聚簇因子是 Oracle 统计信息中在 CBO 优化器模式下用于计算成本(cost)的参数之一,决定了当前的 SQL 语句是否走索引,还是走全表扫描以及是否作为嵌套连接外部表等。
当对堆表新建或重建索引时,由于索引列上的顺序是有序的,而表上的顺序是无序的,也就存在了差异,这种差异即表现为聚簇因子。
通过查询 DBA/ALL/USER_INDEXES 视图、DBA/ALL/USER_IND_PARTITIONS 视图的 CLUSTERING_FACTOR 列,可以了解当前索引的聚簇因子值。
什么是聚簇因子
- 聚簇因子是基于表上索引列上的一个值,每一个索引都有一个聚簇因子
- 用于描述索引块上与表块上存储数据在顺序上的相似程度,也就说表上的数据行的存储顺序与索引列上顺序是否一致
- 良好的 CF 值趋近于表上的块数,而较差的 CF 值则趋近于表上的行数
- 聚簇因子在索引创建时就会通过表上存在的行记录以及索引块计算获得
索引块与相应数据块之间数据分布产生差异的原因
- 对于索引块的数据存储,这里以普通 Btree 索引为例,索引块中键值的分布总是有序的,且根据键值及其相应的 rowid 信息,唯一定位一行记录在相应表的数据块中的分布。理想情况下,相同或相邻的键值,尽量定位在相同的数据块上,可以避免对于数据块多余的 I/O 操作
- 对于数据块的数据存储,并不是有序存储的(针对堆表),且 Oracle 为节省空间,会优先使用当前当水位线(HWM)以下的可用数据块,而不是按序使用最后被使用的块,当 HWM 以下无可用数据块时,再开辟新的数据块使用
- 正因为数据块中数据存储的特点(无序),随着时间的推移,数据在相应数据块间的分布越发零散,进而影响索引块中,相同或相邻键值对应的相应数据行信息(rowid),所指向的数据块越加分散,进而导致聚簇因子变差
聚簇因子的计算方法
聚簇因子大致的计算方法顺序如下:
- 聚簇因子的初始值为 1
- Oracle 首先定位到目标索引处于最左边的叶子块
- 从最左边的叶子块的第一个索引键值所在的索引行开始顺序扫描,在顺序扫描的过程中,Oracle 会比较当前索引行的 rowid 和它之前的那个索引行(它们是相邻的关系)的 rowid,如果这两个 rowid 并不是指向同一个表块,那么 Oracle 就将聚簇因子的当前值递增 1;如果这两个 rowid 是指向同一个表块,Oracle 就不改变聚簇因子的当前值。
- 上述比对 rowid 的过程会一直持续下去,直到顺序扫描完目标索引所有叶子块里的所有索引行
- 上述顺序扫描操作完成后,聚簇因子的当前值就是索引统计信息中的 CLUSTERING_FACTOR
从上述聚簇因子的算法可以知道,如果聚簇因子的值接近于对应表的表块(Blocks)的数量,则说明目标索引行和存储于对应表中数据行(Num_Rows)的存储顺序的相似程度非常高。这也就意味着 Oracle 走索引范围扫描后取得目标 rowid 再回表去访问对应表块的数据时,相邻的索引行所对应的 rowid 极有可能处于同一个表块中,即 Oracle 在通过索引行记录的 rowid 回表第二次去读取对应的表块时,就不需要再产生物理 I/O 了,因为这次要访问的和上次已经访问过的表块是同一个块,Oracle 已经将其缓存在 Buffer Cache 中了。
而如果聚簇因子的值接近于对应表的记录数(Num_Rows),则说明目标索引索引行存储和存储于对应表中数据行的存储顺序相似程度非常低,这也就意味着 Oracle 走索引范围扫描取得目标 rowid 再去访问对应表块的数据时,相邻的索引行所对应的 rowid 极有可能已经不处于同一个表块,当再通过相邻索引行记录的 rowid 回表第二次去读取对应的表块时,还需要产生物理 I/O,因为这次要访问的和上次已经访问过的表块并不是同一个块。
聚簇因子高的索引走索引范围扫描时比相同条件下聚簇因子低的索引要耗费更多的物理 I/O,所以聚簇因子高的索引走索引范围扫描的成本会比相同条件下聚簇因子低的索引走索引范围扫描的成本高。
聚簇因子图示
- 良好的索引与聚簇因子的情形
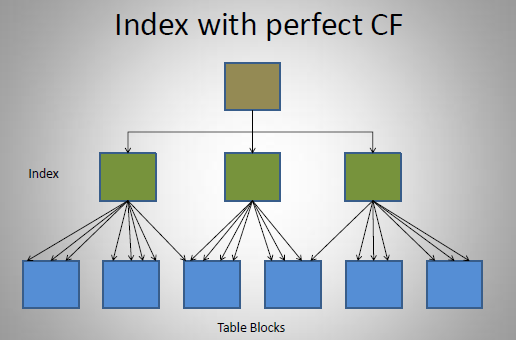
- 良好的索引、差的聚簇因子的情形
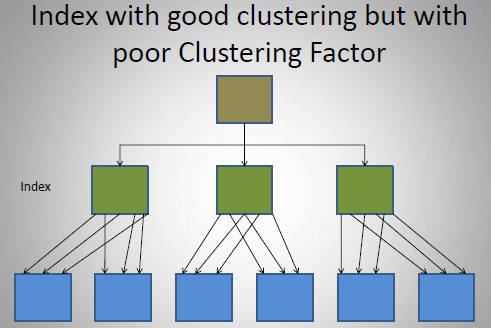
- 差的索引、差的聚簇因子的情形
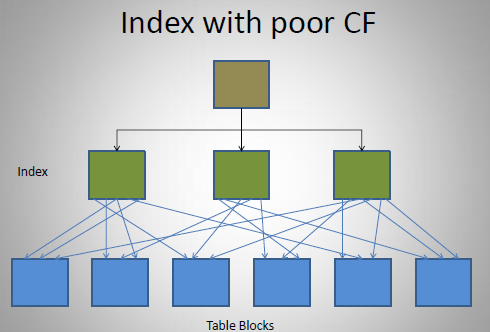
影响聚簇因子的情形
当插入到表的数据与索引列的顺序相同时,可以提高聚簇因子(趋近于表上的块数),因此,任何影响该顺序的情形都将导致索引列上的聚簇因子变差。如列的顺序、反向索引、空闲列表或空闲列表组。
提高聚簇因子
堆表的数据存储是无序存储,因此需要使无序变为有序,有如下方法提高聚簇因子:
- 对于表上的多个索引以及组合索引的情形,索引的创建应考虑按经常频繁读取的大范围数据的读取顺序来创建索引
- 定期重构表(针对堆表),也就是使得表与索引列上的数据顺序更接近,注: 是重构表,而不是重建索引
1. 重建索引并不能显剧提高 CF 的值,因为索引列通常是有序的,无序的是原始表上的数据
2. 提取原始表上的数据到一个临时表,禁用依赖于该表的相关约束,truncate 原始表,再将临时表的数据按索引访问顺序填充到原始表 - 使用聚簇表来代替堆表
聚簇因子趋势性
- 创建测试表 TSET 并创建索引
SQL> create table test as select * from dba_objects; Table created SQL> create index idx_test on test(object_id, object_name); Index created
- 查看当前测试表的聚簇因子信息,注意此时的 LAST_ANALYZED 字段为空,说明未收集过统计信息
SQL> select index_name, b.table_name, clustering_factor, a.blocks, b.num_rows, to_char(c.last_analyzed,'YYYY-MM-DD HH24:MI:SS') last_analyzed from dba_segments a, dba_indexes b, dba_tables c where a.segment_name = b.table_name and a.segment_name = c.table_name and b.table_name = 'TEST'; INDEX_NAME TABLE_NAME CLUSTERING_FACTOR BLOCKS NUM_ROWS LAST_ANALYZED -------------------- --------------- ----------------- ---------- ---------- ------------------- IDX_TEST TEST 1333 1280 86130
- 收集表 TEST 的统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SCOTT',
tabname => 'TEST',
estimate_percent => 100,
method_opt => 'for all columns size auto',
no_invalidate => false,
degree => 4,
granularity => 'AUTO',
cascade => true);
end;
/
- 再次查看当前测试表的聚簇因子信息
SQL> select index_name, b.table_name, clustering_factor, a.blocks, b.num_rows, to_char(c.last_analyzed,'YYYY-MM-DD HH24:MI:SS') last_analyzed from dba_segments a, dba_indexes b, dba_tables c where a.segment_name = b.table_name and a.segment_name = c.table_name and b.table_name = 'TEST'; INDEX_NAME TABLE_NAME CLUSTERING_FACTOR BLOCKS NUM_ROWS LAST_ANALYZED -------------------- --------------- ----------------- ---------- ---------- ------------------- IDX_TEST TEST 1382 1280 86130 2021-10-30 12:53:02
查看收集后最新的统计信息,可以看到,查询结果集中 CF 值,趋近于数据块值,说明此时情况相似度很好。
- 插入新的数据并进行提交
SQL> insert into test select * from test;c 86130 rows inserted SQL> commit; Commit complete
- 重新收集表统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SCOTT',
tabname => 'TEST',
estimate_percent => 100,
method_opt => 'for all columns size auto',
no_invalidate => false,
degree => 4,
granularity => 'AUTO',
cascade => true);
end;
/
--随着 INSERT 的操作(数据无序插入),CF 值发生了改变,已经开始趋近于行数。
SQL> select
index_name,
b.table_name,
clustering_factor,
a.blocks,
b.num_rows,
to_char(c.last_analyzed,'YYYY-MM-DD HH24:MI:SS') last_analyzed
from dba_segments a, dba_indexes b, dba_tables c
where a.segment_name = b.table_name
and a.segment_name = c.table_name
and b.table_name = 'TEST';
INDEX_NAME TABLE_NAME CLUSTERING_FACTOR BLOCKS NUM_ROWS LAST_ANALYZED
-------------------- --------------- ----------------- ---------- ---------- -------------------
IDX_TEST TEST 172260 2560 172260 2021-10-30 12:57:37
注: 一个生产环境中,除了 INSERT,还有 UPDATE 和 DELETE 操作,随着这些操作的增多,聚簇因子势必更加趋近于行记录数。
聚簇因子优化
由于影响 CF(CLUSTERING_FACTOR)值主要取决于数据表的数据在数据块中的存储分布情况,因此优化 CF 的重点还是在调整数据表本身。
在 Oracle 数据库中,能够降低目标索引的聚簇因子的唯一方法就是对表中数据按照目标索引的索引键值排序后重新存储。
- 定期按索引列顺序重建表
1. 建议通过 dbms_metadata.get_ddl 提取表结构完整的 DDL 语句,结合 insert order by column 以及 rename table 的方式进行表的重建。
2. 不建议采用 CTAS 方式(create table as select),该方式可能引起后续不必要的麻烦。
SQL> set long 10000;
SQL> select dbms_metadata.get_ddl(object_type => 'TABLE', name => 'TEST', schema => 'SCOTT') from dual;
DBMS_METADATA.GET_DDL(OBJECT_TYPE=>'TABLE',NAME=>'TEST',SCHEMA=>'SCOTT')
--------------------------------------------------------------------------------
CREATE TABLE "SCOTT"."TEST"
( "OWNER" VARCHAR2(30),
"OBJECT_NAME" VARCHAR2(128),
"SUBOBJECT_NAME" VARCHAR2(30),
"OBJECT_ID" NUMBER,
"DATA_OBJECT_ID" NUMBER,
"OBJECT_TYPE" VARCHAR2(19),
"CREATED" DATE,
"LAST_DDL_TIME" DATE,
"TIMESTAMP" VARCHAR2(19),
"STATUS" VARCHAR2(7),
"TEMPORARY" VARCHAR2(1),
"GENERATED" VARCHAR2(1),
"SECONDARY" VARCHAR2(1),
"NAMESPACE" NUMBER,
"EDITION_NAME" VARCHAR2(30)
) SEGMENT CREATION IMMEDIATE
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "USERS"
SQL> select dbms_metadata.get_ddl(object_type => 'INDEX', name => 'IDX_TEST', schema => 'SCOTT') from dual;
DBMS_METADATA.GET_DDL(OBJECT_TYPE=>'INDEX',NAME=>'IDX_TEST',SCHEMA=>'SCOTT')
--------------------------------------------------------------------------------
CREATE INDEX "SCOTT"."IDX_TEST" ON "SCOTT"."TEST" ("OBJECT_ID", "OBJECT_NAME")
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "USERS"
- 重命名原表
SQL> alter table test rename to test_bak; Table altered
- 重建原表及索引
SQL> CREATE TABLE "SCOTT"."TEST" (
"OWNER" VARCHAR2(30),
"OBJECT_NAME" VARCHAR2(128),
"SUBOBJECT_NAME" VARCHAR2(30),
"OBJECT_ID" NUMBER,
"DATA_OBJECT_ID" NUMBER,
"OBJECT_TYPE" VARCHAR2(19),
"CREATED" DATE,
"LAST_DDL_TIME" DATE,
"TIMESTAMP" VARCHAR2(19),
"STATUS" VARCHAR2(7),
"TEMPORARY" VARCHAR2(1),
"GENERATED" VARCHAR2(1),
"SECONDARY" VARCHAR2(1),
"NAMESPACE" NUMBER,
"EDITION_NAME" VARCHAR2(30)
)
SEGMENT CREATION IMMEDIATE
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "USERS";
SQL> CREATE INDEX "SCOTT"."IDX_TEST" ON "SCOTT"."TEST" ("OBJECT_ID", "OBJECT_NAME")
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "USERS";
- 按索引列顺序的方式将原表数据写入新表
SQL> insert /*+ append */ into test select * from test_bak order by object_id, object_name; 172260 rows inserted SQL> commit; Commit complete SQL> drop table test_bak purge; Table dropped
- 重新收集表统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SCOTT',
tabname => 'TEST',
estimate_percent => 100,
method_opt => 'for all columns size auto',
no_invalidate => false,
degree => 4,
granularity => 'AUTO',
cascade => true);
end;
/
- 查看表重建后的聚簇因子
SQL> select index_name, b.table_name, clustering_factor, a.blocks, b.num_rows, to_char(c.last_analyzed,'YYYY-MM-DD HH24:MI:SS') last_analyzed from dba_segments a, dba_indexes b, dba_tables c where a.segment_name = b.table_name and a.segment_name = c.table_name and b.table_name = 'TEST'; INDEX_NAME TABLE_NAME CLUSTERING_FACTOR BLOCKS NUM_ROWS LAST_ANALYZED -------------------- --------------- ----------------- ---------- ---------- ------------------- IDX_TEST TEST 3251 2560 172260 2021-10-30 13:15:43
聚簇因子对性能的影响
非索引列顺序存储数据
- 创建测试表 TEST1 并创建索引(数据无序)
SQL> create table test1 as select * from dba_objects; Table created SQL> insert into test1 select * from dba_objects; 86133 rows inserted SQL> commit; Commit complete SQL> create index idx_test1 on test1(object_id, object_name); Index created
- 收集统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SCOTT',
tabname => 'TEST1',
estimate_percent => 100,
method_opt => 'for all columns size auto',
no_invalidate => false,
degree => 4,
granularity => 'AUTO',
cascade => true);
end;
/
- 查看聚簇因子(数据无序)
SQL> select index_name, b.table_name, clustering_factor, a.blocks, b.num_rows, to_char(c.last_analyzed,'YYYY-MM-DD HH24:MI:SS') last_analyzed from dba_segments a, dba_indexes b, dba_tables c where a.segment_name = b.table_name and a.segment_name = c.table_name and b.table_name = 'TEST1'; INDEX_NAME TABLE_NAME CLUSTERING_FACTOR BLOCKS NUM_ROWS LAST_ANALYZED -------------------- --------------- ----------------- ---------- ---------- ------------------- IDX_TEST1 TEST1 172266 2560 172266 2021-10-30 13:31:11
注: 此时聚簇因子趋近于数据表的行数, 说明 CF 值较差。
- 较差 CF 下的执行计划
1. 逻辑读、物理读、递归调用
SQL> set autotrace traceonly;
SQL> select * from test1 t where t.object_id between 100 and 1000;
已选择1800行。
执行计划
----------------------------------------------------------
Plan hash value: 4122059633
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1765 | 168K| 692 (1)| 00:00:09 |
|* 1 | TABLE ACCESS FULL| TEST1 | 1765 | 168K| 692 (1)| 00:00:09 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("T"."OBJECT_ID"<=1000 AND "T"."OBJECT_ID">=100)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
2624 consistent gets
0 physical reads
0 redo size
94612 bytes sent via SQL*Net to client
1828 bytes received via SQL*Net from client
121 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1800 rows processed
2. 预估行(E-Rows)、真实行(A-Rows), 逻辑读(Buffers)
SQL> alter session set statistics_level = all;
SQL> select * from test1 t where t.object_id between 100 and 1000;
SQL> select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 1ndu7dg81ys04, child number 1
-------------------------------------
select * from test1 t where t.object_id between 100 and 1000
Plan hash value: 4122059633
-------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1800 |00:00:00.01 | 2624 |
|* 1 | TABLE ACCESS FULL| TEST1 | 1 | 1765 | 1800 |00:00:00.01 | 2624 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(("T"."OBJECT_ID"<=1000 AND "T"."OBJECT_ID">=100))
从上述执行计划可知,该目标 SQL 语句 “select * from test1 t where t.object_id between 100 and 1000” 走的是全表扫描(TABLE ACCESS FULL),该目标 SQL 返回的结果集约为 1800 行记录,表 TEST1 总的行记录数为 172266,仅返回约 “1800/172266*100≈1.04%” 的数据,应该走索引范围扫描才对。
按索引列顺序存储数据
- 创建测试表 TEST2 并创建索引(数据有序)
SQL> create table test2 as select * from test1 order by object_id, object_name; Table created SQL> create index idx_test2 on test2(object_id, object_name); Index created
- 收集统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SCOTT',
tabname => 'TEST2',
estimate_percent => 100,
method_opt => 'for all columns size auto',
no_invalidate => false,
degree => 4,
granularity => 'AUTO',
cascade => true);
end;
/
- 查看聚簇因子
SQL> select index_name, b.table_name, clustering_factor, a.blocks, b.num_rows, to_char(c.last_analyzed,'YYYY-MM-DD HH24:MI:SS') last_analyzed from dba_segments a, dba_indexes b, dba_tables c where a.segment_name = b.table_name and a.segment_name = c.table_name and b.table_name = 'TEST2'; INDEX_NAME TABLE_NAME CLUSTERING_FACTOR BLOCKS NUM_ROWS LAST_ANALYZED -------------------- --------------- ----------------- ---------- ---------- ------------------- IDX_TEST2 TEST2 2513 2560 172266 2021-10-30 14:09:04
注: 此时聚簇因子趋近于数据表的数据块数, 说明 CF 值良好。
- 良好 CF 下的执行计划
1. 逻辑读、物理读、递归调用
SQL> set autotrace traceonly;
SQL> select * from test2 t where t.object_id between 100 and 1000;
已选择1800行。
执行计划
----------------------------------------------------------
Plan hash value: 4047680367
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1765 | 168K| 39 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST2 | 1765 | 168K| 39 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TEST2 | 1765 | | 13 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."OBJECT_ID">=100 AND "T"."OBJECT_ID"<=1000)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
274 consistent gets
0 physical reads
0 redo size
64068 bytes sent via SQL*Net to client
1828 bytes received via SQL*Net from client
121 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1800 rows processed
2. 预估行(E-Rows)、真实行(A-Rows), 逻辑读(Buffers)
SQL> alter session set statistics_level = all;
SQL> select * from test2 t where t.object_id between 100 and 1000;
SQL> select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID gb5zhk9d1a45x, child number 0
-------------------------------------
select * from test2 t where t.object_id between 100 and 1000
Plan hash value: 4047680367
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1800 |00:00:00.01 | 274 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST2 | 1 | 1765 | 1800 |00:00:00.01 | 274 |
|* 2 | INDEX RANGE SCAN | IDX_TEST2 | 1 | 1765 | 1800 |00:00:00.01 | 131 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."OBJECT_ID">=100 AND "T"."OBJECT_ID"<=1000)
从上述执行计划可知,该目标 SQL 语句 “select * from test2 t where t.object_id between 100 and 1000” 走的是索引范围扫描(INDEX RANGE SCAN),且次数逻辑读的数量明显小于第一种。
手工调整聚簇因子
通过修改聚簇因子的值,可以让原本走索引范围扫描的执行计划变成走全表扫描。
- 创建测试表 TEST,并在列 OBJECT_ID 上创建单键值的 Btree 索引
SQL> create table test as select * from dba_objects; Table created SQL> create index idx_test on test(object_id); Index created
- 查看执行计划
SQL> select * from test where object_id between 100 and 110;
已选择11行。
执行计划
----------------------------------------------------------
Plan hash value: 2473784974
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 11 | 2277 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST | 11 | 2277 | 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TEST | 11 | | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID">=100 AND "OBJECT_ID"<=110)
从上述执行计划可知,该目标 SQL 走了对索引 IDX_TEST 的索引范围扫描,其成本值(Cost)为 3。
- 使用 Hint 强制让目标 SQL 走全表扫描
SQL> select /*+ full(test) */ * from test where object_id between 100 and 110;
已选择11行。
执行计划
----------------------------------------------------------
Plan hash value: 1357081020
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 11 | 2277 | 343 (1)| 00:00:05 |
|* 1 | TABLE ACCESS FULL| TEST | 11 | 2277 | 343 (1)| 00:00:05 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_ID">=100 AND "OBJECT_ID"<=110)
从上述执行计划可知,现在该 SQL 走了对表 TEST 的全表扫描,其全表扫描的成本值(Cost)为 343。
- 手工调整聚簇因子的值
如果想让上述 SQL 的执行计划从索引范围扫描变为全表扫描(不使用 Hint),那么只需调整聚簇因子的值,使走索引范围扫描的成本值大于走全表扫描的成本值 343 即可达到目的。
begin
dbms_stats.set_index_stats(ownname => 'SCOTT',
indname => 'IDX_TEST',
clstfct => 5000000,
no_invalidate => false);
end;
/
- 查看手工调整后,索引 IDX_TEST 的聚簇因子值
SQL> select index_name, b.table_name, clustering_factor, a.blocks, b.num_rows, to_char(c.last_analyzed,'YYYY-MM-DD HH24:MI:SS') last_analyzed from dba_segments a, dba_indexes b, dba_tables c where a.segment_name = b.table_name and a.segment_name = c.table_name and b.table_name = 'TEST'; INDEX_NAME TABLE_NAME CLUSTERING_FACTOR BLOCKS NUM_ROWS LAST_ANALYZED --------------- ---------- ----------------- ---------- ---------- ------------------- IDX_TEST TEST 5000000 1280 86134 2021-10-30 18:11:16
- 再次执行目标 SQL 并查看其执行计划
SQL> select * from test where object_id between 100 and 110;
已选择11行。
执行计划
----------------------------------------------------------
Plan hash value: 1357081020
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12 | 1176 | 343 (1)| 00:00:05 |
|* 1 | TABLE ACCESS FULL| TEST | 12 | 1176 | 343 (1)| 00:00:05 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_ID"<=110 AND "OBJECT_ID">=100)
从上述执行计划可知,当我们索引 IDX_TEST 的聚簇因子的值调整为 500 万后,目标 SQL 的执行计划确实已从之前的走对索引 IDX_TEST 的索引范围扫描变成现在的走对表 TEST 的全表扫描。
- 使用 Hint 强制让目标 SQL 走索引范围扫描
SQL> select /*+ index(test idx_test) */ * from test where object_id between 100 and 110; 已选择11行。 执行计划 ---------------------------------------------------------- Plan hash value: 2473784974 ---------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 12 | 1176 | 686 (0)| 00:00:09 | | 1 | TABLE ACCESS BY INDEX ROWID| TEST | 12 | 1176 | 686 (0)| 00:00:09 | |* 2 | INDEX RANGE SCAN | IDX_TEST | 12 | | 2 (0)| 00:00:01 | ----------------------------------------------------------------------------------------
从上述执行计划可知,现在该 SQL 走了对索引 IDX_TEST 的索引范围扫描,其成本值(Cost)为 686,远大于全表扫描的成本值 343。
查看索引列值对应的数据块
- 创建数据表 TEST1,并创建 OBJECT_ID 列的单键值索引,无序插入数据
SQL> create table test1 as select * from dba_objects where object_id <= 20; Table created SQL> create index idx_test1 on test1(object_id); Index created
- 查看索引列值对应的数据块
SQL> select object_id, dbms_rowid.rowid_relative_fno(rowid) || '_' || dbms_rowid.rowid_block_number(rowid) location from test1 order by 2, 1;
OBJECT_ID LOCATION
---------- --------------------------------------------------------------------------------
2 4_1795
3 4_1795
4 4_1795
5 4_1795
6 4_1795
7 4_1795
8 4_1795
9 4_1795
10 4_1795
11 4_1795
12 4_1795
13 4_1795
14 4_1795
15 4_1795
16 4_1795
17 4_1795
18 4_1795
19 4_1795
20 4_1795
19 rows selected
从上述查询结果可知,该索引列 OBJECT_ID 的记录都存在于 4 号文件的第 1795 号数据块中。那么此时索引 IDX_TEST1 的聚簇因子应该为 1。
- 收集表 TEST 统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SCOTT',
tabname => 'TEST1',
estimate_percent => 100,
method_opt => 'for all columns size auto',
no_invalidate => false,
degree => 4,
granularity => 'AUTO',
cascade => true);
end;
/
- 查看索引 IDX_TEST1 的聚簇因子
SQL> select index_name, b.table_name, clustering_factor, a.blocks, b.num_rows, to_char(c.last_analyzed,'YYYY-MM-DD HH24:MI:SS') last_analyzed from dba_segments a, dba_indexes b, dba_tables c where a.segment_name = b.table_name and a.segment_name = c.table_name and b.table_name = 'TEST1'; INDEX_NAME TABLE_NAME CLUSTERING_FACTOR BLOCKS NUM_ROWS LAST_ANALYZED --------------- ---------- ----------------- ---------- ---------- ------------------- IDX_TEST1 TEST1 1 8 19 2021-10-30 16:38:25
补充说明
-
对于 alter table move 的操作,可以降低高水位线,但对于优化聚簇因子值而言,意义不大。
-
对于重建索引,聚簇因子值并不会降低,有时还存在些许的增加,需要注意。
参考资料
https://blog.csdn.net/leshami/article/details/8847959
https://www.cnblogs.com/yumiko/p/6036795.html
原创文章,转载请注明出处:http://www.opcoder.cn/article/5/