以为 DOUBLE 或 DECIMAL 类型。如果输入为 STRING 或 BIGINT 类型,会隐式转换为 DOUBLE 类型后参与运算
返回值说明
如果 colname 值为 NULL 时,该行不参与计算。
使用示例
- 示例1:计算所有职工的薪资(sal)中位数
select median(sal) from emp; +------------+ | _c0 | +------------+ | 1600.0 | +------------+
PERCENTILE
命令格式
double percentile(bigint <colname>, <p>)
命令说明
计算精确百分位数,适用于小数据量。先对指定列升序排列,然后取精确的第 p 位百分数。p 必须在 0 和 1 之间。percentile 是从编号 0 开始计算,例如某列数据为 100、200、300,列数据的编号顺序为 0、1、2,计算该列的 0.3 百分位点,percentile 结果是 2×0.3=0.6,即值位于编号 0 和 1之间,结果为 100+(200-100)×0.6=160。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- colname:必填。值为 BIGINT 类型的列
- p:必填。需要精确的百分位数。取值为 [0.0, 1.0]
返回值说明
返回 DOUBLE 或 ARRAY 类型。
使用示例
- 示例1:计算 0.3 百分位的薪资(sal)
select percentile(sal, 0.3) from emp; +------------+ | _c0 | +------------+ | 1290.0 | +------------+
- 示例2:与
group by配合使用,对所有职工按照部门(deptno)进行分组,并计算同组职工 0.3 百分位的薪资(sal)
select deptno, percentile(sal, 0.3) from emp group by deptno; +------------+------------+ | deptno | _c1 | +------------+------------+ | 10 | 1875.0 | | 20 | 1475.0 | | 30 | 1250.0 | +------------+------------+
- 示例3:与
group by配合使用,对所有职工按照部门(deptno)进行分组,并计算同组职工 0.3、0.5、0.8 百分位的薪资(sal)
select deptno, percentile(sal, array(0.3, 0.5, 0.8)) from emp group by deptno; +------------+------------------------+ | deptno | _c1 | +------------+------------------------+ | 10 | [1875.0,2450.0,5000.0] | | 20 | [1475.0,2975.0,3000.0] | | 30 | [1250.0,1375.0,1600.0] | +------------+------------------------+
STDDEV_SAMP
命令格式
double stddev_samp(double <colname>) decimal stddev_samp(decimal <colname>)
命令说明
计算样本标准差。
参数说明
- colname:必填。列值可以为 DOUBLE 或 DECIMAL 类型。如果输入为 STRING 或 BIGINT 类型,会隐式转换为 DOUBLE 类型后参与运算
返回值说明
如果 colname 值为 NULL 时,该行不参与计算。
使用示例
- 示例1:计算所有职工的薪资(sal)的样本标准差
select stddev_samp(sal) from emp; +--------------------+ | _c0 | +--------------------+ | 1301.6180541247609 | +--------------------+
- 示例2:与
group by配合使用,对所有职工按照部门(deptno)进行分组,计算各部门员工的薪资(sal)样本标准差
select deptno, stddev_samp(sal) from emp group by deptno; +------------+--------------------+ | deptno | _c1 | +------------+--------------------+ | 10 | 1693.7138680032901 | | 20 | 1123.3320969330487 | | 30 | 668.3312551921141 | +------------+--------------------+
VAR_SAMP
命令格式
double var_samp(<colname>)
命令说明
计算指定数值列的样本方差。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- colname:必填。数据类型为数值的列。其他类型返回 NULL
返回值说明
返回 DOUBLE 类型。
使用示例
- 示例1:计算所有职工薪资(sal)的样本方差
select var_samp(sal) from emp; +--------------------+ | _c0 | +--------------------+ | 1694209.5588235292 | +--------------------+
- 示例2:与
group by配合使用,对所有职工按照部门(deptno)进行分组,并计算同组职工薪资(sal)的样本方差
select deptno, var_samp(sal) from emp group by deptno; +------------+-------------------+ | deptno | _c1 | +------------+-------------------+ | 10 | 2868666.666666667 | | 20 | 1261875.0 | | 30 | 446666.6666666667 | +------------+-------------------+
WM_CONCAT
命令格式
string wm_concat(string <separator>, string <colname>)
命令说明
用指定的 separator 做分隔符,连接 colname 中的值。
参数说明
- separator:必填。STRING 类型常量,分隔符
- colname:必填。STRING 类型。如果输入为 BIGINT、DOUBLE 或 DATETIME 类型,会隐式转换为 STRING 类型后参与运算
返回值说明(注:使用 group by 分组,组内返回值不排序)
返回 STRING 类型。返回规则如下:
- separator 非 STRING 类型常量时,返回报错
- colname 非 STRING、BIGINT、DOUBLE 或 DATETIME 类型时,返回报错
- colname 值为 NULL 时,该行不会参与计算
使用示例
- 示例1:对所有职工的姓名(ename)进行合并
select wm_concat(',', ename) from emp; +---------------------------------------------------------------------------------------------------------+ | _c0 | +---------------------------------------------------------------------------------------------------------+ | SMITH,ALLEN,WARD,JONES,MARTIN,BLAKE,CLARK,SCOTT,KING,TURNER,ADAMS,JAMES,FORD,MILLER,JACCKA,WELAN,TEBAGE | +---------------------------------------------------------------------------------------------------------+
- 示例2:与
group by配合使用,对所有职工按照部门(deptno)进行分组,并将同组的职工姓名(ename)进行合并
select deptno, wm_concat(',', ename) from emp group by deptno order by deptno; +------------+---------------------------------------+ | deptno | _c1 | +------------+---------------------------------------+ | 10 | CLARK,KING,MILLER,JACCKA,WELAN,TEBAGE | | 20 | SMITH,JONES,SCOTT,ADAMS,FORD | | 30 | ALLEN,WARD,MARTIN,BLAKE,TURNER,JAMES | +------------+---------------------------------------+
- 示例3:与
group by配合使用,对所有职工按照部门(deptno)进行分组,并将同组的薪资(sal)去重后进行合并
select deptno, wm_concat(distinct ',', sal) from emp group by deptno order by deptno; +------------+-------------------------+ | deptno | _c1 | +------------+-------------------------+ | 10 | 1300,2450,5000 | | 20 | 1100,2975,3000,800 | | 30 | 1250,1500,1600,2850,950 | +------------+-------------------------+
- 示例4:与
group by、order by配合使用,对所有职工按照部门(deptno)进行分组,并将同组的薪资(sal)进行合并排序
select deptno, wm_concat(',',sal) within group(order by sal) from emp group by deptno order by deptno; +------------+-----------------------------+ |deptno |_c1 | +------------+-----------------------------+ |10 |1300,1300,2450,2450,5000,5000| |20 |800,1100,2975,3000,3000 | |30 |950,1250,1250,1500,1600,2850 | +------------+-----------------------------+
字符串函数
当需要对存储在表中的字符串数据进行截取、拼接、转化、比较、搜索等操作,可以使用 MaxCompute 支持的字符串函数对指定字符串进行灵活处理。
函数目录
| 序号 | 函数名称 | 函数功能 |
| 1 | CHR | 将指定 ASCII 码转换成字符。 |
| 2 | CONCAT_WS | 将参数中的所有字符串按照指定的分隔符连接在一起。 |
| 3 | INSTR | 计算 A 字符串在 B 字符串中的位置 |
| 4 | SUBSTR | 返回 STRING 类型字符串从指定位置开始,指定长度的子串 |
| 5 | SUBSTRING_INDEX | 截取字符串指定分隔符前的字符串。 |
| 6 | REPEAT | 返回将字符串重复指定次数后的结果。 |
| 7 | REPLACE | 将字符串中与指定字符串匹配的子串替换为另一字符串。 |
| 8 | REGEXP_COUNT | 计算字符串从指定位置开始,匹配指定规则的子串数。 |
| 9 | REGEXP_REPLACE | 将字符串中,与指定规则在指定次数匹配的子串替换为另一字符串。 |
| 10 | REGEXP_SUBSTR | 返回字符串中,从指定位置开始,与指定规则匹配指定次数的子串。 |
| 11 | SPLIT | 按照分隔符分割字符串后返回数组。 |
| 12 | SPLIT_PART | 按照分隔符拆分字符串,返回指定部分的子串。 |
正则表达式字符组
MaxCompute SQL 中正则表达式支持如下字符组。
| 字符组 | 说明 | 范围 |
| [[:alnum:]] | 字母字符和数字字符 | [a-zA-Z0-9] |
| [[:alpha:]] | 字母 | [a-zA-Z] |
| [[:blank:]] | 空格字符和制表符 | [\t] |
| [[:cntrl:]] | 控制字符 | [\x00-\x1F\x7F] |
| [[:digit:]] | 数字字符 | [0-9] |
| [[:graph:]] | 空白字符之外的字符 | [\x21-\x7E] |
| [[:lower:]] | 小写字母字符 | [a-z] |
| [[:punct:]] | 标点符号 | [][!”#$%&’()*+,./:;<=>? @\^_`{|}~-] |
| [[:space:]] | 空白字符 | [\t\r\n\v\f] |
| [[:upper:]] | 大写字母字符 | [A-Z] |
示例数据
CHR
命令格式
string chr(bigint <ascii>)
命令说明
将指定 ASCII 码转换为字符。
注:
- 换行符 chr(10)
- 回车符 chr(13)
- 空格符 chr(32)
参数说明
- ascii:必填。BIGINT 类型的 ASCII 值。取值范围为 0~128。如果输入为 STRING、DOUBLE 或 DECIMAL 类型,则会隐式转换为BIGINT类型后参与运算
返回值说明
返回 STRING 类型。返回规则如下:
- ascii 值不在取值范围内时,返回报错
- ascii 非 BIGINT、STRING、DOUBLE 或 DECIMAL 类型时,返回报错
- ascii 值为 NULL 时,返回 NULL
使用示例
- 示例1:将 ASCII 码 100 转换为字符
-- 返回 d select chr(100);
- 示例2:输入参数为 NULL
-- 返回 NULL select chr(null);
- 示例3:输入为 STRING 类型字符
-- 隐式转换为 BIGINT 类型后参与运算,返回 d select chr('100');
CONCAT_WS
命令格式
string concat_ws(string <separator>, string <str1>, string <str2>[,...]) string concat_ws(string <separator>, array<string> <a>)
命令说明
返回将参数中的所有字符串或 ARRAY 数组中的元素按照指定的分隔符连接在一起的结果。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- separator:必填。STRING 类型的分隔符
- str1、str2:至少要指定2个字符串。STRING 类型。如果输入为 BIGINT、DECIMAL、DOUBLE 或 DATETIME 类型,则会隐式转换为 STRING 类型后参与运算
- a:必填。ARRAY 数组。数组中的元素为 STRING 类型
返回值说明
返回 STRING 类型或 STRUCT 类型。返回规则如下:
- str1 或 str2 为非 STRING、BIGINT、DECIMAL、DOUBLE 或 DATETIME 类型时,返回报错
- 如果没有输入参数或任一输入参数值为 NULL,返回 NULL
使用示例
- 示例1:将字符串 name 和 hanmeimei 通过
:连接
-- 返回n ame:hanmeimei select concat_ws(':','name','hanmeimei');
- 示例2:任一输入参数为 NULL
-- 返回 NULL select concat_ws(':','avg',null,'34');
- 示例3:将 ARRAY 数组
array('name', 'hanmeimei')中的元素通过:连接
-- 返回 name:hanmeimei select concat_ws(':', array('name', 'hanmeimei'));
INSTR
命令格式
bigint instr(string <str1>, string <str2>[, bigint <start_position>[, bigint <nth_appearance>]])
命令说明
计算子串 str2 在字符串 str1 中的位置。
参数说明
- str1:必填。STRING 类型。待搜索的目标字符串。如果输入为 BIGINT、DOUBLE、DECIMAL 或 DATETIME 类型,则会隐式转换为 STRING 类型后参与运算,其他类型会返回报错
- str2:必填。STRING 类型。待匹配的子串。如果输入为 BIGINT、DOUBLE、DECIMAL 或 DATETIME 类型,则会隐式转换为 STRING 类型后参与运算,其他类型会返回报错
- start_position:可选。BIGINT 类型,其他类型会返回报错。表示从 str1 的第几个字符开始搜索,默认起始位置是第一个字符位置 1。当 start_position 为负数时表示开始位置是从字符串的结尾往前倒数,最后一个字符是 -1,依次往前倒数
- nth_appearance:可选。BIGINT 类型,大于 0。表示 str2 在 str1 中第 nth_appearance 次匹配的位置。如果 nth_appearance 为其他类型或小于等于 0,则返回报错
返回值说明
返回 BIGINT 类型。返回规则如下:
- 如果在 str1 中未找到 str2,则返回 0
- 如果 str2 为空串,则总能匹配成功,例如
select instr('abc', '');会返回 1 - str1、str2、start_position 或 nth_appearance 值为 NULL 时,返回 NULL
使用示例
- 示例1:计算字符
e在字符串Tech on the net中的位置
-- 返回 2 select instr('Tech on the net', 'e');
- 示例2:计算子串
on在字符串Tech on the net中的位置
-- 返回 6 select instr('Tech on the net', 'on');
- 示例3:计算字符
e在字符串Tech on the net中,从第 3 个字符开始,第 2 次出现的位置
-- 返回 14 select instr('Tech on the net', 'e', 3, 2);
- 示例4:任一输入参数为NULL
-- 返回 NULL select instr('Tech on the net', null);
SUBSTR
命令格式
string substr(string <str>, bigint <start_position>[, bigint <length>])
命令说明
返回字符串 str 从 start_position 开始,长度为 length 的子串。
参数说明
- str:必填。STRING 类型。如果输入为 BIGINT、DECIMAL、DOUBLE 或 DATETIME 类型,则会隐式转换为 STRING 类型后参与运算
- start_position:必填。BIGINT 类型,默认起始位置为 1;当为负数时,表示开始位置是从字符串的结尾往前倒数,最后一个字符是 -1,依次往前倒数
- length:可选。BIGINT 类型,表示子串的长度值。值必须大于 0
返回值说明
返回 STRING 类型。返回规则如下:
- str 为非 STRING、BIGINT、DECIMAL、DOUBLE 或 DATETIME 类型时,返回报错
- length 为非 BIGINT 类型或值小于等于 0 时,返回报错
- 当 length 被省略时,返回到 str 结尾的子串
- str、start_position 或 length 值为 NULL 时,返回 NULL
使用示例
示例1:返回字符串 abc 从指定位置开始,指定长度的子串
-- 返回 bc select substr('abc', 2); -- 返回 b select substr('abc', 2, 1); -- 返回 bc select substr('abc', -2 , 2);
- 示例2:任一输入参数为 NULL
-- 返回 NULL select substr('abc', null);
SUBSTRING_INDEX
命令格式
string substring_index(string <str>, string <separator>, int <count>)
命令说明
截取字符串 str 第 count 个分隔符之前的字符串。如果 count 为正,则从左边开始截取。如果 count 为负,则从右边开始截取。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- str:必填。STRING 类型。待截取的字符串
- separator:必填。STRING 类型的分隔符
- count:必填。INT 类型。指定分隔符位置
返回值说明
返回 STRING 类型。如果任一输入参数值为 NULL,返回 NULL。
使用示例
- 示例1:截取字符串
https://help.aliyun.com
-- 返回 https://help.aliyun select substring_index('https://help.aliyun.com', '.', 2); -- 返回 aliyun.com select substring_index('https://help.aliyun.com', '.', -2);
- 示例2:任一输入参数为 NULL
-- 返回 NULL select substring_index('https://help.aliyun.com', null, 2);
REPEAT
命令格式
string repeat(string <str>, bigint <n>)
命令说明
返回将 str 重复 n 次后的字符串。
参数说明
- str:必填。STRING 类型。如果输入为 BIGINT、DOUBLE、DECIMAL 或 DATETIME 类型,则会隐式转换为 STRING 类型后参与运算
- n:必填。BIGINT 类型。长度不超过 2 MB
返回值说明
返回 STRING 类型。返回规则如下:
- str 为非 STRING、BIGINT、DOUBLE、DECIMAL 或 DATETIME 类型时,返回报错
- n 为空时,返回报错
- str 或 n 值为 NULL 时,返回 NULL
使用示例
- 示例1:将字符串
abc重复5次
-- 返回 abcabcabcabcabc select repeat('abc', 5);
- 示例2:任一输入参数为 NULL
-- 返回 NULL select repeat('abc', null);
REPLACE
命令格式
string replace(string <str>, string <old>, string <new>)
命令说明
用 new 字符串替换 str 字符串中与 old 字符串完全重合的部分并返回替换后的 str。如果没有重合的字符串,返回原 str。此函数为 MaxCompute 2.0 扩展函数。
参数说明
- str:必填。STRING 类型。待替换的字符串
- old:必填。待比较的字符串
- new:必填。替换后的字符串
返回值说明
返回 STRING 类型。如果任一输入参数值为 NULL,返回 NULL。
使用示例
- 示例1:用字符串
12替换字符串ababab中与字符串abab完全重合的部分
-- 返回 12ab select replace('ababab', 'abab', '12');
- 示例2:任一输入参数为 NULL
-- 返回 NULL select replace('123abab456ab', null, 'abab');
REGEXP_COUNT
命令格式
bigint regexp_count(string <source>, string <pattern>[, bigint <start_position>])
命令说明
计算 source 中从 start_position 位置开始,匹配指定 pattern 的子串数。
参数说明
- source:必填。STRING 类型。待搜索的字符串,其他类型会返回报错
- pattern:必填。STRING 类型常量或正则表达式。待匹配的模型。pattern 为空串或其他类型时返回报错
- start_position:可选。BIGINT 类型常量,必须大于 0。其他类型或值小于等于 0 时返回报错。不指定时默认为 1,表示从 source 的第一个字符开始匹配
返回值说明
返回 BIGINT 类型。返回规则如下:
- 如果没有匹配成功,返回 0
- source、pattern 或 start_position 值为 NULL时,返回 NULL
使用示例
- 示例1:计算
abababc中从指定位置开始,匹配指定规则的子串数
-- 返回 1 select regexp_count('abababc', 'a.c'); -- 返回 2 select regexp_count('abababc', '[[:alpha:]]{2}', 3);
- 示例2:任一输入参数为NULL
-- 返回 NULL select regexp_count('abababc', null);
- 示例3:计算
:出现在 JSON 字符串{"account_id":123456789,"account_name":"allen","location":"hangzhou","bill":100}中的次数
-- 返回 4 select regexp_count('{"account_id":123456789,"account_name":"allen","location":"hangzhou","bill":100}', ':');
REGEXP_REPLACE
命令格式
string regexp_replace(string <source>, string <pattern>, string <replace_string>[, bigint <occurrence>])
命令说明
将 source 字符串中第 occurrence 次匹配 pattern 的子串替换成指定字符串 replace_string 后返回结果字符串。
参数说明
- source:必填。STRING 类型,待替换的字符串
- pattern:必填。STRING 类型常量或正则表达式。待匹配的模型。pattern 为空串时返回报错
- replace_string:必填。STRING 类型,将匹配 pattern 的字符串替换后的字符串
- occurrence:可选。BIGINT 类型常量,必须大于等于 0,表示将第 occurrence 次匹配的字符串替换为 replace_string,为 0 时表示替换所有匹配的子串。为其他类型或小于 0 时,返回报错。默认值为 0
返回值说明
返回 STRING 类型。返回规则如下:
- 当引用不存在的组时,其结果未定义
- 如果 replace_string 值为 NULL 且 pattern 有匹配,返回 NULL
- 如果 replace_string 值为 NULL 但 pattern 不匹配,返回原字符串
- source、pattern 或 occurrence 值为 NULL时,返回 NULL
使用示例
示例1:将字符串按照指定规则进行替换
-- 返回 Abcd select regexp_replace("abcd", "a", "A", 0); -- 返回 bcd select regexp_replace("abcd", "a", "", 0); -- 返回 19700101 select regexp_replace("1970-01-01", "-", "", 0); -- 返回 abc select regexp_replace("a1b2c3", "[0-9]", "", 0); -- 返回 a1b2c select regexp_replace("a1b2c3", "[0-9]", "", 3);
- 示例2:将
123.456.7890字符串中与([[:digit:]]{3})\\.([[:digit:]]{3})\\.([[:digit:]]{4})匹配的所有字符串替换为(\\1)\\2-\\3
-- 返回 (123)456-7890 select regexp_replace('123.456.7890', '([[:digit:]]{3})\\.([[:digit:]]{3})\\.([[:digit:]]{4})', '(\\1)\\2-\\3', 0);
- 示例3:将
abcd字符串中与指定规则匹配的字符串进行替换
-- 返回 a b c d select regexp_replace('abcd', '(.)', '\\1 ', 0); -- 返回 a bcd select regexp_replace('abcd', '(.)', '\\1 ', 1); -- 返回 d select regexp_replace("abcd", "(.*)(.)$", "\\2", 0);
- 示例4:假设表 url_set 中列名为URL的数据格式为
www.simple@xxx.com,且每行的xxx完全不同,现需要将列中www后的所有内容都替换掉
-- 返回结果为 wwwtest select regexp_replace(url, '(www)(.*)', 'wwwtest', 0) from url_set;
- 示例5:引用不存在的组
-- pattern 中只定义了一个组,引用的第二个组不存在 regexp_replace("abcd", "(.)", "\\2", 0)
REGEXP_SUBSTR
命令格式
string regexp_substr(string <source>, string <pattern>[, bigint <start_position>[, bigint <occurrence>]])
命令说明
返回从 start_position 位置开始,source 中第 occurrence 次匹配指定 pattern 的子串。
参数说明
- source:必填。STRING 类型。待搜索的字符串
- pattern:必填。STRING 类型常量或正则表达式。待匹配的模型
- start_position:可选。其他 BIGINT 常量,必须大于 0。不指定时默认为 1,表示从 source 的第一个字符开始匹配
- occurrence:可选。BIGINT 常量,必须大于 0。不指定时默认为 1,表示返回第一次匹配的子串
返回值说明
返回 STRING 类型。返回规则如下:
- 如果 pattern 为空字符串,返回报错
- 没有匹配时,返回 NULL
- start_position 或 occurrence 为非 BIGINT 类型或小于等于 0 时,返回报错
- source、pattern、start_position、occurrence 或 return_option 值为 NULL 时,返回 NULL
使用示例
- 示例1:返回
I love aliyun very much字符串中与指定规则匹配的字符串
-- 返回 aliyun select regexp_substr('I love aliyun very much', 'a[[:alpha:]]{5}'); -- 返回 have select regexp_substr('I have 2 apples and 100 bucks!', '[[:blank:]][[:alnum:]]*', 1, 1); -- 返回 2 select regexp_substr('I have 2 apples and 100 bucks!', '[[:blank:]][[:alnum:]]*', 1, 2);
- 示例2:任一输入参数为 NULL
-- 返回 NULL select regexp_substr('I love aliyun very much', null);
SPLIT
命令格式
split(<str>, <pat>, [<trimTailEmpty>])
命令说明
通过 pat 将 str 分割后返回数组。
参数说明
- str:必填。STRING 类型。指被分割的字符串
- pat:必填。STRING 类型的分隔符。支持正则表达式
- trimTailEmpty: 可选参数,默认值为 true,设置为 false 保留末尾空字符串
返回值说明
返回 ARRAY 数组。数组中的元素为 STRING 类型。
使用示例
-- 返回 ["a"," b"," c"] select split("a, b, c", ","); -- 默认不返回空字符串 select split("a, b, c,,", ","); -- 返回结果 +-----------------+ | _c0 | +-----------------+ | ["a"," b"," c"] | +-----------------+ -- 设置 trimTailEmpty 参数,返回空字符串 select split("a, b, c,,", ",", false); -- 返回结果 +-----------------------+ | _c0 | +-----------------------+ | ["a"," b"," c","",""] | +-----------------------+
SPLIT_PART
命令格式
string split_part(string <str>, string <separator>, bigint <start>[, bigint <end>])
命令说明
依照分隔符 separator 拆分字符串 str,返回从 start 部分到 end 部分的子串(闭区间)。
参数说明
- str:必填。STRING 类型。待拆分的字符串。如果是 BIGINT、DOUBLE、DECIMAL 或 DATETIME 类型,则会隐式转换为 STRING 类型后参与运算
- separator:必填。STRING 类型常量。拆分用的分隔符,可以是一个字符,也可以是一个字符串
- start:必填。BIGINT 类型常量,必须大 于0。表示返回段的开始编号(从 1 开始)
- end:BIGINT 类型常量,大于等于 start。表示返回段的截止编号,可省略,缺省时表示和 start 取值相等,返回 start 指定的段
返回值说明
返回STRING类型。返回规则如下:
- 如果 start 的值大于切分后实际的分段数,例如字符串拆分完有 6 个片段,start 大于 6,返回空串
- 如果 separator 不存在于 str 中,且 start 指定为 1,返回整个 str。如果 str 为空字符串,则输出空字符串
- 如果 separator 为空字符串,则返回原字符串 str
- 如果 end 大于片段个数,返回从 start 开始的子串
- str 为非 STRING、BIGINT、DOUBLE、DECIMAL 或 DATETIME 类型时,返回报错
- separator 为非 STRING 类型常量时,返回报错
- start 或 end 为非 BIGINT 类型常量时,返回报错
- 除 separator 外,如果任一参数值为 NULL,返回 NULL
使用示例
- 示例1:依照分隔符,拆分字符串
a,b,c,d,返回指定部分的子串
-- 返回 a select split_part('a,b,c,d', ',', 1); -- 返回 a,b select split_part('a,b,c,d', ',', 1, 2);
- 示例2:start 的值大于切分后实际的分段数
-- 返回空串 select split_part('a,b,c,d', ',', 10);
- 示例3:separator 不存在于 str 中
-- 返回 a,b,c,d select split_part('a,b,c,d', ':', 1); -- 返回空串 select split_part('a,b,c,d', ':', 2);
- 示例4:separator 为空串
-- 返回 a,b,c,d select split_part('a,b,c,d', '', 1);
- 示例5:end 的值大于切分后实际的分段数
-- 返回 b,c,d select split_part('a,b,c,d', ',', 2, 6);
- 示例6:除 separator 外,任一输入参数为NULL
-- 返回 NULL select split_part('a,b,c,d', ',', null);
加密函数
MaxCompute SQL 提供了加密函数和解密函数,可以根据实际需要选择合适的函数,进行加密或解密。
MaxCompute 数据加密能力介绍
单一密钥加密:支持生成单一密钥,需要自行保存生成的密钥,适用于对指定列做随机性加密或解密。
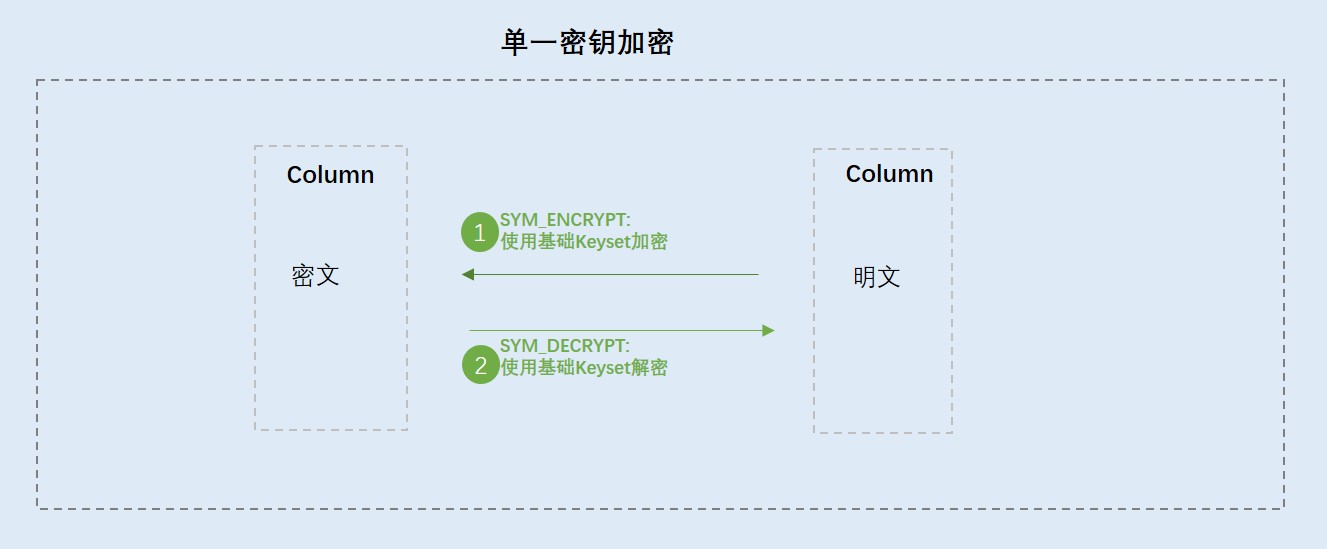
函数目录
| 序号 | 函数名称 | 函数功能 |
| 1 | SYM_ENCRYPT | 对表里的指定列做随机性加密,返回 BINARY 类型的密文。 |
| 2 | SYM_DECRYPT | 对表里的指定已经随机性加密的列做解密,返回 BINARY 类型的明文。 |
示例数据
SYM_ENCRYPT
命令格式
binary sym_encrypt(string|binary <value_to_encrypt>, binary <key> [,string <encryption_method> , [ string <additional_authenticated_data> ] ] )
命令说明
对表里的指定列做随机性加密。
参数说明
- value_to_encrypt:必填。待加密数据。目前只支持对 STRING 和 BINARY 类型的数据进行加密
- key:必填。加密使用的密钥。支持的数据类型为 BINARY,长度为 256bits
- encryption_method:可选。加密模式选择。目前只提供了一种加密模式,即 AES-GCM-256 加密算法,默认使用 AES-GCM-256
- additional_authenticated_data:可选。附加身份验证数据 AAD,可以用来验证数据的真实性和完整性。目前只支持 AEAD 的加密算法,比如 AES GCM 才支持 AAD
返回值说明
返回 BINARY 类型的密文。返回规则如下:
- 返回值中按顺序包含初始向量(IV),密文,带附加数据的加密和验证算法标签(AEAD Tag)
- 相同的明文和密码,每次生成的密文也是随机的不同的
使用示例
- 示例数据
-- 创建表 create table if not exists mf_user_info( id bigint, name string, gender string, id_card_no string, tel string ); -- 插入数据 insert overwrite table mf_user_info values (1, "bob" , "male" , "0001", "13900001234"), (2, "allen" , "male" , "0011", "13900001111"), (3, "kate" , "female" , "0111", "13900002222"), (4, "annie" , "female" , "1111", "13900003333"); -- 查询数据 select * from mf_user_info; +------------+------+--------+------------+------------+ | id | name | gender | id_card_no | tel | +------------+------+--------+------------+------------+ | 1 | bob | male | 0001 | 13900001234| | 2 | allen| male | 0011 | 13900001111| | 3 | kate | female | 0111 | 13900002222| | 4 | annie| female | 1111 | 13900003333| +------------+------+--------+------------+------------+
- 示例1:基于明文密钥加密
-- 使用 AEAD 加密算法,对 id_card_no 加密 insert overwrite table mf_user_info select id ,name ,gender ,base64 ( sym_encrypt ( id_card_no ,cast('b75585cf321cdcad42451690cdb7bfc4' as binary) ) ) as id_card_no ,tel from mf_user_info; -- 查询加密后的数据 select * from mf_user_info; +------------+------+--------+----------------------------------------------+------------+ | id | name | gender | id_card_no | tel | +------------+------+--------+----------------------------------------------+------------+ | 1 | bob | male | frgJZAEAQMeEuHqpS8lK9VxQhgPYpZ317V+oUla/xEc= | 13900001234| | 2 | allen| male | frgJZAIAQMeEuHqpLeXQfETsFSLJxBwHhPx6tpzWUg4= | 13900001111| | 3 | kate | female | frgJZAMAQMeEuHqpdphXAU6iWelWenlDnVy+R0HMvAY= | 13900002222| | 4 | annie| female | frgJZAQAQMeEuHqpR5c8bj21dYCeM0C25bLRZIrP71c= | 13900003333| +------------+------+--------+----------------------------------------------+------------+
- 示例2:使用 AAD 加密算法进行加密
-- 对 id_card_no 加密 insert overwrite table mf_user_info select id, ,name, ,gender, ,base64 ( sym_encrypt ( id_card_no ,cast('b75585cf321cdcad42451690cdb7bfc4' as binary) ,'AES-GCM-256' ,'test' ) ) as id_card_no, ,tel from mf_user_info; -- 查询加密后的数据 select * from mf_user_info; +------------+------+--------+----------------------------------------------+------------+ | id | name | gender | id_card_no | tel | +------------+------+--------+----------------------------------------------+------------+ | 1 | bob | male | frgJZAEAQMeEuHqpS8lK9VxQhgPYpZ317V+oUla/xEc= | 13900001234| | 2 | allen| male | frgJZAIAQMeEuHqpLeXQfETsFSLJxBwHhPx6tpzWUg4= | 13900001111| | 3 | kate | female | frgJZAMAQMeEuHqpdphXAU6iWelWenlDnVy+R0HMvAY= | 13900002222| | 4 | annie| female | frgJZAQAQMeEuHqpR5c8bj21dYCeM0C25bLRZIrP71c= | 13900003333| +------------+------+--------+----------------------------------------------+------------+
SYM_DECRYPT
命令格式
binary sym_decrypt(binary <value_to_decrypt>, binary <key> [,string <encryption_method> , [ string <additional_authenticated_data> ] ] )
命令说明
对表里的指定已经随机性加密的列做解密。
参数说明
- value_to_decrypt:必填。待解密数据。目前只支持对 BINARY 类型的数据进行解密
- key:必填。解密使用的密钥。支持的数据类型为 BINARY,长度为 256bits
- encryption_method:可选。数据用指定模式加密,解密时需要选择同样的模式进行解密
- additional_authenticated_data:可选。附加身份验证数据 AAD,可以用来验证数据的真实性和完整性,数据在加密时用了 ADD,解密时就需要输入 ADD
返回值说明
返回 BINARY 类型的明文,若有需要可以自行通过 CAST 将 BINARY 类型转换为 STRING 类型。
使用示例
- 示例1:解密明文密钥加密数据
-- 对 id_card_no 解密 insert overwrite table mf_user_info select id ,name ,gender ,sym_decrypt ( unbase64(id_card_no) ,cast('b75585cf321cdcad42451690cdb7bfc4' as binary) ,'AES-GCM-256' ,'test' ) as id_card_no, ,tel from mf_user_info; -- 查询解密后的明文数据 select * from mf_user_info; +------------+------+--------+------------+------------+ | id | name | gender | id_card_no | tel | +------------+------+--------+------------+------------+ | 1 | bob | male | 0001 | 13900001234| | 2 | allen| male | 0011 | 13900001111| | 3 | kate | female | 0111 | 13900002222| | 4 | annie| female | 1111 | 13900003333| +------------+------+--------+------------+------------+
其他函数
MaxCompute SQL 提供了开发过程中常见的其他函数,可以根据实际需要选择合适的函数。
函数目录
| 序号 | 函数名称 | 函数功能 |
| 1 | BASE64 | 将二进制表示值转换为 BASE64 编码格式字符串。 |
| 2 | UNBASE64 | 将 BASE64 编码格式字符串转换为二进制表示值。 |
| 3 | GREATEST | 返回输入参数中的最大值。 |
| 4 | LEAST | 返回输入参数中最小的值。 |
| 5 | IF | 判断指定的条件是否为真。 |
| 6 | DECODE | 实现 if-then-else 分支选择的功能。 |
| 7 | TRANS_ARRAY | 将一行数据转为多行的 UDTF,将列中存储的以固定分隔符格式分隔的数组转为多行。 |
| 9 | LATERAL VIEW | 将单行数据拆成多行数据。 |
| 10 | UNIQUE_ID | 返回一个随机 ID,运行效率高于 UUID 函数。 |
示例数据
BASE64
命令格式
string base64(binary <value>)
命令说明
将 value 从二进制转换为 BASE64 编码格式字符串。
参数说明
- value:必填。BINARY 类型。待转换参数值
返回值说明
返回 STRING 类型。输入参数为 NULL 时,返回结果为 NULL。
使用示例
- 示例1:将
cast('alibaba' as binary)二进制结果转换为 BASE64 编码格式字符串
-- 返回 YWxpYmFiYQ== select base64(cast('alibaba' as binary));
- 示例2:输入参数为 NULL
-- 返回 NULL select base64(null);
UNBASE64
命令格式
binary unbase64(string <str>)
命令说明
将 BASE64 编码格式字符串 str 转换为二进制表示格式。
参数说明
- str:必填。STRING 类型。待转换 BASE64 编码格式字符串
返回值说明
返回 BINARY 类型。输入参数为 NULL 时,返回结果为 NULL。
使用示例
- 示例1:将字符串
YWxpYmFiYQ==转换为二进制表示值
-- 返回 alibaba select unbase64('YWxpYmFiYQ==');
- 示例2:输入参数为NULL
-- 返回 NULL select unbase64(null);
GREATEST
命令格式
greatest(<var1>, <var2>[,...])
命令说明
返回输入参数中的最大值。
参数说明
- var1、var2:必填。BIGINT、DOUBLE、DECIMAL、DATETIME 或 STRING 类型
返回值说明
- 返回输入参数中的最大值。当不存在隐式转换时,返回值与输入参数数据类型相同
- NULL 为最小值
- 当输入参数数据类型不相同时,DOUBLE、BIGINT、DECIMAL、STRING 之间的比较会转换为 DOUBLE 类型;STRING、DATETIME 的比较会转换为 DATETIME 类型。不允许其他的隐式转换
使用示例
- 示例1:比较两个日期的最大值
-- 返回 2023-01-01 select greatest(date'2022-12-31', date'2023-01-01');
LEAST
命令格式
least(<var1>, <var2>[,...])
命令说明
返回输入参数中的最小值。
参数说明
- var:必填。输入参数值。BIGINT、DOUBLE、DECIMAL、DATETIME 或 STRING 类型
返回值说明
- 输入参数中的最小值。当不存在隐式转换时,返回值与输入参数类型相同
- NULL 为最小值
- 当有类型转换时,DOUBLE、BIGINT、STRING 之间的转换返回 DOUBLE 类型;STRING、DATETIME 之间的转换返回 DATETIME 类型;DECIMAL、DOUBLE、BIGINT 和 STRING 之间的转换返回 DECIMAL 类型。不允许其他的隐式类型转换
- 如果所有参数值都为 NULL,返回结果为 NULL
使用示例
-- 返回2 select least(5, 2, 7);
IF
命令格式
if(<testCondition>, <valueTrue>, <valueFalseOrNull>)
命令说明
判断 testCondition 是否为真。如果为真,返回 valueTrue 的值,否则返回 valueFalseOrNull 的值。
参数说明
- testCondition:必填。要判断的表达式,BOOLEAN 类型
- valueTrue:必填。表达式 testCondition 为 True 时,返回的值
- valueFalseOrNull:表达式 testCondition 为 False 时,返回的值,可以设为 NULL
返回值说明
返回值类型和参数 valueTrue 或 valueFalseOrNull 的数据类型一致。
使用示例
-- 返回 200 select if(1=2, 100, 200);
DECODE
命令格式
decode(<expression>, <search>, <result>[, <search>, <result>]...[, <default>])
命令说明
实现 if-then-else 分支选择的功能。
参数说明
- expression:必填。要比较的表达式
- search:必填。与 expression 进行比较的搜索项
- result:必填。search 和 expression 的值匹配时的返回值
- default:可选。如果所有的搜索项都不匹配,则返回 default 值,如果未指定,则返回 NULL
注:
- 所有的 result 数据类型必须一致或为 NULL。不一致的数据类型会返回报错
- 所有的 search 和 expression 数据类型必须一致,否则会返回报错
返回值说明
- 如果匹配,返回 result
- 如果没有匹配,返回 default
- 如果没有指定 default,返回 NULL
- 如果 search 选项有重复且匹配时,会返回第一个值
- 通常,MaxCompute SQL 在计算
NULL=NULL时返回 NULL,但在该函数中,NULL 与 NULL 的值是相等的
使用示例
- 表 sale_detail 的字段为 shop_name string, customer_id string, total_price double,包含数据如下:
+------------+-------------+-------------+------------+------------+ | shop_name | customer_id | total_price | sale_date | region | +------------+-------------+-------------+------------+------------+ | s1 | c1 | 100.1 | 2013 | china | | s2 | c2 | 100.2 | 2013 | china | | s3 | c3 | 100.3 | 2013 | china | | null | c5 | NULL | 2014 | shanghai | | s6 | c6 | 100.4 | 2014 | shanghai | | s7 | c7 | 100.5 | 2014 | shanghai | +------------+-------------+-------------+------------+------------+
- 命令示例如下:
-- 当 customer_id 的值为 c1 时,返回 Taobao;值为 c2 时,返回 Alipay;值为 c3 时,返回 Aliyun;值为 NULL 时,返回 N/A;其他场景返回 Others select decode ( customer_id ,'c1', 'Taobao' ,'c2', 'Alipay' ,'c3', 'Aliyun' ,Null, 'N/A' ,'Others' ) as result from sale_detail;
TRANS_ARRAY
命令格式
if(<testCondition>, <valueTrue>, <valueFalseOrNull>)
命令说明
判断 testCondition 是否为真。如果为真,返回 valueTrue 的值,否则返回 valueFalseOrNull 的值。
参数说明
- testCondition:必填。要判断的表达式,BOOLEAN 类型
- valueTrue:必填。表达式 testCondition 为 True 时,返回的值
- valueFalseOrNull:表达式 testCondition 为 False 时,返回的值,可以设为 NULL
返回值说明
返回值类型和参数 valueTrue 或 valueFalseOrNull 的数据类型一致。
使用示例
-- 返回 200 select if(1=2, 100, 200);
LATERAL VIEW
命令格式
lateralView: lateral view [outer] <udtf_name>(<expression>) <table_alias> as <columnAlias> (',' <columnAlias>) fromClause: from <baseTable> (lateralView) [(lateralView) ...]
命令说明
通过 Lateral View 与 UDTF(表生成函数)结合,将单行数据拆成多行数据。
参数说明
- udtf_name:必填。将一行数据拆成多行数据的 UDTF
- expression:必填。待拆分行数据所属列名
- table_alias:必填。UDTF 结果集的别名
- columnAlias:必填。拆分后得到的列的别名
- baseTable:必填。数据源表
示例数据
假设已有一张表 pageAds,它有三列数据,第一列是 pageid string,第二列是 col1 array
+--------------+------------+---------------+ | pageid | col1 | col2 | +--------------+------------+---------------+ | front_page | [1, 2, 3] | ["a","b","c"] | | contact_page | [3, 4, 5] | ["d","e","f"] | +--------------+------------+---------------+
使用示例
- 单个 Lateral View 语句,拆分 col1
select pageid, col1_new, col2 from pageAds lateral view explode(col1) adTable as col1_new; +--------------+------------+---------------+ | pageid | col1_new | col2 | +--------------+------------+---------------+ | front_page | 1 | ["a","b","c"] | | front_page | 2 | ["a","b","c"] | | front_page | 3 | ["a","b","c"] | | contact_page | 3 | ["d","e","f"] | | contact_page | 4 | ["d","e","f"] | | contact_page | 5 | ["d","e","f"] | +--------------+------------+---------------+
- 多个 Lateral View 语句,拆分 col1 和 col2
select pageid, mycol1, mycol2 from pageAds lateral view explode(col1) myTable1 as mycol1 lateral view explode(col2) myTable2 as mycol2; +--------------+------------+------------+ | pageid | mycol1 | mycol2 | +--------------+------------+------------+ | front_page | 1 | a | | front_page | 1 | b | | front_page | 1 | c | | front_page | 2 | a | | front_page | 2 | b | | front_page | 2 | c | | front_page | 3 | a | | front_page | 3 | b | | front_page | 3 | c | | contact_page | 3 | d | | contact_page | 3 | e | | contact_page | 3 | f | | contact_page | 4 | d | | contact_page | 4 | e | | contact_page | 4 | f | | contact_page | 5 | d | | contact_page | 5 | e | | contact_page | 5 | f | +--------------+------------+------------+
UNIQUE_ID
命令格式
string unique_id()
命令说明
返回一个随机的唯一ID,格式示例为 29347a88-1e57-41ae-bb68-a9edbdd9****_1。该函数的运行效率高于 UUID,且返回的 ID 较长。
LATERAL VIEW
关于 EXPLODE 和 POSEXPLODE 函数,可参考 MaxCompute 复杂类型函数之 ARRAY 函数。
Lateral View 配合 split、explode 等 UDTF 函数一起使用,它能够将一列数据拆成多行数据,
并且对拆分后结果进行聚合,即将多行结果组合成一个支持别名的虚拟表;
Lateral View 主要解决在 select 中使用 UDTF 函数做查询的过程中查询只能包含单个 UDTF,
不能包含其它字段以及多个 UDTF 的情况(不能添加额外的 select 列的问题);
lateral view udtf(expression) tableAlias as columnAlias (,columnAlias)*
- lateral view:在 UDTF 前使用,表示连接 UDTF 所分裂的字段
- UDTF(expression):使用的 UDTF 函数,例如 explode()
- tableAlias:表示 UDTF 函数转换的虚拟表的名称
- columnAlias: 表示虚拟表的虚拟字段名称,如果分裂之后有一个列,则写一个即可;如果分裂之后有多个列,则按照列的顺序在括号中声明所有虚拟列名,以逗号隔开
单行变多行并汇总求和
- 创建部门利润表,一共三个字段,部门编号、部门层级树、利润(万元)
-- drop table lateral_dept: create table if not exists lateral_dept ( dept_no string comment '部门编号' ,dept_tree string comment '部门层级树' ,benifit int comment '利润(万元)' ) comment '部门利润表'; insert overwrite table lateral_dept values ('101', 'A.A1.101', 50), ('102', 'A.A1.102', 20), ('201', 'A.A2.201', 80); select * from lateral_dept; +------------+---------------+------------+ | dept_no | dept_tree | benifit | +------------+---------------+------------+ | 101 | A.A1.101 | 50 | | 102 | A.A1.102 | 20 | | 201 | A.A2.201 | 80 | +------------+---------------+------------+
- 将 dept_tree 字段转为多行
利用 lateral view 和 explode 函数将 dept_tree 列按照 . 分割成多行,通过结果可以看到,lateral view 函数将部门层级树字段炸开进行了扩展,每个部门都有与之对应的利润,从 3 行数据直接变成 9 行数据(笛卡尔积)。
-- 使用 explode 函数 select * from lateral_dept lateral view explode(split(dept_tree, '\\.')) tmp as dept_tree_new; +------------+---------------+------------+----------------+ | dept_no | dept_tree | benifit | dept_tree_new | +------------+---------------+------------+----------------+ | 101 | A.A1.101 | 50 | A | | 101 | A.A1.101 | 50 | A1 | | 101 | A.A1.101 | 50 | 101 | | 102 | A.A1.102 | 20 | A | | 102 | A.A1.102 | 20 | A1 | | 102 | A.A1.102 | 20 | 102 | | 201 | A.A2.201 | 80 | A | | 201 | A.A2.201 | 80 | A2 | | 201 | A.A2.201 | 80 | 201 | +------------+---------------+------------+----------------+
注: 上述 SQL 中 tmp 表示 UDTF 函数转换的虚拟表的名称,另外 explode 函数分裂之后只一个列,故 columnAlias 只写一个,即 dept_tree_new。
-- 使用 posexplode 函数 select * from lateral_dept lateral view posexplode(split(dept_tree, '\\.')) tmp as dept_tree_pos, dept_tree_new; +------------+---------------+------------+----------------+----------------+ | dept_no | dept_tree | benifit | dept_tree_pos | dept_tree_new | +------------+---------------+------------+----------------+----------------+ | 101 | A.A1.101 | 50 | 0 | A | | 101 | A.A1.101 | 50 | 1 | A1 | | 101 | A.A1.101 | 50 | 2 | 101 | | 102 | A.A1.102 | 20 | 0 | A | | 102 | A.A1.102 | 20 | 1 | A1 | | 102 | A.A1.102 | 20 | 2 | 102 | | 201 | A.A2.201 | 80 | 0 | A | | 201 | A.A2.201 | 80 | 1 | A2 | | 201 | A.A2.201 | 80 | 2 | 201 | +------------+---------------+------------+----------------+----------------+
注: 上述 SQL 中 tmp 表示 UDTF 函数转换的虚拟表的名称,另外 posexplode 函数分裂之后有两个列,分别对应数组从 0 开始的下标和数组元素,故 columnAlias 需要写两个,即 dept_tree_pos 和 dept_tree_new。
- 汇总求和
对部门利润进行向上汇总求和,可以看到每个部门的总利润。
select dept_tree_new as dept_no ,sum(benifit) as sum_benifit from ( select * from lateral_dept lateral view explode(split(dept_tree, '\\.')) tmp as dept_tree_new ) group by dept_tree_new; +------------+------------+ | dept_no | benifit | +------------+------------+ | A | 150 | | A1 | 70 | | A2 | 80 | | 101 | 50 | | 102 | 20 | | 201 | 80 | +------------+------------+
生成一段时间内的连续日期
- 获取期初、期末日期、日期间隔天数
select s_date, e_date, datediff(e_date, s_date) as diff from ( select date'2022-01-01' as s_date, date'2022-01-31' as e_date ); +------------+------------+------------+ | s_date | e_date | diff | +------------+------------+------------+ | 2022-01-01 | 2022-01-31 | 30 | +------------+------------+------------+
- 使用
split函数,返回数组
select *, split(repeat(', ', 30), ',') from ( select s_date, e_date, datediff(e_date, s_date) as diff from ( select date'2022-01-01' as s_date, date'2022-01-31' as e_date ) );
- 使用
posexplode函数将数组展开,获取数组下标和元素
select posexplode(split(repeat(', ', 30), ',')) from ( select s_date, e_date, datediff(e_date, s_date) as diff from ( select date'2022-01-01' as s_date, date'2022-01-31' as e_date ) );
- 由于在
select中使用 UDTF 做查询的过程中查询只能包含单个 UDTF,能添加额外的select列,故使用Lateral View函数
select * from ( select s_date, e_date, datediff(e_date, s_date) as diff from ( select date'2022-01-01' as s_date, date'2022-01-31' as e_date ) ) lateral view posexplode(split(repeat(', ', 30), ',')) c as pos, val; +------------+------------+------------+------------+------------+ | s_date | e_date | diff | pos | val | +------------+------------+------------+------------+------------+ | 2022-01-01 | 2022-01-31 | 30 | 0 | | | 2022-01-02 | 2022-01-31 | 30 | 1 | | | 2022-01-03 | 2022-01-31 | 30 | 2 | | | 2022-01-04 | 2022-01-31 | 30 | 3 | | | 2022-01-05 | 2022-01-31 | 30 | 4 | | | 2022-01-06 | 2022-01-31 | 30 | 5 | | | 2022-01-07 | 2022-01-31 | 30 | 6 | | | 2022-01-08 | 2022-01-31 | 30 | 7 | | | 2022-01-09 | 2022-01-31 | 30 | 8 | | | 2022-01-10 | 2022-01-31 | 30 | 9 | | | 2022-01-11 | 2022-01-31 | 30 | 10 | | | 2022-01-12 | 2022-01-31 | 30 | 11 | | | 2022-01-13 | 2022-01-31 | 30 | 12 | | | 2022-01-14 | 2022-01-31 | 30 | 13 | | | 2022-01-15 | 2022-01-31 | 30 | 14 | | | 2022-01-16 | 2022-01-31 | 30 | 15 | | | 2022-01-17 | 2022-01-31 | 30 | 16 | | | 2022-01-18 | 2022-01-31 | 30 | 17 | | | 2022-01-19 | 2022-01-31 | 30 | 18 | | | 2022-01-20 | 2022-01-31 | 30 | 19 | | | 2022-01-21 | 2022-01-31 | 30 | 20 | | | 2022-01-22 | 2022-01-31 | 30 | 21 | | | 2022-01-23 | 2022-01-31 | 30 | 22 | | | 2022-01-24 | 2022-01-31 | 30 | 23 | | | 2022-01-25 | 2022-01-31 | 30 | 24 | | | 2022-01-26 | 2022-01-31 | 30 | 25 | | | 2022-01-27 | 2022-01-31 | 30 | 26 | | | 2022-01-28 | 2022-01-31 | 30 | 27 | | | 2022-01-29 | 2022-01-31 | 30 | 28 | | | 2022-01-30 | 2022-01-31 | 30 | 29 | | | 2022-01-31 | 2022-01-31 | 30 | 30 | | +------------+------------+------------+------------+------------+
- 使用
date_add函数计算 s_date 字段和 pos 字段即可得到结果
select date_add(s_date, pos) as d_date from ( select * from ( select s_date, e_date, datediff(e_date, s_date) as diff from ( select date'2022-01-01' as s_date, date'2022-01-31' as e_date ) ) lateral view posexplode(split(repeat(', ', 30), ',')) c as pos, val );
生成 1-100 的连续数字
select pos + 1 from (select posexplode(split(repeat(', ', 99), ',')));
参考资料
Hive SQL 中的 lateral view 与 explode、posexplode
原创文章,转载请注明出处:http://www.opcoder.cn/article/77/