在数据分析过程中,有时出于增强数据可读性或其他原因,我们需要对数据表的索引值进行设定。
通常,在 Pandas Dataframe 中,我们默认以 0 到对象长度的序列号作为索引。我们也可以将 DataFrame 中的某一列作为其索引。
索引是什么
在进行数据分析时,通常我们要根据业务情况进行数据筛选,要求筛选特定情况的行或列,这时就要根据数据类型(Series或者DataFrame)的索引情况对数据进行相应的行切片或者列索引的处理。
在 Pandas 中最常用的就是数据类型就是 Series 和 DataFrame,它们的索引情况如下:
Series
- 索引(index):对应是最左侧那一列
- 值(values):每一个索引的右侧对应一个值
DataFrame 有两种索引
- 行索引(index):对应最左边的那一列
- 列索引(columns):对应最上面的那一行
set_index()
Pandas.DataFrame.set_index() 方法用于为 DataFrame 添加索引(行标签)。
语法:
DataFrame.set_index(keys, * , drop=True, append=False, inplace=False, verify_integrity=False)
返回值: DataFrame or None
如果 inplace 设置为 True 则返回 None 否则返回一个新的 DataFrame。
参数说明:
- keys:指定要设置为索引的列名或列名的列表。
- drop:是否舍弃作为索引的列。默认为 True,表示将指定的列从 DataFrame 中删除并设置为索引。如果设置为 False,则保留指定的列作为普通列,同时创建一个新的索引列
- append:默认为 False,表示替换现有的索引。如果设置为 True,则将新的索引列附加到现有的索引列中,和原索引组成多层索引。
- inplace:默认为 False,表示返回一个新的 DataFrame,而不修改原始的 DataFrame。如果设置为 True ,则在原始 DataFrame 上进行就地修改,并返回 None
- verify_integrity:默认为 False,表示不验证新的索引是否唯一。如果设置为 True,则会验证新的索引是否唯一,如果存在重复值,将引发异常
实例说明:
from odps import ODPS from odps.df import DataFrame import pandas as pd users = o.get_table('pyodps_ml_100k_users').to_df().head(10).to_pandas() print(users)
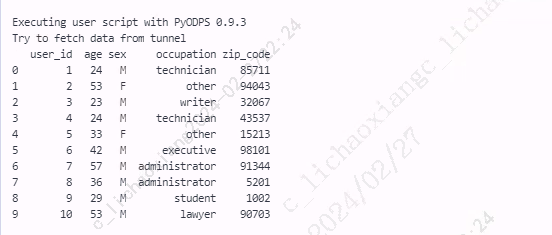
- 将 user_id 列作为行索引
users1 = users.set_index('user_id') print(users1) print(users1.index) print(users1.loc[1])

- 将 user_id 列和 sex 列作为行索引
users2 = users.set_index(['user_id', 'sex']) print(users2) print(users2.index) print(users2.loc[1].loc['M'])

- 指定参数 drop=True,该参数为默认参数
users3 = users.set_index('user_id', drop=True) print(users3)
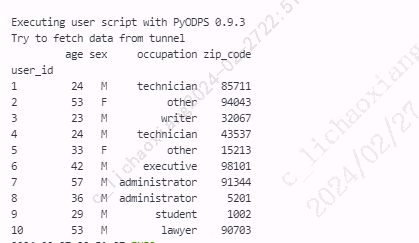
- 指定参数 drop=False
users4 = users.set_index('user_id', drop=False) print(users4)
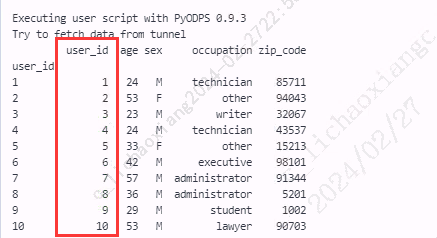
注:对比参数 drop=True 和 drop=False,可以看到,当 drop=False 时,被作为行索引的那一列数据仍然被保留下来了。
- 指定参数 append=False,该参数为默认参数
users5 = users.set_index('user_id', append=False) print(users5)
- 指定参数 append=True
users6 = users.set_index('user_id', append=True) print(users6)
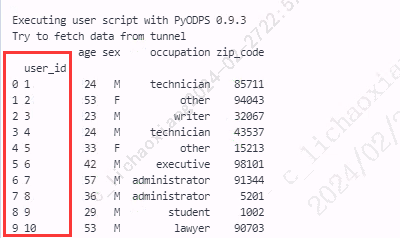
注:对比参数 append=True 和 append=False,可以看到,当 append=True 时,原来行索引和新的行索引一起被保留下来了。
reset_index()
Pandas.DataFrame.reset_index 方法用于将 DataFrame 的索引,重置为数字索引。如果 DataFrame 具有 MultiIndex(多层索引),则此方法可以重置一个或多个级别。
默认状态下,reset_index() 会把原索引插入到 DataFrame 作为普通的数据列。
语法:
DataFrame.reset_index(level=None, * , drop=False, inplace=False, col_level=0, col_fill='', allow_duplicates=_NoDefault.no_default, names=None)
返回值: DataFrame or None
如果 inplace 设置为 True 则返回 None 否则返回一个新的 DataFrame 。
参数说明:
- level:指定要重置的索引级别。默认为 None 表示重置所有级别的索引
- drop:是否舍弃原索引。默认为 False,原索引会插入到 DataFrame 里作为普通的数据列。如果 drop=True 则原索引会被舍弃,不会被插入到DataFrame
- inplace:默认为 False,表示返回一个新的 DataFrame,而不修改原始的 DataFrame。如果设置为 True,则在原始 DataFrame 上进行就地修改,并返回 None。
实例说明:
from odps import ODPS from odps.df import DataFrame import pandas as pd users = o.get_table('pyodps_ml_100k_users').to_df().head(10).to_pandas() print(users)
reset_index() 函数可分为两种类型,第一种是对原来的数据表进行 reset;第二种是对使用过 set_index() 函数的数据表进行 reset。
对原来的数据表进行 reset
- 指定参数 drop=False,该参数为默认参数
users2 = users.reset_index(drop=False) print(users2)
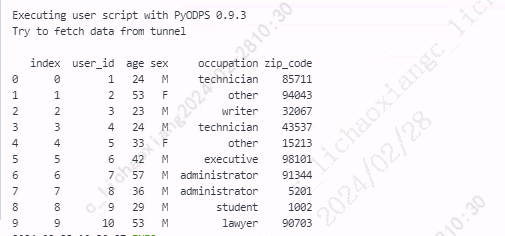
原来索引值被还原成了普通列,同时被系统命名为 index 字段。
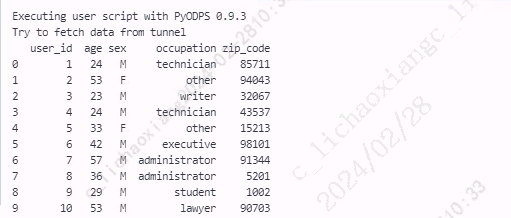
- 指定参数 drop=True
users3 = users.reset_index(drop=True) print(users3)
对使用过 set_index() 函数的数据表进行 reset
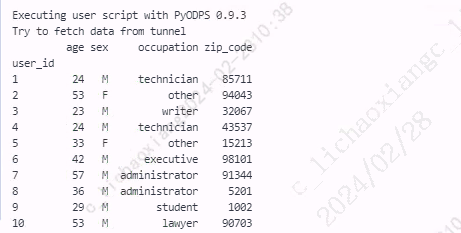
- 使用 set_index() 函数进行索引设置
users4 = users.set_index('user_id') print(users4)
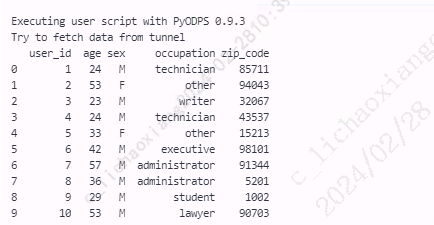
- 使用 reset_index() 函数进行还原
users5 = users4.reset_index(drop=False) print(users5)
users6 = users4.reset_index(drop=True) print(users6)
参考资料
Pandas.DataFrame.reset_index() 重置索引详解
Pandas.DataFrame.set_index() 添加索引详解
Python 数据分析基础 > Pandas 中 set_index()、reset_index() 的使用
原创文章,转载请注明出处:http://www.opcoder.cn/article/68/