Pandas 是 Python 的核心数据分析库,它提供了快速、灵活明确的数据结构,能够简单、直观、快速地处理各种类型的数据。
Pandas 能够处理以下类型的数据:
- 与 SQL 或 Excel 表类似的数据
- 有序或无序(非固定频率)的时间序列数据
- 带行列标签的矩阵数据
- 任意其他形式的观测、统计数据集
Pandas 有两个主要的数据结构 Series 与 DataFrame。
Series 对象
Series 是 Python 库中的一种数据结构,它类似一维数组,由一组数据以及与这组数据相关的标签(即索引)组成,或者仅有一组数据而没有索引也可以创建一个简单的 Series 对象。Series 可以存储整数、浮点数、字符串、Python 对象等多种类型的数据。
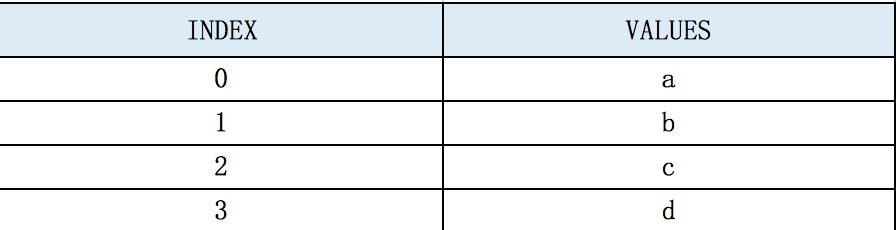
图示
Series 用来表示一维数据结构。
创建
创建 Series 对象时,主要使用 Pandas 的 Series 方法,语法如下:
>>> import pandas as pd >>> s = pd.Series(data, index, dtype, copy)
参数说明:
data: 表示数据,支持 Python 字典、多维数组、标量值(即只有大小,没有方向的量。也就是说,只是一个数值,如 s = pd.Series(5) index: 表示行标签(索引) dtype: 表示数据类型。如果没有,将自动推断数据类型 copy: 复制数据,默认为 False。 返回值: Series 对象
- 通过 Series 的构造方法,参数为列表
>>> import pandas as pd >>> s1 = pd.Series([80, 60, 75]) >>> s1 0 80 1 60 2 75 dtype: int64
- 通过传入 ndarray 创建 Series
>>> import pandas as pd >>> import numpy as np >>> n1 = np.array([11, 22, 33]) >>> s1 = pd.Series(n1) >>> s1 0 11 1 22 2 33 dtype: int64
- 通过传入字典创建 Series
在 Series 的构造函数中传入一个字典,那么字典的 key 则为 index,字典的 value 为 Series 的 values 元素。
>>> import pandas as pd >>> d1 = {'name': 'allen', 'age': 18} >>> s1 = pd.Series(d1) >>> s1 name allen age 18 dtype: object
- 通过传入多维数组创建 Series
>>> import pandas as pd >>> s1 = pd.Series([[11, 22], [33, 55], [66, 77]]) >>> s1 0 [11, 22] 1 [33, 55] 2 [66, 77] dtype: object
- 传入空类型
np.NaN对象
>>> import pandas as pd >>> s1 = pd.Series([59, 89, np.NaN]) >>> s1 0 59.0 1 89.0 2 NaN dtype: float64
索引
创建 Series 对象时会自动生成整数索引,默认值从 0 开始至数据长度减 1。除了使用默认索引,还可以通过 index 参数手动设置索引。
>>> import pandas as pd >>> s1 = pd.Series([88, 60, 75]) >>> s2 = pd.Series([88, 60, 75], index=[1, 2, 3]) >>> s3 = pd.Series([88, 60, 75], index=['小明', '小红', '小芳']) >>> s1 0 88 1 60 2 75 dtype: int64 >>> s2 1 88 2 60 3 75 dtype: int64 >>> s3 小明 88 小红 60 小芳 75 dtype: int64
由于 Series 对象 的 index 是可以重复的,对于位置索引来说无论 index 是否重复都与索引没有关系,但是如果使用标签索引的话,索引出来的结果是一个具有相同 index 的 Series 对象。
>>> import numpy as np >>> import pandas as pd >>> s = pd.Series(np.random.randn(4),index = ['a','a','b','c']) >>> s['a'] a 0.532665 a -0.385468 dtype: float64
- Series 位置索引
位置索引是从 0 开始,[0] 是 Series 的第一个数,[1] 是 Series 的第二个数,依次类推。
>>> import pandas as pd >>> s = pd.Series([88, 60, 75]) >>> s[0] 88 >>> s[1] 60
注: Series 对象不能使用 [-1] 定位索引。
- Series 标签索引
Series 标签索引与位置索引方法类似,用 “[]” 表示,里面是索引名称,注意 若 index 的数据类型是字符串,如果需要获取多个标签索引值,则用 “[[]]” 表示(相当于在 “[]” 中包含一个列表)。
>>> import pandas as pd >>> s1 = pd.Series([88, 60, 75], index=['小明', '小红', '小芳']) # 通过一个标签索引获取值 >>> s1['小明'] 88 # 通过多个标签索引获取值 >>> s1[['小明', '小红']] 小明 88 小红 60 dtype: int64 # index 的数据类型是数值型 >>> s2 = pd.Series([88, 60, 75], index=[1, 2, 3]) >>> s2 1 88 2 60 3 75 >>> s2.index dtype: int64 Int64Index([1, 2, 3], dtype='int64') >>> s2[3] 75
- 点索引
平时使用位置索引以及标签索引已经足够。点索引使用有很多局限性:点索引只适用于 Series 对象的 index 类型为非数值类型时才可以使用;如果 Series 对象中的 index 中有一些索引名称与 Python 的一些关键字或者一些函数名重名的话,会导致无法获取 Series 对象的值。
>>> import numpy as np >>> import pandas as pd >>> s1 = pd.Series(np.random.randn(4), index = ['a','b','c','d']) >>> s1.a -0.36145060796991474 # 索引为数值类型 >>> s2 = pd.Series(np.random.randn(4), index = [1,2,3,4]) >>> s2.1 File "<ipython-input-17-947267327a81>", line 8 s2.1 ^ SyntaxError: invalid syntax # 索引含有关键字 >>> s3 = pd.Series(np.random.randn(4), index = ['a','b','c','def']) >>> s3.def File "<ipython-input-18-f107427e00a9>", line 11 s3.def ^ SyntaxError: invalid syntax
- Series 切片索引
用标签索引做切片,可以包头包尾(即包含了索引开始位置的数据,也包含了索引结束位置的数据)。
>>> import pandas as pd >>> s1 = pd.Series([88, 60, 75], index=['小明', '小红', '小芳']) >>> s1['小明':'小芳'] 小明 88 小红 60 小芳 75 dtype: int64
用位置索引做切片,和 list 列表的用法一样,可以包头不包尾(即包含了索引开始位置的数据,但不包含索引结束位置的数据)。
>>> import pandas as pd >>> s1 = pd.Series([88, 60, 75]) >>> s1[1:3] 1 60 2 75 dtype: int64
- Series 重新索引
reindex 是 Pandas 对象的重要方法,该方法用于创建一个符合新索引的新对象。
>>> import pandas as pd >>> s = pd.Series([4.5,7.2,-5.3,3.6], index=['d','b','a','c']) >>> s d 4.5 b 7.2 a -5.3 c 3.6 dtype: float64
Series 调用 reindex 方法时,会将数据按照新的索引进行排列,如果某个索引之前并不存在,则会引入缺失值。如果不想用 NaN 填充,可以为 fill_value 参数指定值,例如 0:
>>> s2 = s.reindex(['a','b','c','d','e']) >>> s2 a -5.3 b 7.2 c 3.6 d 4.5 e NaN dtype: float64 >>> s3 = s.reindex(['a','b','c','d','e'], fill_value=0) >>> s3 a -5.3 b 7.2 c 3.6 d 4.5 e 0.0 dtype: float64
对于序列数据,比如时间序列,在重建索引时可能会需要进行插值或填值,method 可选参数允许我们使用诸如 ffill 前向填充(和前面数据一样)、bfill 后向填充(和后面数据一样)等方法在重建索引时插值。
>>> s = pd.Series(['blue','purple','yellow'], index=[0,2,4]) >>> s 0 blue 2 purple 4 yellow dtype: object >>> s1 = s.reindex(range(6), method='ffill') >>> s1 0 blue 1 blue 2 purple 3 purple 4 yellow 5 yellow dtype: object >>> s2 = s.reindex(range(6), method='bfill') >>> s2 0 blue 1 purple 2 purple 3 yellow 4 yellow 5 NaN dtype: object
- Series 重置索引
当我们在清洗数据时往往会将带有空值的行删除,此时 Series 对象的 index 将不再是连续的索引了,那么这个时候我们可以使用 reset_index() 方法来重置它们的索引,以便后续的操作。
>>> s = pd.Series(['Coca Cola','Sprite','Coke','Fanta','ThumbsUp'], index=[0,2,4,6,8]) >>> s 0 Coca Cola 2 Sprite 4 Coke 6 Fanta 8 ThumbsUp dtype: object
重置 Series 对象的索引(默认会保留原始索引,并将其转换为列)。
>>> s2 = s.reset_index() >>> s2 index 0 0 0 Coca Cola 1 2 Sprite 2 4 Coke 3 6 Fanta 4 8 ThumbsUp
重置 Series 对象的索引,并删除原始索引。
>>> s3 = s.reset_index(drop=True) >>> s3 0 Coca Cola 1 Sprite 2 Coke 3 Fanta 4 ThumbsUp dtype: object
属性和方法
| 序号 | 属性与方法 | 描述 |
| 1 | ndim | 返回 Series 对象的维数 |
| 2 | shape | 返回 Series 对象的形状 |
| 3 | dtype | 返回 Series 对象中元素的数据类型 |
| 4 | size | 返回 Series 对象中元素的个数 |
| 5 | nbytes | 返回 Series 对象所有元素占用空间的大小,以字节为单位 |
| 6 | axes | 返回行轴标签列表 |
| 7 | T | 返回 Series 对象的转置结果(转置行和列) |
| 8 | index | 返回 Series 对象中的索引 |
| 9 | values | 返回 Series 对象中的数值 |
| 10 | name | 返回 Series 对象的名称或返回 Series 对象的索引名称 |
| 11 | head() | 返回前n行 |
| 12 | tail() | 返回后n行 |
| 13 | unique() | 返回一个无重复元素的 Series 对象 |
| 14 | value_counts() | 统计重复元素出现的次数 |
| 15 | isin() | 判断是否包含某些元素,返回 Series 对象 |
| 16 | isnull() | 判断是否为空,返回布尔类型的 Series 对象 |
| 17 | notnull() | 判断是否非空,返回布尔类型的 Series 对象 |
| 18 | idxmin() | 返回 Series 对象中最小值的索引 |
| 19 | idxmax() | 返回 Series 对象中最大值的索引 |
>>> import pandas as pd >>> s1 = pd.Series([1, 3, 5, 7, 9], index=['a','b','c','d','e']) >>> s1 a 1 b 3 c 5 d 7 e 9 dtype: int64
- ndim
>>> s1.ndim 1
- shape
>>> s1.shape (5,)
- dtype
>>> s1.dtype dtype('int64')
- size
>>> s1.size 5
- nbytes
>>> s1.nbytes 40
- axes
>>> s1.axes [RangeIndex(start=0, stop=5, step=1)]
- T
>>> s1.T 0 1 1 3 2 5 3 7 4 9 dtype: int64
- index
>>> s1.index Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
- values
>>> s1.values array([1, 3, 5, 7, 9])
- name
>>> s1.name None
name 属性也可用于动态创建 Series 对象名称和 Series 索引名称,
>>> s2 = pd.Series([1,3,5,7], index=['a','b','c','d'], name="Series的名称") >>> s2 a 1 b 3 c 5 d 7 Name: Series的名称, dtype: int64 >>> s2.name 'Series的名称'
- head()
>>> s1.head(2) a 1 b 3 dtype: int64
- tail()
>>> s1.tail(2) d 7 e 9 dtype: int64
- unique()
>>> s3 = pd.Series([1, 2, 2, 3, 3, 3]) >>> s3.unique()) array([1, 2, 3])
- value_counts()
>>> s1.value_counts() 7 1 5 1 3 1 9 1 1 1 dtype: int64
- isin()
>>> condition = [1, 3] >>> s1.isin(condition) a True b True c False d False e False dtype: bool
返回的布尔类型 Series 传给原 Series 可以进行筛选满足条件的值
>>> s5 = s1.isin(condition).values >>> s5 array([ True, True, False, False, False]) >>> s1[s5] a 1 b 3 dtype: int64
- isnull()
>>> s6 = pd.Series([1, 2, 3, None]) >>> s6.isnull() 0 False 1 False 2 False 3 True dtype: bool
- notnull()
>>> s6.notnull() 0 True 1 True 2 True 3 False dtype: bool
- idxmin()
>>> s1.idxmin() 'a'
- idxmax()
>>> s1.idxmax() 'e'
数据操作
- 增加
为 Series 对象添加新值的方式有两种:
1. 使用 series.append(pd.Series(data,index)) 的方式添加,这种方式会返回一个新的 Series 对象,这种方式最大的特点就是可以一次添加多个 Series 值;
2. 使用 series["new_index"] = value 的方式添加,这种方式会直接在原来的 Series 对象上进行修改,并且这种方式每次只能够添加一个 Series 值。
import pandas as pd >>> s = pd.Series(1,index=['a']) # 使用 append 方式添加多个 Series 值,返回新的 Series 对象 >>> s2 = s.append(pd.Series([2,3],index=['b','c'])) >>> s2 a 1 b 2 c 3 dtype: int64 # 使用 s[new_index]=value 方式添加 >>> s['d'] = 4 >>> s a 1 d 4 dtype: int64
- 修改
修改 Series 对象值的方式有两种:
1. 通过索引修改 Series 对象的值;
2. 调用 apply() 方法,该方法接受一个函数作为其参数,对 Series 对象的值进行批量处理。
>>> import pandas as pd >>> s = pd.Series([1,2,3,4], index = ['a','b','c','d']) # 通过索引修改 Series 对象的值 >>> s['a'] = 100 >>> s a 100 b 2 c 3 d 4 dtype: int64 # 通过 apply() 方法对 Series 对象的值进行批量处理 def s_add(x): return x + 2 >>> s2 = s.apply(s_add) >>> s2 a 102 b 4 c 5 d 6 dtype: int64
- 删除
删除 Series 对象值的方式有三种:
1. 使用 del 关键字删除,这种方式会直接在原来的 Series 对象上进行删除;
2. 使用 pop() 方法删除,这种方式会直接在原来的 Series 对象上进行删除,并且返回被删除的值;
3. 使用 drop() 方法删除,这种方式不会直接在原来的 Series 对象上进行删除,除非指定了 inplace=True。
>>> import pandas as pd >>> s = pd.Series([1,2,3,4], index = ['a','b','c','d']) >>> del s['a'] >>> s b 2 c 3 d 4 dtype: int64 >>> s.pop('c') 3 >>> s b 2 d 4 dtype: int64 >>> s2 = pd.Series([1,2,3,4], index = ['a','b','c','d']) >>> s2.drop('a') b 2 c 3 d 4 dtype: int64 >>> s2 a 1 b 2 c 3 d 4 dtype: int64 >>> s3 = pd.Series([1,2,3,4], index = ['a','b','c','d']) >>> s3.drop('a', inplace=True) None >>> s3 b 2 c 3 d 4 dtype: int64
- 查询
查询 Series 对象值的方式有三种:
1. 通过索引访问 Series 对象值;
2. 通过 loc 方法访问 Series 对象值;
3. 通过 iloc 方法访问 Series 对象值。
>>> import pandas as pd >>> import numpy as np >>> s = pd.Series(np.arange(10), index=['A1','A2','A3','A4','A5','A6','A7','A8','A9','A10']) >>> s A1 0 A2 1 A3 2 A4 3 A5 4 A6 5 A7 6 A8 7 A9 8 A10 9 dtype: int32 >>> s[0:6] A1 0 A2 1 A3 2 A4 3 A5 4 A6 5 dtype: int32 >>> s.loc['A1':'A6'] A1 0 A2 1 A3 2 A4 3 A5 4 A6 5 dtype: int32 >>> s.iloc[0:6] A1 0 A2 1 A3 2 A4 3 A5 4 A6 5 dtype: int32
数据运算
Series 对象的运算是针对 values 中的每一个值的。
- 加法
>>> import pandas as pd >>> s1 = pd.Series([0, 1, 2, 3, 4, 5]) >>> s2 = pd.Series([-5, -4, -3, -2, -1, 0]) >>> s1.add(s2) 0 -5 1 -3 2 -1 3 1 4 3 5 5 dtype: int64 >>> s1 + s2 0 -5 1 -3 2 -1 3 1 4 3 5 5 dtype: int64
- 减法
>>> s1.sub(s2) 0 5 1 5 2 5 3 5 4 5 5 5 dtype: int64 >>> s1 - s2 0 5 1 5 2 5 3 5 4 5 5 5 dtype: int64
- 乘法
>>> s1.mul(s2) 0 0 1 -4 2 -6 3 -6 4 -4 5 0 dtype: int64 >>> s1 * s2 0 0 1 -4 2 -6 3 -6 4 -4 5 0 dtype: int64
- 除法
>>> s1.div(s2) 0 -0.000000 1 -0.250000 2 -0.666667 3 -1.500000 4 -4.000000 5 inf dtype: float64 >>> s1 / s2 0 -0.000000 1 -0.250000 2 -0.666667 3 -1.500000 4 -4.000000 5 inf dtype: float64
- 取商
>>> s1.floordiv(s2) 0 0 1 -1 2 -1 3 -2 4 -4 5 0 dtype: int64
- 取模
>>> s1.mod(s2) 0 0 1 -3 2 -1 3 -1 4 0 5 0 dtype: int64
数据统计
| 序号 | 属性与方法 | 描述 |
| 1 | all() | 判断 Series 对象中所有的值是否全部为真 |
| 2 | any() | 判断 Series 对象中所有的值是否有一个为真 |
| 3 | sum() | 返回 Series 对象的和 |
| 4 | cumsun() | 返回 Series 对象的累加值 |
| 5 | pct_change() | 返回 Series 对象的增长率 |
| 6 | prod() | 返回 Series 对象的乘积 |
| 7 | cumprod() | 返回 Series 对象的累乘积 |
| 8 | max() | 返回 Series 对象的最大值 |
| 9 | min() | 返回 Series 对象的最小值 |
| 10 | nlargest(n) | 返回 Series 对象中 n 个最大值 |
| 11 | nsmallest(n) | 返回 Series 对象中 n 个最小值 |
| 12 | mean() | 返回 Series 对象的平均值 |
| 13 | median() | 返回 Series 对象的中位数 |
| 14 | quantile() | 返回 Series 对象的分位数 |
| 15 | std() | 返回 Series 对象的标准差 |
| 16 | var() | 返回 Series 对象的方差 |
| 17 | describe() | 返回统计相关的数据信息 |
| 18 | kurt() | 返回 Series 对象的峰度 |
| 19 | skew() | 返回 Series 对象的偏度 |
| 20 | cov() | 返回两个 Series 对象的协方差 |
| 21 | corr() | 返回两个 Series 对象的相关性系数 |
>>> import pandas as pd >>> s = pd.Series([0, 1, 3, 5, 7, 9], index=['a','b','c','d','e','f']) >>> s a 0 b 1 c 3 d 5 e 7 f 9 dtype: int64
- all()
判断 Series 对象中所有的值是否全部为真,因为存在 0 所以返回 False。
>>> s.all() False
- any()
判断 Series 对象中所有的值是否有一个为真
>>> s.any() True
- sum()
返回 Series 对象的和。
>>> s.sum() 25
- cumsun()
返回 Series 对象的累加值。
>>> s.cumsum() a 0 b 1 c 4 d 9 e 16 f 25 dtype: int64
- pct_change()
将每个值与其前一个值进行比较,并计算变化百分比。
>>> s.pct_change() a NaN b inf c 2.000000 d 0.666667 e 0.400000 f 0.285714 dtype: float64
- prod()
返回 Series 对象的累乘积。
>>> s.cumprod() a 0 b 0 c 0 d 0 e 0 f 0 dtype: int64 >>> s[1:].cumprod() b 1 c 3 d 15 e 105 f 945 dtype: int64
- cumprod()
>>> s.cumprod() a 0 b 0 c 0 d 0 e 0 f 0 dtype: int64 >>> s[1:].cumprod() b 1 c 3 d 15 e 105 f 945 dtype: int64
- max()
返回 Series 对象的最大值。
>>> s.max() 9
- min()
返回 Series 对象的最小值。
>>> s.min() 0
- nlargest(n)
返回 Series 对象中 n 个最大值。
>>> s.nlargest(2) f 9 e 7 dtype: int64
- nsmallest(n)
返回 Series 对象中 n 个最小值。
>>> s.nsmallest(3) a 0 b 1 c 3 dtype: int64
- mean()
mean 方法用于获取平均值,需要注意的是如果 values 里含有 NaN,可以使用 mean 方法的参数避开 NaN,默认情况下启用了 skipna=True 避开 NaN 值;如果需要考虑 NaN 可以使 skipna=False。
>>> s2 = pd.Series([1,3,None,7,9], index=['a','b','c','d','e']) >>> s2 a 1.0 b 3.0 c NaN d 7.0 e 9.0 dtype: float64 >>> s2.mean() 5.0 >>> s2.mean(skipna=False) nan
- median()
返回 Series 对象的中位数。
>>> s.median() 4.0
- quantile()
返回 Series 对象的分位数。
>>> s.quantile(0.25) 1.5 >>> s.quantile(0.5) 4.0 >>> s.quantile(0.75) 6.5
- std()
返回 Series 对象的标准差。
>>> s.std() 3.488074922742725
- var()
返回 Series 对象的方差。
>>> s.var() 12.166666666666666
- describe()
返回Series 对象和统计相关的数据信息。
>>> s.describe() count 6.000000 mean 4.166667 std 3.488075 min 0.000000 25% 1.500000 50% 4.000000 75% 6.500000 max 9.000000 dtype: float64
- kurt()
返回 Series 对象的峰度。
>>> s.kurt() -1.4526552824169636
- skew()
返回 Series 对象的偏度。
>>> s.skew() 0.21600013595516943
- cov()
返回两个 Series 对象的协方差,NaN 将被自动排除。
>>> s1 = pd.Series(np.random.randn(5)) >>> s2 = pd.Series(np.random.randn(5)) >>> s1.cov(s2) -0.04167430274373021
- corr()
返回两个 Series 对象的相关性系数。
>>> s1 = pd.Series(np.random.randn(5)) >>> s2 = pd.Series(np.random.randn(5)) >>> s1.corr(s2) 0.3500602926449502
过滤/筛选值
可以通过布尔选择器,也就是条件筛选来过滤一些特定的值,从而仅仅获取满足条件的值。过滤 Series 对象的值的方式分为两种:
- 单条件筛选
- 多条件筛选
>>> import pandas as pd >>> s = pd.Series([1,2,3,4],index = ["a","b","c","d"]) # 布尔选择器 >>> s < 3 a True b True c False d False dtype: bool # 单条件查询 >>> s[s < 3] a 1 b 2 dtype: int64 # 多条件查询 >>> s[(s > 2) & (s < 4)] c 3 dtype: int64
缺失值处理
在我们遇到的一些数据中会有缺失值的情况,我们会将这些缺失值删除或者插入其他值替代。
- 创建一个带缺失值的 Series 对象
>>> import pandas as pd >>> s = pd.Series([1, 2, None, 4]) >>> s 0 1.0 1 2.0 2 NaN 3 4.0 dtype: float64
- 判断 value 值是否为缺失值
# isnull() 判断缺失值 >>> s.isnull() 0 False 1 False 2 True 3 False dtype: bool # notnull() 判断非缺失值 >>> s.notnull() 0 True 1 True 2 False 3 True dtype: bool
- 删除缺失值
# 使用 dropna() 删除所有的缺失值并返回新的 Series对象 >>> s.dropna() 0 1.0 1 2.0 3 4.0 dtype: float64 # 使用 isnull() 通过布尔筛选过滤出非缺失值 >>> s[~s.isnull()] 0 1.0 1 2.0 3 4.0 dtype: float64 # 使用 notnull() 通过布尔筛选过滤出非缺失值 >>> s[s.notnull()] 0 1.0 1 2.0 3 4.0 dtype: float64
- 使用 fillna() 填充缺失值
# 使用指定值填充缺失值 >>> s.fillna(value = 0) 0 1.0 1 2.0 2 0.0 3 4.0 dtype: float64 # 使用前向填充 ffill >>> s.fillna(method = 'ffill') 0 1.0 1 2.0 2 2.0 3 4.0 dtype: float64 # 使用后向填充 bfill >>> s.fillna(method = 'bfill') 0 1.0 1 2.0 2 4.0 3 4.0 dtype: float64
排序
可以使用 sort_index() 方法通过索引和使用 sort_values() 方法通过值对 Series 对象进行排序。
- sort_index()
默认按从小到大的顺序对索引进行排序(升序),可通过修改参数 ascending=False 来进行降序排序。
>>> s = pd.Series([1,None,5,7,0], index=['a','c','e','b','d']) >>> s a 1.0 c NaN e 5.0 b 7.0 d 0.0 dtype: float64 >>> s.sort_index() a 1.0 b 7.0 c NaN d 0.0 e 5.0 dtype: float64 >>> s.sort_index(ascending=False) e 5.0 d 0.0 c NaN b 7.0 a 1.0 dtype: float64
- sort_values()
默认按从小到大的顺序对值进行排序,可通过修改参数 ascending=False 来进行降序排序。
>>> s = pd.Series([1,None,5,7,0], index=['a','c','e','b','d']) >>> s a 1.0 c NaN e 5.0 b 7.0 d 0.0 dtype: float64 >>> s.sort_values() d 0.0 a 1.0 e 5.0 b 7.0 c NaN dtype: float64 >>> s.sort_values(ascending=False) b 7.0 e 5.0 a 1.0 d 0.0 c NaN dtype: float64
排名
默认情况下,rank() 通过将平均排名分配到每个组打破平级关系。也就是说,如果有两个数值一样,那这两个数值的和再除以 2 就是他们的排名。
>>> import pandas as pd >>> s = pd.Series([80, 60, 90, 70, 95, 80], index=['A1','A2','A3','A4','A5','A6']) >>> s A1 80 A2 60 A3 90 A4 70 A5 95 A6 80 dtype: int64
- method=average
默认值,即在相等分组中,为各值分配平均排名。
>>> s.rank() A1 3.5 A2 1.0 A3 5.0 A4 2.0 A5 6.0 A6 3.5 dtype: float64
索引为 "A2" 的值最小(60),所以其排名为 1.0;索引为 "A4" 的值第二小(70),所以其排名为 2.0;索引为 "A1" 和 "A6" 的值第三小(80),根据为各组分配一个平均排名这一规则,会取 3.0 和 4.0 的平均值作为其排名,所以这两个值的排名都为 3.5;索引为 "A3" 的值第五小(90),所以其排名为 5.0;索引为 "A5" 的值第六小(95),所以其排名为 6.0。
- method=min
使用整个分组的最小排名,对于相同的值都取小的排名。
>>> s.rank(method='min') A1 3.0 A2 1.0 A3 5.0 A4 2.0 A5 6.0 A6 3.0 dtype: float64
索引为 "A1" 和 "A6" 的值相同,根据相同的值都取小的排名这一规则,会取 3.0 和 4.0 的最小值作为其排名,所以这两个值的排名都为 3.0。
- method=max
是用整个分组的最大排名,对于相同的值都取大的排名。
>>> s.rank(method='max') A1 4.0 A2 1.0 A3 5.0 A4 2.0 A5 6.0 A6 4.0 dtype: float64
索引为 "A1" 和 "A6" 的值相同,根据相同的值都取大的排名这一规则,会取 3.0 和 4.0 的最大值作为其排名,所以这两个值的排名都为 4.0。
- method=first
按值在原始数据中的出现顺序分配排名。
>>> s.rank(method='first') A1 3.0 A2 1.0 A3 5.0 A4 2.0 A5 6.0 A6 4.0 dtype: float64
索引为 "A1" 和 "A6" 的值相同,根据出现顺序分配排名这一规则,索引为 "A1" 的排名是 3.0,索引为 "A6" 的排名是 4.0。
- method=dense
类似于 min,区别在于使用 min 排名,索引为 "A3" 的值排名为 5.0(排名不连续);而使用 dense 排名,索引为 "A3" 的值排名为 4.0(排名连续)。
>>> s.rank(method='dense') A1 3.0 A2 1.0 A3 4.0 A4 2.0 A5 5.0 A6 3.0 dtype: float64
- 含有空值的排名
当数据中有空值时,默认空值是不参与排名的,但可以通过 na_option 参数指定空值的排名方式。
>>> import pandas as pd >>> s = pd.Series([80, 60, None, 70, 95, 80], index=['A1','A2','A3','A4','A5','A6']) >>> s A1 80.0 A2 60.0 A3 NaN A4 70.0 A5 95.0 A6 80.0 dtype: float64 # 空值的默认排名 >>> s.rank(method='dense') A1 3.0 A2 1.0 A3 NaN A4 2.0 A5 4.0 A6 3.0 dtype: float64 # 将最小等级分配给空值 >>> s.rank(method='dense', na_option='top') A1 4.0 A2 2.0 A3 1.0 A4 3.0 A5 5.0 A6 4.0 dtype: float64 # 将最大等级分配给空值 >>> s.rank(method='dense', na_option='bottom') A1 3.0 A2 1.0 A3 5.0 A4 2.0 A5 4.0 A6 3.0 dtype: float64
- 降序排名
默认按照升序的方式排名,但可以通过 ascending 参数指定为降序排名。
>>> import pandas as pd >>> s = pd.Series([80, 60, 90, 70, 95, 80], index=['A1','A2','A3','A4','A5','A6']) >>> s.rank(method='dense', ascending=False) A1 3.0 A2 5.0 A3 2.0 A4 4.0 A5 1.0 A6 3.0 dtype: float64
DataFrame 对象
DataFrame 是由多种类型的列组成的二维表数据结构,类似于 Excel、SQL 或 Series 对象构成的字典。
图解 DataFrame 对象
DataFrame 数据结构与关系型表格类似,是多维的 Series,不过这些 Series 对象共用一个索引。

创建 DataFrame 对象
创建 DataFrame 对象主要使用 Pandas 模块的 DataFrame 方法,语法如下:
import pandas as pd s=pd.DataFrame(data, index, columns, dtype, copy)
参数说明:
data: 表示数据,可以是 ndarray 数组、Series 对象、列表、字典等 index: 表示行标签(索引) columns: 表示列标签(索引) dtype: 每一列数据的数据类型 copy: 复制数据,默认为 false。 返回值: DataFrame 对象
- 通过二维数组创建 DataFrame 对象
import pandas as pd # 解决数据输出时列名不对齐的问题 pd.set_option('display.unicode.east_asian_width', True) data = [[110, 105, 199], [105, 88, 115], [109, 120, 130]] index = [0, 1, 2] columns = ['语文', '数学', '英语'] df = pd.DataFrame(data=data, index=index, columns=columns) print(df) 语文 数学 英语 0 110 105 199 1 105 88 115 2 109 120 130
- 通过字典创建 DataFrame 对象
import pandas as pd pd.set_option('display.unicode.east_asian_width', True) df = pd.DataFrame({ '语文': [110, 105, 199], '数学': [105, 88, 115], '英语': [109, 120, 130], '班级': '高三A班' }, index=[0, 1, 2] ) print(df) 语文 数学 英语 班级 0 110 105 109 高三A班 1 105 88 120 高三A班 2 199 115 130 高三A班 # 使用 columns 参数指定列顺序并使用 index 参数指定行索引 import pandas as pd scientists = pd.DataFrame( data = { 'Occupation':['Chemist','Statistician'], 'Born':['1920-07-25','1876-06-23'], 'Died':['1958-04-16','1937-10-16'], 'Age':[37,61] }, index = ['Rosaline Franklin','William'], columns = ['Occupation','Born','Died','Age'] ) print(scientists) Occupation Born Died Age Rosaline Franklin Chemist 1920-07-25 1958-04-16 37 William Statistician 1876-06-23 1937-10-16 61
- 通过 Series 创建 DataFrame 对象
import pandas as pd df=pd.DataFrame.from_dict({ 'age': pd.Series([23, 33, 37, 51], index=['Shawn', 'Olivia', 'Gene', 'Herry']), 'gender': pd.Series(['male', 'male', 'female', 'female'], index=['Shawn', 'Olivia', 'Gene', 'Herry']) }) print(df) age gender Shawn 23 male Olivia 33 male Gene 37 female Herry 51 female
- 利用 tuple 合并数据
import pandas as pd name = ['Tom', 'Krish', 'Nick', 'Juli'] age = [23, 33, 37, 51] gender = ['male', 'female', 'female', 'male'] list_of_tuples = list(zip(name, age, gender)) df = pd.DataFrame(list_of_tuples, columns = ['name', 'age', 'gender']) print(df) name age gender 0 Tom 23 male 1 Krish 33 female 2 Nick 37 female 3 Juli 51 male
索引
属性和方法
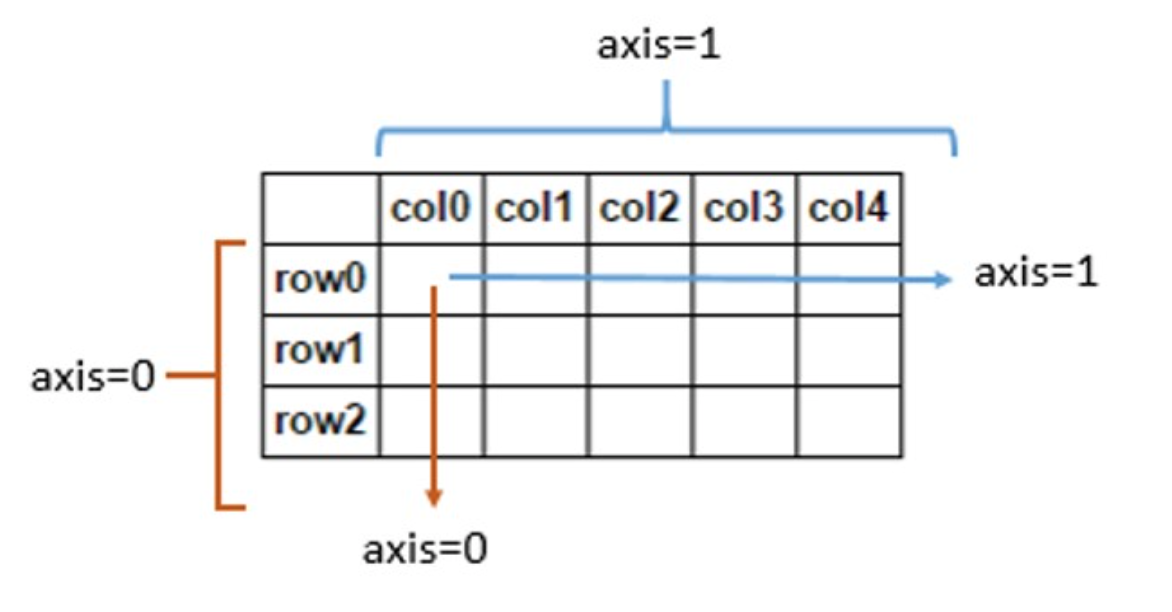
参数 axis = 0 表示沿着每一列或行标签(行索引)向下执行对应的方法;axis = 1 表示沿着每一行或者列标签横向执行对应的方法,默认值为 0
| 序号 | 属性和方法 | 描述 |
| 1 | values | 查看所有元素的值 |
| 2 | dtypes | 查看所有元素的类型 |
| 3 | index | 查看所有元素的行标签(行索引) |
| 4 | columns | 查看所有元素的列标签 |
| 5 | T | 行列转置 |
| 6 | info | 查看索引、数据类型和内存信息 |
| 7 | shape | 查看行数和列数,[0] 表示行;[1] 表示列 |
| 8 | loc | 以行名和列名作为参数,抽取整行或整列数据,当只有一个参数时,默认是行名 |
| 9 | iloc | 以行和列位置索引作为参数,0 表示第一行,1 表示第二行。抽取整行或整列数据,当只有一个参数时,默认是行索引 |
| 10 | head() | 查看前 n 条数据,默认 5 条 |
| 11 | tail() | 查看后 n 条数据,默认 5 条 |
| 12 | describe() | 查看每列的统计汇总信息 |
| 13 | count() | 返回所请求轴(axis)的非 NaN 的元素个数 |
| 14 | unique() | 返回列的所有唯一值 |
| 15 | value_counts() | 返回一组数据中值出现的次数 |
| 16 | max() | 返回所请求轴(axis)的最大值 |
| 17 | min() | 返回所请求轴(axis)的最小值 |
| 18 | idxmax() | 返回最大值所在的索引位置 |
| 19 | idxmin() | 返回最小值所在的索引位置 |
| 20 | mean() | 返回所请求轴(axis)的平均值 |
| 21 | median() | 返回所请求轴(axis)的中位数 |
| 22 | mod() | 返回 DataFrame 和其他元素的模(余数) |
| 23 | prod() | 返回所请求轴(axis)的值的乘积 |
| 24 | var() | 返回所请求轴(axis)的值的方差 |
| 25 | std() | 返回所请求轴(axis)的值的标准差 |
| 26 | isnull() | 检查 DataFrame 对象中的空值,空值为 True |
| 27 | notnull() | 检查 DataFrame 对象中的空值,非空值为 True |
import pandas as pd pd.set_option('display.unicode.east_asian_width', True) data = [[110, 105, 199], [105, 88, 115], [109, 120, 130]] index = ['a', 'b', 'c'] columns = ['A', 'B', 'C'] df = pd.DataFrame(data=data, index=index, columns=columns) print(df) A B C a 110 105 199 b 105 88 115 c 109 120 130
- values
print(df.values) [[110 105 199] [105 88 115] [109 120 130]]
- dtypes
print(df.dtypes) A int64 B int64 C int64 dtype: object
- index
print(df.index) Index(['a', 'b', 'c'], dtype='object')
- columns
print(df.columns) Index(['A', 'B', 'C'], dtype='object')
- T
print(df.T) a b c A 110 105 109 B 105 88 120 C 199 115 130
- info
print(df.info) <bound method DataFrame.info of A B C a 110 105 199 b 105 88 115 c 109 120 130>
- shape
# 查看行数和列数 print(df.shape) (3, 3) # 查看行数 print(df.shape[0]) 3 # 查看列数 print(df.shape[1]) 3
loc 和 iloc 属性可用于获取行、列或二者的子集。loc 和 iloc 的一般语法是使用带逗号的方括号。逗号左边是待取子集的行值,逗号右边是待取子集的列值,即 df.loc[[行名],[列名]] 或 df.iloc[[行索引],[列索引]]。
- loc
# 抽取第 1 行,Python 从 0 开始计数 print(df.loc[0]) A 110 B 105 C 199 Name: a, dtype: int64 # 抽取第 'A' 列 print(df.loc[:,'A']) a 110 b 105 c 109 Name: A, dtype: int64 # 抽取第 'a' 行至第 'c' 行 print(df.loc['a':'c']) A B C a 110 105 199 b 105 88 115 c 109 120 130 # 抽取最后一行 print(df.head(n=1)) A B C c 109 120 130
- iloc
# 抽取第一行(行位置索引为 0) print(df.iloc[0]) A 110 B 105 C 199 Name: a, dtype: int64 # 抽取第一至第二列(列位置索引为 0 ~ 1) print(df.iloc[:,[0,1]]) A B a 110 105 b 105 88 c 109 120 # 抽取最后一行 print(df.iloc[-1]) A 109 B 120 C 130 Name: c, dtype: int64 # 传入整数列表来获取多行 print(df.iloc[[1,2]]) A B C b 105 88 115 c 109 120 130
注: 使用 iloc 时,可以传入 -1 来获取最后一行数据,而在使用 loc 时不能这样做。
- head()
print(df.head()) A B C a 110 105 199 b 105 88 115 c 109 120 130 print(df.head(1)) A B C a 110 105 199
- tail()
print(df.tail()) A B C a 110 105 199 b 105 88 115 c 109 120 130 print(df.tail(1)) A B C c 109 120 130
- describe()
print(df.describe()) A B C count 3.000000 3.000000 3.000000 mean 108.000000 104.333333 148.000000 std 2.645751 16.010413 44.799554 min 105.000000 88.000000 115.000000 25% 107.000000 96.500000 122.500000 50% 109.000000 105.000000 130.000000 75% 109.500000 112.500000 164.500000 max 110.000000 120.000000 199.000000
- count()
print(df.count()) A 3 B 3 C 3 dtype: int64 print(df.count(axis=1)) a 3 b 3 c 3 dtype: int64
- unique()
对于 unique() 的使用,需要特别注意。unique() 函数是针对 Series 对象的操作,即针对于 df 的某一列进行操作,因此没有 axis 参数。unique() 不仅可以针对数字去重,还可以针对字符串去重。
print(df['C'].unique()) [199 115 130]
- value_counts()
print(df['A'].value_counts()) 109 1 110 1 105 1 Name: A, dtype: int64
- max()
print(df.max()) A 110 B 120 C 199 dtype: int64 print(df.max(axis=1)) a 199 b 115 c 130 dtype: int64
- min()
print(df.min()) A 105 B 88 C 115 dtype: int64 print(df.min(axis=1)) a 105 b 88 c 109 dtype: int64
- idxmax()
print(df.idxmax()) A a B c C a dtype: object
- idxmin()
print(df.idxmin()) A b B b C b dtype: object
- mean()
print(df.mean()) A 108.000000 B 104.333333 C 148.000000 dtype: float64 print(df.mean(axis=1)) a 138.000000 b 102.666667 c 119.666667 dtype: float64
- median()
print(df.median()) A 109.0 B 105.0 C 130.0 dtype: float64 print(df.median(axis=1)) a 110.0 b 105.0 c 120.0 dtype: float64
- mod()
print(df.mod(3)) A B C a 2 0 1 b 0 1 1 c 1 0 1
- prod()
print(df.prod()) A 1258950 B 1108800 C 2975050 dtype: int64 print(df.prod(axis=1)) a 2298450 b 1062600 c 1700400 dtype: int64
- var()
print(df.var()) A 7.000000 B 256.333333 C 2007.000000 dtype: float64 print(df.var(axis=1)) a 2797.000000 b 186.333333 c 110.333333 dtype: float64
- std()
print(df.std()) A 2.645751 B 16.010413 C 44.799554 dtype: float64 print(df.std(axis=1)) a 52.886671 b 13.650397 c 10.503968 dtype: float64
- isnull()
print(df.isnull()) A B C a False False False b False False False c False False False
- notnull()
print(df.notnull()) A B C a True True True b True True True c True True True
数据操作
- 列选择
# 通过列标签来获取某一列的值 import pandas as pd data = { 'one':pd.Series([1,2,3],index = ['a','b','c']), 'two':pd.Series([1,2,3,4],index = ['a','b','c','d']) } df = pd.DataFrame(data) print(df['one']) a 1.0 b 2.0 c 3.0 d NaN Name: one, dtype: float64
- 列添加
import pandas as pd data = { 'one':pd.Series([1,2,3],index = ['a','b','c']), 'two':pd.Series([1,2,3,4],index = ['a','b','c','d']) } df = pd.DataFrame(data) df['three'] = pd.Series([10,20,30],index = ['a','b','c']) print(df) one two three a 1.0 1 10.0 b 2.0 2 20.0 c 3.0 3 30.0 d NaN 4 NaN
- 列修改
# 通过列名进行修改 import pandas as pd data = { 'one':pd.Series([1,2,3],index = ['a','b','c']), 'two':pd.Series([1,2,3,4],index = ['a','b','c','d']) } df = pd.DataFrame(data) df['two'] = [2,3,7,9] print(df) one two a 1.0 2 b 2.0 3 c 3.0 7 d NaN 9
- 列删除
import pandas as pd data = { 'one':pd.Series([1,2,3],index = ['a','b','c']), 'two':pd.Series([1,2,3,4],index = ['a','b','c','d']), 'three':pd.Series([10,20,30],index = ['a','b','c']) } df = pd.DataFrame(data) # 使用 del() 删除列 del(df['three']) # 使用 pop 删除 df.pop('two') print(df) one a 1.0 b 2.0 c 3.0 d NaN
- 行选择
import pandas as pd data = { 'one':pd.Series([1,2,3],index = ['a','b','c']), 'two':pd.Series([1,2,3,4],index = ['a','b','c','d']), 'three':pd.Series([10,20,30],index = ['a','b','c']) } df = pd.DataFrame(data) # 通过将行标签传递给 loc 函数来选择行 print(df.loc['a']) one 1.0 two 1.0 three 10.0 Name: a, dtype: float64 # 通过将索引位置传递给 iloc 函数来选择行 print(df.iloc[2]) one 3.0 two 3.0 three 30.0 Name: c, dtype: float64 # 行切片 print(df[1:3]) one two three b 2.0 2 20.0 c 3.0 3 30.0
- 行添加
import pandas as pd data = { 'one':pd.Series([1,2,3],index = ['a','b','c']), 'two':pd.Series([1,2,3,4],index = ['a','b','c','d']), 'three':pd.Series([10,20,30],index = ['a','b','c']) } df = pd.DataFrame(data) # 使用 loc 函数直接添加一行 df.loc['e'] = [11,223,33] # 使用 append() 函数将新行添加到 DataFrame 对象 data2 = pd.DataFrame([{'one':58,'two':59,'three':60}],index = ['f']) df = df.append(data2) print(df) one two three a 1.0 1 10.0 b 2.0 2 20.0 c 3.0 3 30.0 d NaN 4 NaN e 11.0 223 33.0 f 58.0 59 60.0
- 行删除
import pandas as pd data = { 'one':pd.Series([1,2,3],index = ['a','b','c']), 'two':pd.Series([1,2,3,4],index = ['a','b','c','d']), 'three':pd.Series([10,20,30],index = ['a','b','c']) } df = pd.DataFrame(data) df = df.drop('c') print(df) one two three a 1.0 1 10.0 b 2.0 2 20.0 d NaN 4 NaN
数据运算
由于 DataFrame 对象中的每一元素都由其行列索引唯一确定,也就是说 DataFrame 对象中的每一元素都有一个(行索引、列索引)构成的坐标 。因此对于不同的 DataFrame 对象,只有索引匹配上的数据,对应元素才计算;对于没有匹配上的数据,返回的就是 NaN 值。
- DataFrame 对象与标量之间的运算
import pandas as pd import numpy as np data = [[np.nan,1,1,1,1], [2,2,np.nan,2,2], [3,3,3,3,3], [4,np.nan,4,4,4]] df = pd.DataFrame(data, columns=list("abcde")) print(df) a b c d e 0 NaN 1.0 1.0 1 1 1 2.0 2.0 NaN 2 2 2 3.0 3.0 3.0 3 3 3 4.0 NaN 4.0 4 4
使用 “+” 运算符
# df 中的每个元素与100相加 print(df + 100) a b c d e 0 NaN 101.0 101.0 101 101 1 102.0 102.0 NaN 102 102 2 103.0 103.0 103.0 103 103 3 104.0 NaN 104.0 104 104 # 某一列(Series)与标量相加 df['a'] = df['a'] + 100 print(df) a b c d e 0 NaN 1.0 1.0 1 1 1 102.0 2.0 NaN 2 2 2 103.0 3.0 3.0 3 3 3 104.0 NaN 4.0 4 4
使用 “add()” 函数
df1 = df.add(100) print(df1) a b c d e 0 NaN 101.0 101.0 101 101 1 202.0 102.0 NaN 102 102 2 203.0 103.0 103.0 103 103 3 204.0 NaN 104.0 104 104 # 使用 fill_value 参数,给缺失值 NaN 添加默认值 df2 = df.add(100, fill_value=1000) print(df2) a b c d e 0 1100.0 101.0 101.0 101 101 1 202.0 102.0 1100.0 102 102 2 203.0 103.0 103.0 103 103 3 204.0 1100.0 104.0 104 104
- DataFrame 对象与 DataFrame 对象之间的运算
import pandas as pd x = pd.DataFrame({"a":[1,2,3], "b":[2,3,4], "c":[3,4,5]}) y = pd.DataFrame({"a":[1,2,3], "b":[2,3,4], "d":[3,4,5]}, index=[1,2,3]) print(x) print(y) a b c 0 1 2 3 1 2 3 4 2 3 4 5 a b d 1 1 2 3 2 2 3 4 3 3 4 5
使用 “+” 运算符
print(x+y) a b c d 0 NaN NaN NaN NaN 1 3.0 5.0 NaN NaN 2 5.0 7.0 NaN NaN 3 NaN NaN NaN NaN
使用 “sub()” 函数
z = x.sub(y) print(z) a b c d 0 NaN NaN NaN NaN 1 1.0 1.0 NaN NaN 2 1.0 1.0 NaN NaN 3 NaN NaN NaN NaN p = x.sub(y, fill_value=100) print(p) a b c d 0 -99.0 -98.0 -97.0 NaN 1 1.0 1.0 -96.0 97.0 2 1.0 1.0 -95.0 96.0 3 97.0 96.0 NaN 95.0
注:减法运算和加法运算一摸一样,只需要将 “+” 换为 “-”,将 “add()” 替换为 “sub()” 即可。
数据统计
import pandas as pd data = [[80, None,87, 90], [51, 98, 70], [None, 55, 49, 99], [30, 20, None, 90]] index = ['张三', '李四', '王五', '赵六'] columns = ['语文', '数学', '英语', '物理'] df = pd.DataFrame(data=data, index=index, columns=columns) print(df) 语文 数学 英语 物理 张三 80.0 NaN 87.0 90.0 李四 51.0 98.0 70.0 NaN 王五 NaN 55.0 49.0 99.0 赵六 30.0 20.0 NaN 90.0
- 筛选出 “数学成绩大于等于60并且英语成绩大于等于70” 的记录
print((df["数学"]>=60) & (df["英语"]>=70)) 张三 False 李四 True 王五 False 赵六 False dtype: bool print(df[(df["数学"]>=60) & (df["英语"]>=70)]) 语文 数学 英语 物理 李四 51.0 98.0 70.0 NaN
- 筛选出 “语文成绩小于60或者数学成绩大于80” 的记录
print((df['语文'] < 60) | (df['数学'] > 80)) 张三 False 李四 True 王五 False 赵六 True dtype: bool print(df[(df['语文'] < 60) | (df['数学'] > 80)]) 语文 数学 英语 物理 李四 51.0 98.0 70.0 NaN 赵六 30.0 20.0 NaN 90.0
- 筛选出 “语文成绩里面的非空记录” 的记录
print(df["语文"].notnull()) 张三 True 李四 True 王五 False 赵六 True Name: 语文, dtype: bool print(df[df["语文"].notnull()]) 语文 数学 英语 物理 张三 80.0 NaN 87.0 90.0 李四 51.0 98.0 70.0 NaN 赵六 30.0 20.0 NaN 90.0
- 通过
query()函数简化查询代码
print(df.query("语文>=60")) 语文 数学 英语 物理 张三 80.0 NaN 87.0 90.0 print(df.query("英语<60 & 数学<60")) 语文 数学 英语 物理 王五 NaN 55.0 49.0 99.0 print(df.query("英语.isnull()")) 语文 数学 英语 物理 赵六 30.0 20.0 NaN 90.0
- 通过
isin()函数查看 df 中是否包含某个值或某些值
使用 isin() 函数,不仅可以针对整个 df 操作,也可以针对 df 中的某一列(Series)操作
# 判断整个 df 中是否包含某个值或某些值 print(df.isin(["60", "70"])) 语文 数学 英语 物理 张三 False False False False 李四 False False True False 王五 False False False False 赵六 False False False False # 判断 df 中的某列是否包含某个值或某些值 print(df[df["语文"].isin(["60","80"])]) 语文 数学 英语 物理 张三 80.0 NaN 87.0 90.0 # 利用 df1 中的某一列,来对 df2 中的数据进行过滤 x = df1["name"].isin(df2["name"])
- 通过
between()函数判断是否在某个范围内
print(df[df["物理"].between(80,100)]) 语文 数学 英语 物理 张三 80.0 NaN 87.0 90.0 王五 NaN 55.0 49.0 99.0 赵六 30.0 20.0 NaN 90.0
过滤/筛选值
缺失值处理
排序
对 Pandas 中的 Series 对象和 DataFrame 对象进行排序,主要使用 sort_values() 和 sort_index() 方法。
将 obj 按指定行或列的值进行排序,语法如下:
obj.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
参数说明:
by: 指定对行或列的值排序,如果 axis=0,那么 by="列名";如果 axis=1,那么 by="行名"。 axis: 默认值为 0(即按照列排序);如果为 1,则按照行排序。 ascending: 默认为 True,表示是升序排序。如果 by=['列名1','列名2'],则该参数可以是[True, False],即第一字段升序,第二个字段降序。 inplace:默认为 False,表示是否用排序后的数据框替换现有的数据框。 kind: 排序方法 {'quicksort', 'mergesort', 'heapsort'}, 默认是 'quicksort',也就是快速排序。 na_position:NaN 排列的位置,是前还是后 {'first', 'last'},默认是 'last'。
Series 对象值的排序:
import numpy as np import pandas as pd obj = pd.Series(np.random.randn(5)) print(obj) 0 0.225178 1 -1.008378 2 0.781928 3 -1.314087 4 2.036863 dtype: float64
- 对 Series 对象的值进行排序,默认是按值的升序进行排序
print(obj.sort_values()) 0 -1.311615 3 -0.120783 2 -0.022735 1 0.486938 4 0.640428 dtype: float64
- 设置轴的方向(列的值排序),并设置为降序排序
print(obj.sort_values(axis=0, ascending=False)) 4 1.845918 1 -0.250179 2 -0.414060 3 -0.478050 0 -1.030672 dtype: float64
DataFrame 对象值的排序:
import numpy as np import pandas as pd obj = pd.DataFrame(np.random.randn(5, 5), columns=['A', 'B', 'C', 'D', 'E'], index=[0, 3, 2, 5, 1]) print(obj) A B C D E 0 1.627426 0.196840 0.072229 1.079132 -0.122745 3 0.540085 -0.940852 2.161920 -1.468265 0.800902 2 -0.559616 1.229442 0.229663 -0.876598 -1.383317 5 -0.784690 1.135936 0.710551 -0.390343 -0.333282 1 0.841698 -1.974697 0.141502 1.284522 -0.236239
- 按 B 列升序排序(列 B 表示列标签的值为 B)
print(obj.sort_values(by='B', axis=0)) A B C D E 0 2.191465 -1.161666 1.360355 1.409487 0.463010 5 0.116751 -0.205663 0.873430 0.442080 0.459543 3 -2.474828 0.142985 -0.118097 -0.559186 -1.403363 2 -0.319694 1.822675 -0.468255 0.676916 -0.894827 1 1.745205 2.022956 1.151206 -0.206566 0.103312
- 先按 B 列降序,再按 A 列升序排序
print(obj.sort_values(by='B', axis=0)) A B C D E 0 -0.875150 0.622953 -1.337311 0.207376 -1.312998 3 1.697354 0.544050 0.524342 1.359163 1.465065 1 -1.564854 -0.164513 -1.213751 -2.072715 -1.842101 5 0.116938 -0.326813 1.713289 -0.278996 0.389957 2 -1.405301 -0.736174 0.684996 -0.072519 -0.010160
- 按行 3 升序排列(行 3 表示行标签的值为 3)
print(obj.sort_values(by=3, axis=1)) D A C B E 0 -0.629771 -0.691081 0.681023 -1.549523 0.669319 3 -1.394622 -0.934466 -0.555846 -0.393307 0.328766 2 1.349323 -0.691531 0.890496 0.755160 0.246605 5 -0.020006 -1.419684 -0.495950 0.366071 -0.117062 1 -0.140247 -0.807186 -2.288513 -0.636607 -0.161714
- 按行 3 降序,行 0 升序排列
print(obj.sort_values(by=[3, 1], axis=1, ascending=[False, True])) D E A C B 0 -0.274879 0.953513 -0.294848 0.488537 -0.630700 3 2.514524 0.457202 0.102093 -0.329558 -0.583309 2 -0.172541 0.124459 -0.249955 -0.139157 -1.499261 5 0.239643 -1.015673 -0.591248 0.656918 0.403120 1 0.500217 0.674951 -1.512563 -0.036716 0.047276
obj.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, by=None)
参数说明:
by: 指定对行或列的值排序,如果 axis=0,那么 by="列名";如果 axis=1,那么 by="行名"。 axis: 默认值为 0(即按照列排序);如果为 1,则按照行排序。 ascending: 默认为 True,表示是升序排序。如果 by=['列名1','列名2'],则该参数可以是[True, False],即第一字段升序,第二个字段降序。 inplace:默认为 False,表示是否用排序后的数据框替换现有的数据框。 kind: 排序方法 {'quicksort', 'mergesort', 'heapsort'}, 默认是 'quicksort',也就是快速排序。 na_position:NaN 排列的位置,是前还是后 {'first', 'last'},默认是 'last'。
Series 对象索引的排序:
import numpy as np import pandas as pd obj = pd.Series(np.random.randn(5)) print(obj) 0 0.225178 1 -1.008378 2 0.781928 3 -1.314087 4 2.036863 dtype: float64
- 对 Series 对象的索引进行排序,默认是升序
print(obj.sort_index()) 0 1.088736 1 0.036936 2 1.257367 3 -0.317615 4 -0.815298 dtype: float64
- 对 Series 对象的索引进行降序排序
print(obj.sort_index(axis=0, ascending=False)) 4 -0.815298 3 -0.317615 2 1.257367 1 0.036936 0 1.088736 dtype: float64
DataFrame 对象索引的排序:
import numpy as np import pandas as pd obj = pd.DataFrame(np.random.randn(5, 5), columns=['A', 'B', 'C', 'D', 'E'], index=[0, 3, 2, 5, 1]) print(obj) A B C D E 0 1.627426 0.196840 0.072229 1.079132 -0.122745 3 0.540085 -0.940852 2.161920 -1.468265 0.800902 2 -0.559616 1.229442 0.229663 -0.876598 -1.383317 5 -0.784690 1.135936 0.710551 -0.390343 -0.333282 1 0.841698 -1.974697 0.141502 1.284522 -0.236239
- 按行标签升序排列(默认)
print(obj.sort_index()) A B C D E 0 -1.615722 -0.200705 -0.746031 0.649302 1.284177 1 -0.036073 -0.978462 -0.190356 -0.542268 -0.336146 2 1.308355 2.881134 0.160160 -0.201592 0.889227 3 0.351110 -1.513589 -1.043026 -1.289689 0.325446 5 -0.403999 -0.304316 -2.001672 0.376774 -1.242409
- 按列标签降序排列
print(obj.sort_index(axis=1, ascending=False)) E D C B A 0 0.394288 0.175654 0.032215 0.656627 -0.421032 3 0.970358 -0.569057 0.952854 -1.389620 -1.729118 2 -1.589661 -0.172699 0.261368 -0.758601 -0.817755 5 0.587174 0.830619 1.406376 0.610839 -1.017695 1 0.142812 -1.456431 0.962664 0.259454 1.189206
注:
1. obj 为 Series 或 DataFrame 对象。
2. 如果 obj 为 Series 对象,由于 Series 对象是一维结构,所以 sort_values() 方法的参数 axis 使用默认值 0 即可。
3. 如果 obj 为 DataFrame 对象,sort_values() 方法必须指定 by 参数,即必须指定哪几行或哪几列。
排名
rank() 是将 Series 或 DataFrame 的数据进行排序类型的一种方法,不过它并不像 sort()那样返回的是排序后的数据,而是返回当前数据的排名。
- Series 的排名
使用 rank() 函数计算序列中的每个元素在原来的 Series 对象中排第几位,若有相同的数,默认情况下取其排名的平均值。
import pandas as pd obj=pd.Series([7, -5, 7, 3, 0, -1, 3]) print(obj.rank()) 0 6.5 1 1.0 2 6.5 3 4.5 4 3.0 5 2.0 6 4.5 dtype: float64
上述 Series 对象中,索引为 1 的值最小(-5),所以其排名为 1.0;索引为 5 的值第二小(-1),所以其排名为 2.0;索引为 4 的值第三小(0),所以其排名为 3.0;索引为 3 和 6 的值相同且第四小(3),根据 为各组分配一个平均排名,这一规则,会取 4.0 和 5.0 的平均值作为其排名(即 4.0);同理得出,索引为 0 和 2 的值排名为 6.5。
上述计算的是默认情况下的排名方式,rank() 函数中有一个 method 参数,取值及说明如下:
| 序号 | 方法 | 描述 |
| 1 | average | 默认值,即在相等分组中,为各值分配平均排名 |
| 2 | min | 使用整个分组的最小排名 |
| 3 | max | 使用整个分组的最大排名 |
| 4 | first | 按值在原始数据中出现的顺序分配排名 |
| 5 | dense | 与 min 类似,但是排名每次只会增加 1,即并列的数据只占一个名次 |
设置 method 参数为 first 时,对于相同的数据,它会根据数据出现的顺序进行排序
import pandas as pd obj=pd.Series([7, -5, 7, 3, 0, -1, 3]) print(obj.rank(method='first')) 0 6.0 1 1.0 2 7.0 3 4.0 4 3.0 5 2.0 6 5.0 dtype: float64
同时,我们可以让 rank() 的排名顺序为逆序,这是只需设置 ascending = False 即可
import pandas as pd obj=pd.Series([7, -5, 7, 3, 0, -1, 3]) print(obj.rank(method='first', ascending=False)) 0 1.0 1 7.0 2 2.0 3 3.0 4 5.0 5 6.0 6 4.0 dtype: float64
- DataFrame 的排名
若对 DataFrame 对象进行排名,则可根据 axis 指定的轴进行排名,axis=0 按行排名,axis=1 按列排名。
import pandas as pd obj=pd.DataFrame({'x':[4,6,-1], 'y':[1,0,2], 'z':[5,7,-1]}) print(obj.rank(method='first', axis=0)) x y z 0 2.0 2.0 2.0 1 3.0 1.0 3.0 2 1.0 3.0 1.0
- Series 对象转字典
import pandas as pd s1=pd.Series([1, 2, 3], index=['A', 'B', 'C']) d1=s1.to_dict() print(d1) {'A': 1, 'B': 2, 'C': 3}
- DataFrame 对象转字典
import pandas as pd data = [[110, 105, 199], [105, 88, 115], [109, 120, 130]] index = [0, 1, 2] columns = ['语文', '数学', '英语'] df = pd.DataFrame(data=data, index=index, columns=columns) d = df.to_dict() print(d) {'语文': {0: 110, 1: 105, 2: 109}, '数学': {0: 105, 1: 88, 2: 120}, '英语': {0: 199, 1: 115, 2: 130}}
- Series 对象转列表
import pandas as pd s=pd.Series([1, 2, 3], index=['A', 'B', 'C']) l=s.to_list() print(l) [1, 2, 3]
- DataFrame 对象转列表
import pandas as pd data = [[110, 105, 199], [105, 88, 115], [109, 120, 130]] index = [0, 1, 2] columns = ['语文', '数学', '英语'] df = pd.DataFrame(data=data, index=index, columns=columns) l1=df['语文'].tolist() l2=df.values.tolist() print(l1) print(l2) [110, 105, 109] [[110, 105, 199], [105, 88, 115], [109, 120, 130]]
- Series 对象转 DataFrame 对象
# 合成 import pandas as pd s1=pd.Series([1, 2, 3]) s2=pd.Series([4, 5, 6]) df=pd.DataFrame({'A': s1, 'B': s2}) print(df) A B 0 1 4 1 2 5 2 3 6
# to_frame() import pandas as pd s1=pd.Series([1, 2, 3], name='A') df=s1.to_frame() print(df) A 0 1 1 2 2 3
- DataFrame 对象转 Series 对象
# 通过标签 import pandas as pd df=pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}) s1=df['B'] print(s1) 0 4 1 5 2 6 Name: B, dtype: int64
# 通过 loc 和 iloc import pandas as pd df=pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}) s1=df.loc[0,['A','B']] print(s1) s2=df.iloc[0:3,0] print(s2) A 1 B 4 Name: 0, dtype: int64 0 1 1 2 2 3 Name: A, dtype: int64
参考资料
原创文章,转载请注明出处:http://www.opcoder.cn/article/36/