Greenplum 是一款基于分布式架构的开源数据库;采用无共享(Shared-Nothing)的 MPP 架构(每个数据节点拥有独立的 CPU、IO 和内存等资源);其具有良好的线性扩展能力,具有高效的并行运算、并行存储特性。拥有独特的高效的 ORCA 优化器。非常适合用于 PB 数据量级的存储、处理和实时分析能力。
Greenplum 是基于 PostgreSQL 数据库发展而来,本质上是多个 PostgreSQL 面向磁盘的数据库实例一起工作形成的一个紧密结合的数据库管理系统(DBMS),同时支持涵盖 OLTP 型业务混合负载,数据节点和主节点均可设计备份节点,进而提供数据库的高可用性。
并行和分布式计算
并行计算
并行计算(Parallel computing)一般是指许多指令同时进行的计算模式。相对于串行计算, 并行计算可以划分成时间并行和空间并行。时间并行即流水线技术,空间并行使用多个处理器执行并发计算,当前研究的主要是空间的并行问题。空间上的并行导致两类并行机器的产生,即单指令流多数据流(SIMD)和多指令流多数据流(MIMD)。MIMD 类的机器又可分为常见的五类:
- 并行向量处理机(PVP)
- 对称多处理机(SMP)
- 大规模并行处理机(MPP)
- 工作站机群(COW)
- 分布式共享存储处理机(DSM)
(1)SMP
所谓对称多处理器,是指服务器中多个 CPU 对称工作,无主次或从属关系,各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为一致存储器访问结构(Uniform Memory Access,UMA)。对 SMP 服务器进行扩展的方式包括增加内存、使用更快的 CPU、增加 CPU、扩充 I/O(槽口数与总线数)以及添加更多的外部设备(通常是磁盘存储)。SMP 服务器的主要特征是共享,系统中所有资源(CPU、内存、I/O 等)都是共享的。也正是这种特征,导致 SMP 服务器的主要问题,那就是它的扩展能力非常有限。
对于 SMP 服务器而言,每一个共享的环节都可能造成 SMP 服务器扩展时的瓶颈,而最受限制的则是内存。由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。
(2)NUMA
NUMA(Non-Uniform Memory Access)服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU(如4个)组成,并且具有独立的本地内存、I/O 槽口等。由于其节点之间可以通过互联模块(又称为 Crossbar Switch)进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存(这是 NUMA 与 MPP 的重要差别)。显然,访问本地内存的速度将远远高于访问远程内存(系统内其他节点的内存)的速度,这也是非一致存储访问 NUMA 的由来。但 NUMA 技术同样有一定缺陷,由于访问远程内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。
(3)MPP
MPP 由多个 SMP 服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个 SMP 服务器(每个 SMP 服务器被称为节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Shared-Nothing)结构,因而扩展能力最好,理论上其扩展无限制。在 MPP 系统中,每个 SMP 节点也可以运行自己的操作系统、数据库等。但和 NUMA 不同的是,它不存在异地内存访问的问题。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution)。但是 MPP 服务器需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程。
分布式计算
分布式系统(distributed system)是建立在网络之上的软件系统。分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。
- 内聚性:是指每一个数据库分布节点高度自治,有本地的数据库管理系统。
- 透明性:是指每一个数据库分布节点对用户的应用来说都是透明的,看不出是本地还是远程的。在分布式数据库系统中,用户感觉不到数据是分布的,即用户无须知道关系是否分隔、有无副本、数据存于哪个站点以及事务在哪个站点上执行等。
分布式计算就是研究如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把这些计算结果综合起来得到最终的结果。
MapReduce 就是分布式计算中最典型的一种编程方法,是 Google 提出的一个软件架构,用于大规模数据集(大于 1TB)的并行运算。其中 Map(映射)函数,用来把一组键值对映射成一组新的键值对,Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
并行数据库
并行数据库要求尽可能并行执行所有的数据库操作,从而在整体上提高数据库系统的性能。根据所在计算机的处理器(Processor)、内存(Memory)及存储设备(Storage)的相互关系,并行数据库可以归纳为三种基本的体系结构(这也是并行计算的三种基本体系结构),即共享内存结构(Shared-Memory)、共享磁盘结构(Shared-Disk)和无共享资源结构(Shared-Nothing)。
Shared-Memory 结构
该结构包括多个处理器、一个全局共享的内存(主存储器)和多个磁盘存储,各个处理器通过告诉通信网络(Interconnection Network)与共享内存连接,并均可直接访问系统中的一个、多个或全部的磁盘存储,在系统中,所有的内存和磁盘存储均由多个处理器共享。在并行数据库领域,Shared-Memory 结构很少被使用。
Shared-Disk 结构
该结构由多个具体独立内存(主存储器)的处理器和多个磁盘存储构成,各个处理器相互之间没有任何之间的信息和数据交换,多个处理器和磁盘存储由高速通信网络连接,每个处理器都可以读写全部的磁盘存储。Shared-Disk 结构的典型代表是 Oracle 集群。
Shared-Nothing 结构
该结构由多个完全独立的处理节点构成,每个处理节点具有自己独立的处理器、独立的内存(主存储器)和独立的磁盘存储,多个处理节点在处理器由高速通信网络连接,系统中的各个处理器使用自己的内存独立地处理自己的数据。
在这种结构中,每一个处理节点就是一个小型的数据库系统,多个节点一起构成整个的分布式的并行数据库系统。由于每个处理器使用自己的资源处理自己的数据,不存在内存和磁盘的争用,从而提高了整体性能。另外这种结构具有优良的可扩展性,只需增加额外的处理节点,就可以接近线性的比例增加系统的处理能力。Shared-Nothing 结构的典型代表是 Teradata、Vertica、Greenplum、Aster Data、IBM DB2 和 Mysql 的集群也使用了这种结构。
Greenplum 架构分析
Greenplum 的高性能得益于其良好的体系结构,Greenplum 的架构采用了 MPP(大规模并行处理)。在 MPP 系统中,每个 SMP 节点也可以运行自己的操作系统、数据库等。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution)。
与传统的 SMP 架构明显不同,在通常情况下,MPP 系统因为要在不同处理单元之间传递信息,所以它的效率要比 SMP 要差一点,但是这也不是绝对的,由于 MPP 系统不共享资源,因此对它而言,资源比 SMP 要多,当需要处理的事务达到一定的规模时,MPP 的效率要比 SMP 好。视通信时间占用计算时间的比例来判定,如果通信时间比较多,那 MPP 系统就不占优势了;相反,如果通信时间比较少,那么 MPP 系统可以充分发挥资源的优势,达到高效率。
Greenplum 是一种基于 PostgreSQL 的分布式数据库,其采用的 Shared-Nothing 架构(MPP),主机、操作系统、内存、存储都是自我控制的,不存在共享。Greenplum 架构主要由 Master Host、Segment Host、Interconnect 三大部分组成,如图:
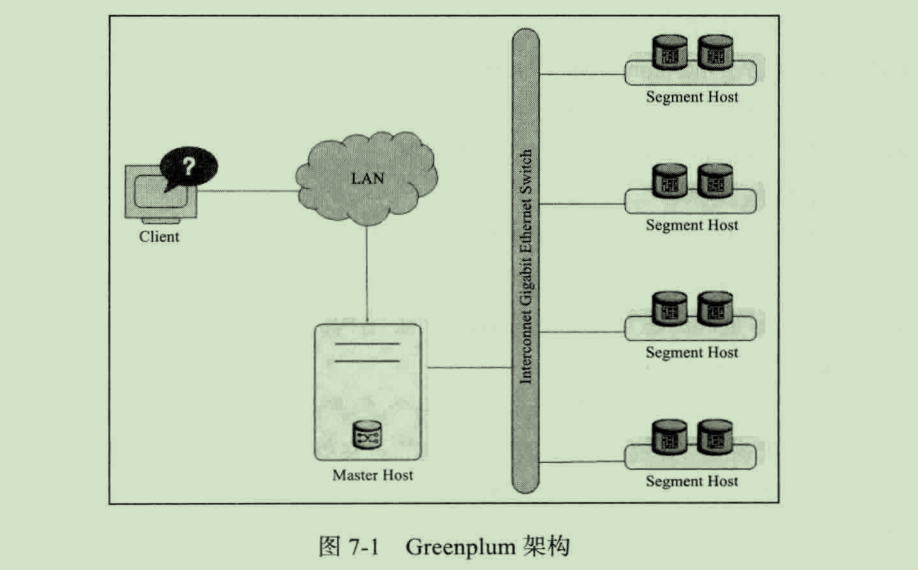
Master Host
Master Host 是 Greenplum 数据库系统的入口:
- 接受客户端的连接请求
- 负责权限认证
- 处理 SQL 命令(SQL 的解析并形成执行计划)
- 分发执行计划
- 汇总 Segment 的执行结果
- 返回执行结果给客户端
由于 Greenplum 数据库是基于 PostgreSQL 数据库的,终端用户通过 Master 同数据库交互就如同操作一个普通的 PostgreSQL 数据库。用户可以使用 PostgreSQL 或者 JDBC、ODBC 等应用程序接口连接数据库。Greenplum 不存储业务数据,仅存储数据字典。
Segment Host
Segment Host 负责业务数据的存储和读取、用户查询 SQL 的执行。Greenplum 数据库的性能由一组 Segment 服务中最慢的 Segment 决定,因此要确保基本的运行 Greenplum 数据的硬件与操作系统在同一性能级别,同样建议在 Greenplum 数据系统中的所有 Segment 机器有一样的资源与配置。
Interconnect
Interconnect 是 Greenplum 数据库的网络层,在每个 Segment 中起到一个 IPC 的作用(Inter-Process Communication)。Greenplum 数据库推荐使用标准的千兆以太网交换机来做 Interconnect。在默认情况下,Interconnect 使用的是 UDP 协议来进行传输,因为在 Greenplum 的软件当中,没有其他包去检查和验证 UDP,所以 UDP 协议在可靠性上等同于 TCP 协议,并且超过了 TCP 的性能和可扩展性,而且使用 TCP 协议会有一个限制,最大只能使用 1000 个 Segment 实例。
冗余与故障切换
Greenplum 数据库配置镜像节点之后,当主节点不可用时会自动切换至镜像节点,集群仍然保持可用状态。当主节点恢复并启动之后,主节点会自动恢复期间的变更。只要 Master 不能连接上 Segment 实例时,就会在系统表中将此实例标识为不可用,并用镜像节点来代替。
如果在配置服务器集群时,没有开启镜像功能,任何一个 Segment 实例不可用,整个集群将变得不可用,大大降低集群可用性。
镜像节点一般需要和主节点位于不同服务器上,如图:
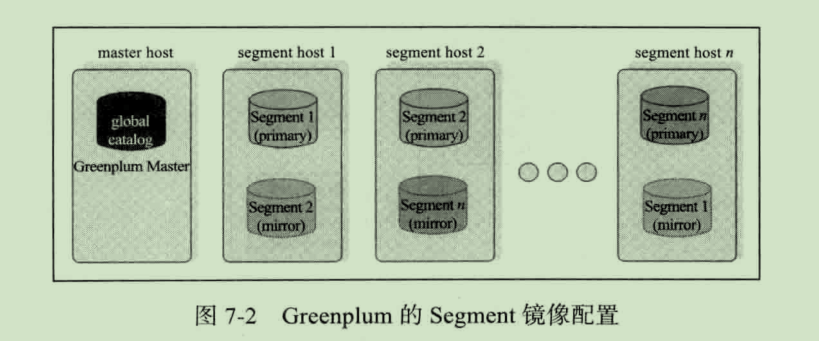
除了像上图这样为 Segment 实例配置镜像节点,也可以为 Master 节点配置镜像,确保系统的变更信息不会丢失,提升系统的健壮性,如图:
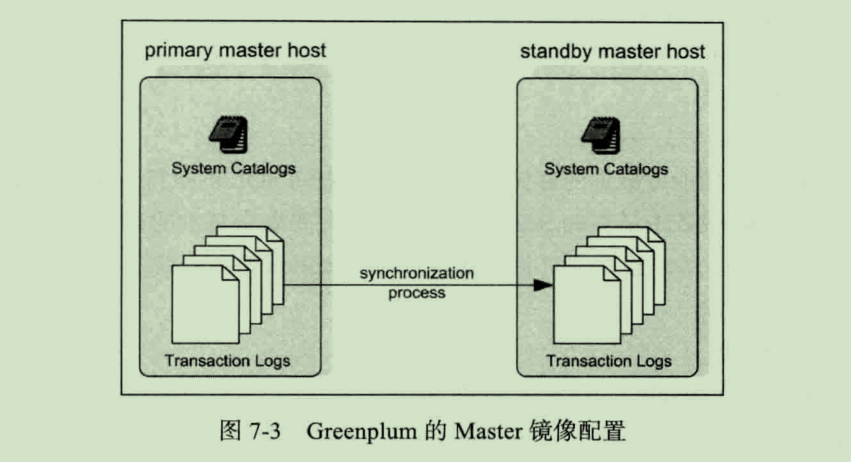
另外,还需要从网络配置上确保节点之间的网络交互的高可用。
数据分布及负载均衡
Greenplum 是一个分布式数据库系统,故其所有的业务数据都是物理存放在集群的所有 Segment 实例数据库上。这些看似独立的 PostgreSQL 数据库通过网络相互连接,并和 Master 节点协同构成整个数据库集群。
在学习和使用 Greenplum 数据库时,我们必须理解数据在集群中是如何存放的。下面以一个简单数据仓库星型模型为例,形象地介绍数据是如何存放的:
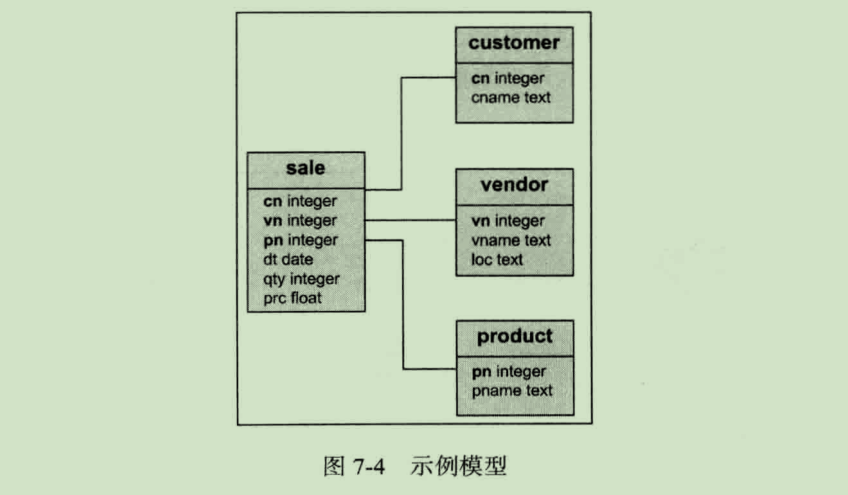
在 Greenplum 数据库中所有表都是分布式的,所以每一张表都会被切片,每个 Segment 实例数据库会存放相应的数据片段。切片规则可由用户定义,可选的方案有根据用户对每一张表指定的 Hash Key 进行 Hash 分片或者选择随机分配。
图 7-4 中的业务场景在 Greenplum 数据库中的存放规则如图 7-5 所示。sale、customer、product、vendor 四张表的数据都会切片存放在所有的 Segment 上,当我们需要进行数据分析时,所有 Segment 实例同时工作,由于每个 Segment 只需要计算一部分数据,所以计算效率将会大大提升。这正是 Greenplum 数据库分布式计算提升性能的关键所在。
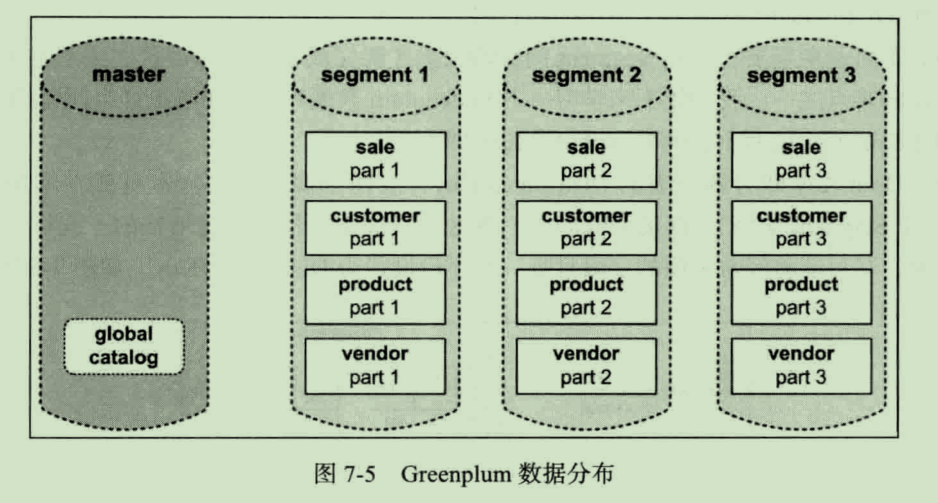
Greenplum 数据库在创建或者修改表时可选的数据分散策略有 Hash Distribution 和 Random Distribution 两种。
Hash Distribution
当选择 Hash Distribution 策略时,可指定表的一列或者多列组合。Greenplum 会根据指定的 Hash Key 列计算每一行数据对应的 Hash 值,并映射至相应的 Segment 实例。当选择的 Hash Key 列的值唯一时,数据将会均匀地分散至所有 Segment 实例。
Greenplum 数据库默认会采用 Hash Distribution,如果创建表时未指定 Distributed Key,则会选择 Primary Key 作为 Distributed Key,如果 Primary Key 也不存在,就会选择表的第一列作为 Distributed Key。
Random Distribution
当选择 Random Distribution 时,数据将会随机分配至 Segment,相同值的数据行不一定会分发至同一个 Segment。虽然 Random Distribution 策略可以确保数据平均分散至所有 Segment,但是在进行表关联分析时,仍然会按照关联键分重分布数据,所以 Random Distribution 策略通常不是一个明智的选择(除非查询 SQL 只有对单表进行全局的聚合操作,即没有 group by 或者 join 等需要数据重分布的操作,此时这种分布模式可以避免数据倾斜,而且性能更高)。
在数据建模时,表的分片规则选取一定要慎重,尽可能选择唯一且常用于 join 的列作为 Distribution Key。这样数据才会均匀分散至所有 Segment 实例,相应的查询及计算的负载也会平摊至整个集群,进而最大程度体现分布式计算的优势。假如 Distribution Key 选取不当(如选择性别列作为 Distribution Key),数据将指挥分散至少数几个 Segment,这样将只有少数 Segment 处理相应的计算请求,完全不能发挥整个集群的计算资源,实现并行计算。
跨库关联
Greenplum 数据库将表数据分散至所有 Segment 实例,当需要进行表关联分析时,由于各个表的 Distributed Key 不同,相同值的行数据可能分布在不同服务器的不同 Segment 实例,因此不可避免需要在不同 Segment 间移动数据才能完成 Join 操作。跨库关联也正是分布式数据库的难点之一。
Greenplum 数据库按照如下方式解决这个问题:
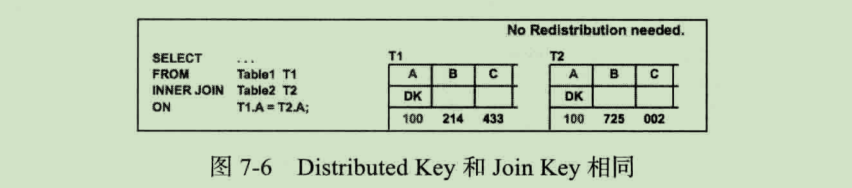
两个表的 Distributed Key 即 Join Key
由于 Join Key 即为两个表的 Distributed Key,故两个表关联的行本身就在本地数据库(即同一个 Segment 实例),直接关联即可。在这种情况下,性能也是最佳的。
在进行模型设计时,尽可能将经常关联的字段且唯一的字段设置为 Distributed Key。如下图所示:
两个表中的一个 Distributed Key 与 Join Key 相同
由于其中一个表的 Join Key 和 Distributed Key 不一致,故两个表关联的行不在同一个数据库中,便无法完成 Join 操作。在这种情况下就不可避免地需要数据跨节点移动,将关联的行组织在同一个 Segment 实例,最终完成 Join 操作。
Greenplum 可以选择两种方式将关联的行组织在同一个 Segment 中,其中一个方式是将 Join Key 和 Distributed Key 不一致的表按照关联字段重分布(即 Redistribute Motion);另一种方式是可以将 Join Key 和 Distributed Key 不一致的表在每个 Segment 广播(即 Broadcast Motion),也就是每个 Segment 都复制一份全量数据。如下图所示:

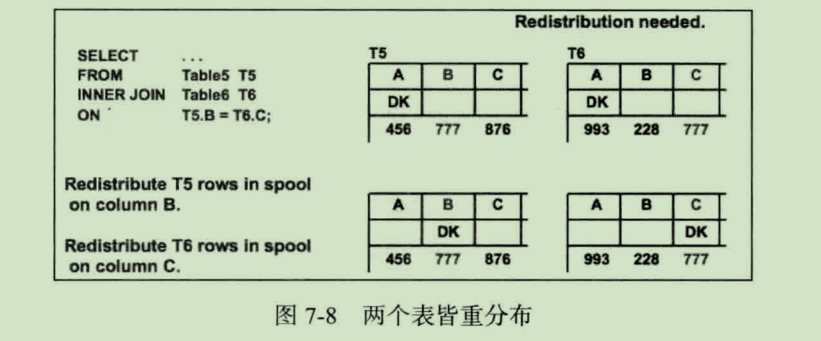
两个表的 Distributed Key 和 Join Key 都不同
由于两个表的 Join Key 和 Distributed Key 都不一致,故两个表的行不在同一个数据库中,便无法完成 Join 操作。同样在这种情况下,一种方式将两个表都按照关联字段重分布(即 Redistribute Motion);另一种方式可以将其中一个表在每个 Segment 广播(即 Broadcast Motion),也就是每个 Segment 都复制一份全量数据。如下图所示:
综合上面讨论的三种情况,我们可以看出,Greenplum 主要采用了 Redistribute Motion 和 Broadcast Motion 这两种方式来解决跨节点关联这个难点。
分布式事务
分布式事务处理是指一个事务可能涉及多个数据库操作,而分布式的关键在于两阶段提交(Two Phase Commit,2PC)。两阶段提交用于确保所有分布式事务能够同时提交或者回滚,以便数据库能够处于一致性状态。
分布式事务处理的关联是必须有一种方法可以知道事务在任何地方所做的所有动作,提交或回滚事务必须产生一致的结果(全部提交或全部回滚),所以就需要有一个事务协调器来负责处理每一个数据库的事务。在 Greenplum 中,Master 就充当这样一个角色。
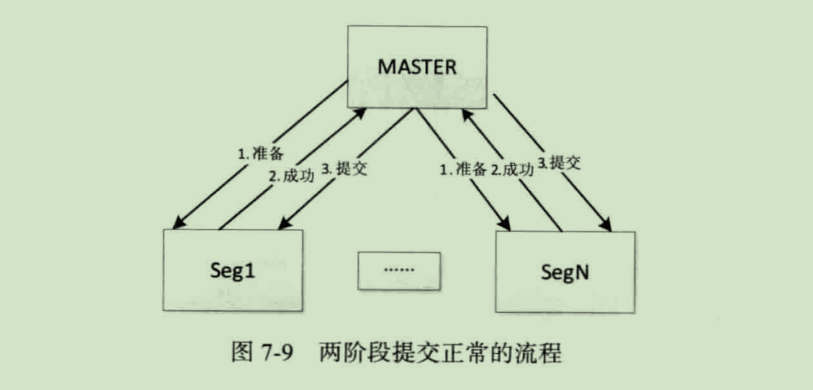
两阶段提交,顾名思义就是把事务提交分成两个阶段:
- 第一阶段,Master 向每个 Segment 发出 "准备提交" 请求,数据库收到请求后执行相同的数据修改和日志记录等处理,处理完成后只是把事务的状态改成 "可以提交",然后把执行的结果返回给 Master
- 第二阶段,Master 收到回应后进入第二阶段,如果所有 Segment 都返回成功,那么 Master 向所有的 Segment 发出 "确认提交" 请求,数据库服务器把事务的 "可以提交" 状态改为 "提交完成" 状态,这个事务就算正常完成了。
两阶段提交正常的流程:
如果在第一阶段内有 Segment 执行发生了错误,Master 收不到 Segment 回应或者 Segment 返回失败,则认为事务失败,回撤事务,Segment 收到 Rollback 的命令,即将当前事务全部回滚:
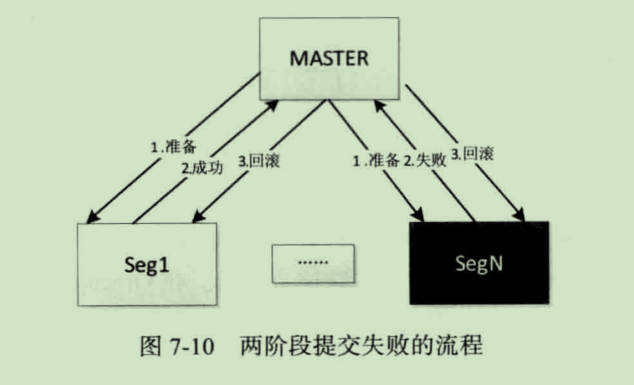
从上图的流程可以看出,两阶段提交并不能保证数据一定会恢复到一致性状态。例如,当 Master 向 Segment 发出提交命令的时候,在提交过程中,有一个 Segment 失败了,但是其他 Segment 已经提交成功了,那么这个事务是不能再次回滚的,这样就会造成不一致的情况。
两阶段提交的核心思想就是将可能发生不一致的时间降低到最小,因为提交过程对数据库来说应该时一个瞬间完成的动作,而且发生错误的概率极小,危险期比较短。
参考资料
Greenplum 企业应用实战
原创文章,转载请注明出处:http://www.opcoder.cn/article/63/