对所有的关系型数据库而言,优化器无疑是其中最核心的部分,因为优化器负责解析 SQL,而我们又都是通过 SQL 来访问存储在关系型数据库中的数据的,所以优化器的好坏直接决定该关系型数据库的强弱。从另一个方面来说,正是因为优化器负责解析 SQL,所以要想做好 SQL 优化就必须了解优化器,而且最好能全面、深入的了解,这是做好 SQL 优化基础中的基础。
什么是 Oracle 里的优化器
优化器(Optimizer) 是 Oracle 数据库中内置的一个核心子系统,你也可以把它理解成是 Oracle 数据库中的一个核心模块或者一个核心功能组件。优化器的目的是按照一定的判断原则来得到它认为的目标 SQL 在当期情形下最高效的执行路径,也就是说,优化器的目的就是为了得到目标 SQL 的执行计划。
依据选择执行计划时所用的判断原则,Oralce 数据库里的优化器又分为 RBO 和 CBO 这两种类型。RBO 是 Rule-Based Optimizer 的缩写,直译过来就是 “基于规则的优化器”;相对应的,CBO 就是 Cost-Based Optimizer 的缩写,直译过来就是 “基于成本的优化器”。
在得到目标 SQL 的执行计划时,RBO 所用的判断原则为一组内置的规则,这些规则是硬编码在 Oracle 数据库的代码中的,RBO 会根据这些规则从目标 SQL 诸多可能的执行路径中选择一条来作为其执行计划;而 CBO 所用的判断原则为成本,CBO 会从目标 SQL 诸多可能的执行路径中 选择成本值最小的一条来作为其执行计划,各个执行计划的成本值是根据目标 SQL 语句所涉及的表、索引、列等相关的统计信息计算出来的。
Oracle 数据库里 SQL 语句的执行过程可以用下图来表示。
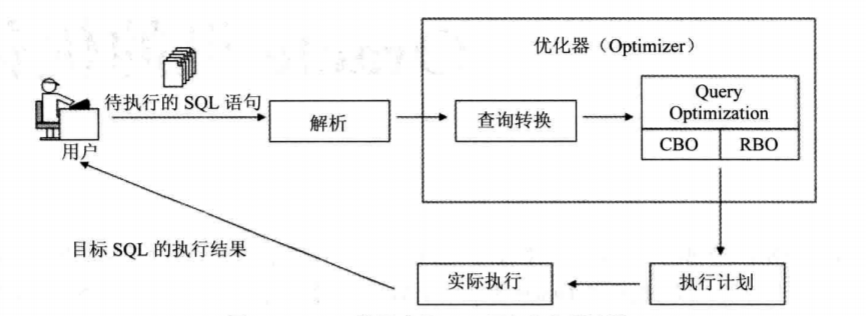
- 当用户提交待执行的目标 SQL 后,Oracle 首先会执行对目标 SQL 的解析过程,在这个过程中 Oracle 会先执行对目标 SQL 的语法、语义和权限的检查。如果目标 SQL 能通过上述检查,接下来 Oracle 就会去 Library Cache 中查找匹配的 Shared Cursor。如果找到了匹配的 Shared Cursor,Oracle 就会把存储于该 Shared Cursor 中的解析树和执行计划直接拿过来重用,这相当于跳过了后续的 “查询转换” 和 “查询优化” 两个步骤,直接进入到 “实际执行” 阶段。
- 如果找不到匹配的 Shared Cursor,就意味着此时没有被共享的解析树和执行计划,接下来整个执行过程就进入到 “查询转换” 这一步。在这一步里,Oracle 会根据一些规则来决定是否对目标 SQL 执行查询转换,在 Oracle 10g 及其以后的版本中,Oracle 会对某些类型的查询转换(比如子查询展开、复杂视图合并等)计算成本,即 Oracle 会分别计算经过查询转换后的等价改写 SQL 的成本和原始 SQL 的成本,只有当等价改写 SQL 的成本值小于未经过查询转换的原始 SQL 的成本值时,Oracle 才会对目标 SQL 执行这些查询转换。
- 执行完查询转换这一步后,原目标 SQL 可能已经被 Oracle 改写了,在执行下一步查询优化时,优化器所面对的 SQL 就已变成了等价改写形式,当然,如果 Oracle 发现并不能对原目标 SQL 做查询转换,那么即使执行完查询转换这一步,原目标 SQL 也不会发生任何改动,即此时执行下一步查询优化时优化器所面对的 SQL 就是原目标 SQL。
- 接来下,就正式进入了查询优化这个步骤。在这个步骤里根据不同的优化器类型,Oracle 会采用不同的判断原则,从执行完查询转换后得到的目标 SQL 的诸多可能的执行路径中选择一条来作为其执行计划,即查询优化的输入就是执行完查询转换后得到的等价改写 SQL,其输出就是该 SQL 的执行计划。
- 在得到目标 SQL 的执行计划后,接下来 Oracle 就会根据执行计划去实际执行该 SQL,并将执行返回结果给用户。
基于规则的优化器
基于规则的优化器(RBO)通过硬编码(将可变变量用一个固定值来代替的方法)在 Oracle 数据库代码中的一系列固定的规则,来决定目标 SQL 的执行计划。具体来说是这样: Oracle 会在代码里事先给各种类型的执行路径定一个等级,一共 15 个等级,从等级 1 到等级 15。并且 Oracle 会认为等级值低的执行路径的执行效率会比等级值高的执行效率要高,也就是说在 RBO 眼里,等级 1 所对应的执行路径的执行效率最高,等级 15 所对应的执行路径的执行效率最低。在决定目标 SQL 的执行计划时,如果可能的执行路径不止一条,则 RBO 就会从该 SQL 诸多可能的执行路径中选择一条等级值最低的执行路径来作为其执行计划。
- RBO Path 1: Single Row by Rowid
- RBO Path 2: Single Row by Cluster Join
- RBO Path 3: Single Row by Hash Cluster Key with Unique or Primary Key
- RBO Path 4: Single Row by Unique or Primary Key
- RBO Path 5: Clustered Join
- RBO Path 6: Hash Cluster Key
- RBO Path 7: Indexed Cluster Key
- RBO Path 8: Composite Index
- RBO Path 9: Single-Column Indexes
- RBO Path 10: Bounded Range Search on Indexed Columns
- RBO Path 11: Unbounded Range Search on Indexed Columns
- RBO Path 12: Sort Merge Join
- RBO Path 13: MAX or MIN of Indexed Column
- RBO Path 14: ORDER BY on Indexed Column
- RBO Path 15: Full Table Scan
基于成本的优化器
集的势
Cardinality 是 CBO 特有的概念,直译过来就是 “集的势”,它是指指定集合所包含的记录数,即指定结果集的行数。这个指定结果集是与目标 SQL 执行计划的某个具体执行步骤相对应的,也就是说 Cardinality 实际上表示对目标 SQL 的某个具体执行步骤的执行结果所包含记录数的估算。当然,如果是针对整个目标 SQL,那么此时的 Cardinality 就表示对该 SQL 最终执行结果所包含记录数的估算。
如果某个执行步骤所对应的 Cardinality 的值越大,那么它所对应的成本值往往也就越大,这个执行步骤所在执行路径的总成本值也就会越大。
可选择率
Selectivity 也是 CBO 特有的概念,它是指 施加谓词条件后返回结果集的记录数占未施加任何谓词条件的原始结果集的记录数的比率。
可选择率的取值范围在 0 ~ 1 之间,它的值越小,就表明可选择性越好,当可选择率为 1 时可选择性是最差的。
可选择率的值越大,就意味着返回结果集的 Cardinality 的值就越大,同时估算出来的成本值也就会越大。
可选择率针对每一种具体情况都会有不同的计算公式,其中最简单的情况是对目标列做等值查询时可选择率的计算。在目标列上没有直方图且没有 NULL 值的情况下,用目标列做等值查询的可选择率用如下公式计算:
Selectivity = 1 / NUM_DISTINCT // 这里的 NUM_DISTINCT 表示目标列的 distinct 值的数量
通过实例来看 CBO 会如何计算列 ENAME 的可选择率和该 SQL 返回结果集的 Cardinality。
- 先把列 ENAME 修改为 NOT NULL:
SQL> drop table emp_temp purge; SQL> create table emp_temp as select * from emp; 表已创建。 SQL> alter table emp_temp modify(ename not null); 表已更改。
- 然后在列 ENAME 上创建一个名为 IDX_EMP_TEMP_ENAME 的单键值 B 树索引:
SQL> create index idx_emp_temp_ename on emp_temp(ename); 索引已创建。
- 表 EMP_TEMP 的记录数现在是 14:
SQL> select count(*) from emp_temp;
COUNT(*)
----------
14
- 列 ENAME 的 distinct 值也是 14:
SQL> select count(distinct ename) from emp_temp;
COUNT(DISTINCTENAME)
--------------------
14
- 使用 DBMS_STATS 包来对表 EMP_TEMP 的所有列、索引收集统计信息,但不收集直方图信息:
SQL> exec dbms_stats.gather_table_stats(ownname => 'SCOTT', tabname => 'EMP_TEMP', estimate_percent => 100, method_opt => 'for all columns size 1', ca scade => TRUE); PL/SQL 过程已成功完成。
- 执行 SQL 语句,并查看执行计划:
SQL> set autotrace traceonly; SQL> select * from emp_temp where ename = 'SCOTT';
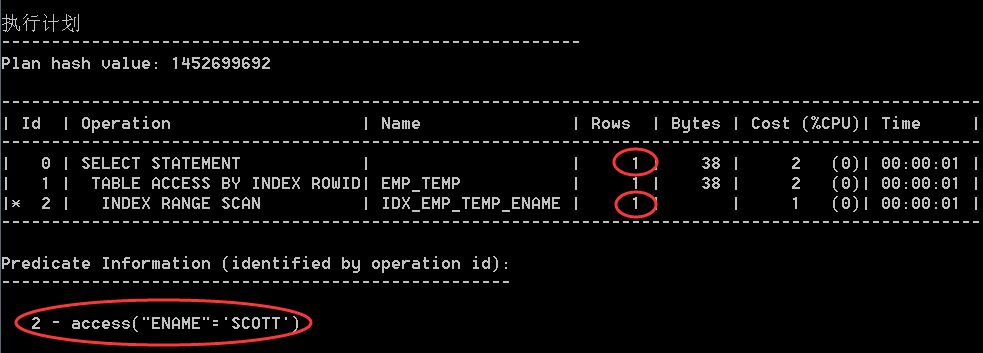
从 Oracle 10g 开始, Oracle 在解析目标 SQL 时就会默认使用 CBO。上述执行计划的显示内容中有列 Rows 和 列 Cost(%CPU),这说明 Oracle 在解析上述 SQL 时确实使用的是 CBO。这里列 ROWS 记录的就是上述执行计划中的每一个执行步骤所对应的 Cardinality 的值,列 Cost(%CPU) 记录的就是上述执行计划中的每一个执行步骤所对应的成本值。
从上图的内容可以看出,上述 SQL 语句的执行计划走的是对索引 IDX_EMP_TEMP_ENAME 的索引范围扫描,且 Id=2 的执行步骤所对应的列 Rows 的值为 1,这说明 CBO 评估出来以驱动查询条件 access(ENAME"='SCOTT') 去访问索引 IDX_EMP_TEMP_ENAME 是返回结果集的 Cardinality 的值是 1;另外 Id=0 的执行步骤所对应的列 Rows 的值也是 1,这说明 CBO 评估出来的上述 SQL 语句的最终执行结果所对应的 Cardinality 的值也是 1。
那么,这两个值 CBO 是如何计算出来的呢?
在目标列没有直方图且没有 NULL 值的情况下,用目标列做等值查询的可选择率的计算公式为 Selectivity = 1 / NUM_DISTINCT 。现在列 ENAME 没有 NULL 值也没有直方图统计信息,上述 SQL 语句的 where 条件是针对列 ENAME 的等值查询,而列 ENAME 的 distinct 值的数量是 14,所以此时针对列 ENAME 做等值查询的可选择率就是 1/14。另外,由于 Cardinality 的计算公式为 Computed Cardinality = Original Cardinality * Selectivity,而表 EMP_TEMP 的记录数为 14,即此时 Original Cardinality 的值为 14,那么根据 Cardinality 的计算公式,上述针对列 ENAME 做等值查询的执行步骤所对应的 Cardinality 的值就是 14 * 1 / 14 = 1,所以这就是 CBO 评估出来以驱动查询条件 access(ENAME"='SCOTT') 去访问索引 IDX_EMP_TEMP_ENAME 时返回结果集的 Cardinality 的值为 1 的原因。又因为 where 条件 ename = 'SCOTT' 是上述 SQL 语句的唯一查询条件,所以上述 SQL 语句的最终执行结果所对应的 Cardinality 的值也会是 1。
可传递性
Transitivity 也是 CBO 特有的概念,其含义是指 CBO 可能会对原目标 SQL 做简单的等价改写,即在原目标 SQL 中加上根据该 SQL 现有的谓词条件推算出来的新的谓词条件,这样做的目的是提供更多的执行路径给 CBO 做选择,进而增加得到更高效执行计划的可能性。这里需要注意的是,利用可传递性对目标 SQL 做简单的等价改写仅仅适用于 CBO,RBO 不会做这样的事情。
在 Oracle 里,可传递性又分为如下这三种情形:
1) 简单谓词传递
比如原目标 SQL 中的谓词条件是 t1.c1 = t2.c1 and t1.c1 = 10,则 CBO 可能会在这个谓词条件中额外地加上 t2.c1 = 10,即 CBO 可能会将原谓词条件 t1.c1 = t2.c1 and t1.c1 = 10 修改为 t1.c1 = t2.c1 and t1.c1 = 10 and t2.c1 = 10。改写后的谓词条件显然是等价的,因为如果 t1.c1 = t2.c1 and t1.c1 = 10,那么我们就可以推算出 t2.c1 = 10。
2) 连接谓词传递
比如原目标 SQL 中的谓词条件是 t1.c1 = t2.c1 and t2.c1 = t3.c1,则 CBO 可能会在这个谓词条件中额外地加上 t1.c1 = t3.c1,即 CBO 可能会将原谓词条件 t1.c1 = t2.c1 and t2.c1 = t3.c1 修改为 t1.c1 = t2.c1 and t2.c1 = t3.c1 and t1.c1 = t3.c1,同理,这里改写前后的谓词条件也是等价的。
3) 外连接谓词传递
比如原目标 SQL 中的谓词条件是 t1.c1 = t2.c1(+) and t1.c1 = 10`,则 CBO 可能会在这个谓词条件中额外加上 t2.c1(+) = 10,即 CBO 可能会将原谓词条件 t1.c1 = t2.c1(+) and t1.c1 = 10 修改为 t1.c1 = t2.c1(+) and t1.c1 = 10 and t2.c1(+) = 10。
Oracle 利用可传递性对目标 SQL 做简单的等价改写的目的是为了提供更多的执行路径给 CBO 做选择,进而增加得到更高效执行计划的可能性。我们来看一个 CBO 利用可传递性对目标 SQL 做简单等价改写的实例。
- 创建两个测试表 T1 和 T2:
SQL> create table t1(c1 number, c2 varchar2(10)); 表已创建。 SQL> create table t2(c1 number, c2 varchar2(10)); 表已创建。
- 在表 T2 的列 C1 上创建索引:
SQL> create index idx_t2 on t2(c1); 索引已创建。
- 思考如下 SQL 语句:
SQL> select t1.c1, t2.c2 from t1, t2 where t1.c1 = t2.c1 and t1.c1 = 10;
上述 SQL 语句的 where 条件是 t1.c1 = t2.c1 and t1.c1 = 10,并没有针对表 T1 的列 C1 的简单谓词条件,所以按道理讲应该是不能走刚才在表 T2 的列 C1 上建立的索引 IDX_T2,但实际情况并非如此:
SQL> set autotrace traceonly; SQL> select t1.c1, t2.c2 from t1, t2 where t1.c1 = t2.c1 and t1.c1 = 10; 未选定行
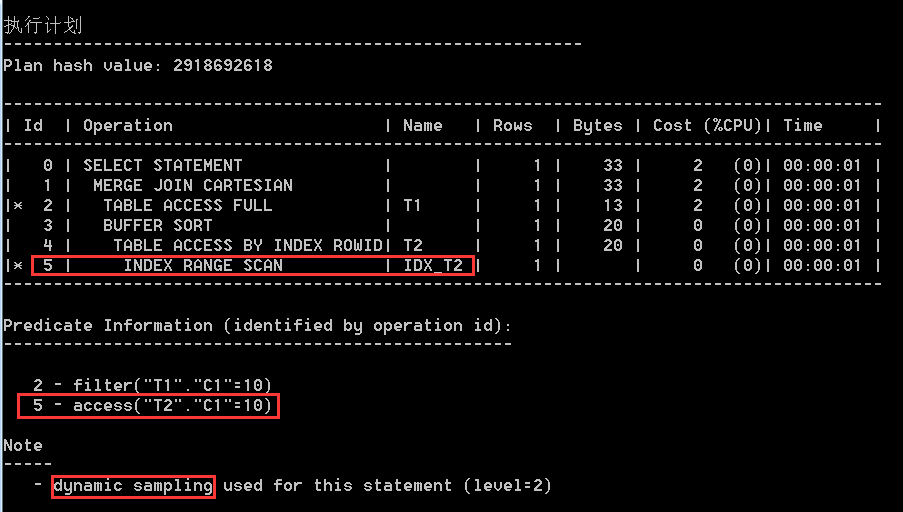
上面显示的内容中 Id=5 的执行步骤为 INDEX RANGE SCAN|IDX_T2,这说明 Oracle 现在还是走了对索引 IDX_T2 的索引范围扫描。下面来分析为什么 Oracle 能够这样做?
上述中,Id=5 的执行步骤所对应的驱动查询条件为 access("T2"."C1"=10),这说明 Oracle 在访问索引 IDX_T2 时所用的驱动查询条件是 t2.c1=10,但这个查询条件 t2.c1=10 在上述原始 SQL 文本中并不存在,这就说明 CBO 此时确实利用可传递性对上述原始 SQL 做了简单的等价改写,即 CBO 此时已经将原始 SQL 改写成了如下的等价形式:
SQL> select t1.c1, t2.c2 from t1, t2 where t1.c1 = t2.c1 and t1.c1 = 10 and t2.c1 = 10;
正是因为上述额外多出来的谓词条件 t2.c1 = 10,CBO 在解析上述原始 SQL 时就多出了走索引 IDX_T2 和对应的执行路径这种选择,进而就增加了得到更高效执行计划的可能性。
CBO 的局限性
- CBO 会默认认为目标 SQL 语句 where 条件中出现的各个列之间是独立的,没有关联关系
CBO 会默认认为目标 SQL 语句 where 条件中出现的各个列之间是独立的,没有关联关系,并且 CBO 会依据这个前提来计算 组合Selectivity、Cardinality,进而来估算成本并选择执行计划。但这个前提条件并不总是正确的,在实际的应用中,目标 SQL 的各列之间有关联关系的情况实际上并不罕见。在这种各列之间有关联关系的情况下,如果还用之前的计算方法来计算目标 SQL 语句整个 where 条件的组合可选择率,并用它来估算返回结果集的 Cardinality 的话,那么估算结果可能就会和实际结果有较大的偏差,导致 CBO 选错执行计划。
- CBO 会假设所有的目标 SQL 都是单独执行的,并且互不干扰
CBO 会假设所有的目标 SQL 都是单独执行的,并且互不干扰,但实际情况却完全不是这样。我们执行目标 SQL 时所需要访问的索引叶子快、数据块等可能由于之前执行的 SQL 而已经被缓存在 Buffer Cache 中,所以这次执行时也许不需要耗费物理 I/O 去相关的存储上读取要访问的索引叶子快、数据块等,而只需要去 Buffer Cache 中读取相关的缓存块就可以了。所以,如果此时 CBO 还是按照目标 SQL 是单独执行,而不考虑缓存的方式去计算相关成本的话,就可能会高估走相关索引的成本,进而可能会导致选错执行计划。
- CBO 对直方图统计信息有诸多限制
1) 在 Oracle 12c 之前,Frequency 类型的直方图所对应的 Bucket 的数量不能超过 254,这样如果目标列的 distinct 值的数量超过 254,Oracle 就会使用 Height Balanced 类型的直方图。对于 Height Balanced 类型的直方图而言,因为 Oracle 不会记录所有的 nonpopular value 的值,所以在此情况下 CBO 选错执行计划的概率会比对应的直方图统计信息是 Frequency 类型的情形要高。
2) 在 Oracle 数据库里,如果针对文本型的字段收集直方图统计信息,则 Oracle 只会将该文本型字段的文本值的头 32 字节给取出来并将其转换成一个浮点数,然后将该浮点数作为上述文本型字字段的直方图统计信息存储在数据字典里。这种处理机制的先天缺陷就在于,对于那些超过 32 字节的文本型字段,只要对应记录的文本值的头 32 字节相同,Oracle 在收集直方图统计信息的时候就会认为这些记录该字段的文本值是相同的,即使实际上它们并不相同。这种先天性的缺陷会直接影响 CBO 对相关文本型字段的可选择率及返回结果集的 Cardinality 的估算,进而就可能导致 CBO 选错执行计划。
- CBO 在解析多表关联的目标 SQL 时,可能会漏选正确的执行计划
假设多表关联的目标 SQL 所包含表的数量为 n,则该 SQL 各表之间可能的连接顺序的总数就是 n!(n 的阶乘)。这意味着包含 5 个表的目标 SQL 各表之间可能的连接顺序总数为 120,包含 10 个表的目标 SQL 各表之间可能的连接顺序总数为 3628800。
SQL> select 5*4*3*2*1 from dual;
5*4*3*2*1
----------
120
SQL> select 10*9*8*7*6*5*4*3*2*1 from dual;
10*9*8*7*6*5*4*3*2*1
--------------------
3628800
在 Oracle 11gR2 中,CBO 在解析这种多表关联的目标 SQL 时,所考虑的各个表的连接顺序的总和受隐含参数 _OPTIMIZER_MAX_PERMUTATIONS 的限制。这意味着不管目标 SQL 在理论上有多少种可能的连接顺序,CBO 最多只考虑其中根据 _OPTIMIZER_MAX_PERMUTATIONS 计算出来的有限种可能性。这同时也意味着只要该目标 SQL 正确的执行计划并不在上述有限种可能之中,则 CBO 一定会漏选正确的执行计划。
CBO 和 RBO 的优劣
CBO 优于 RBO 是因为 RBO是一种呆板、过时的优化器,它只认规则,对数据不敏感。毕竟规则是死的,数据是变化的,这样生成的执行计划往往是不可靠且不是最优的。
- 创建测试表 TEST
SQL> drop table test purge; SQL> create table test as select object_id, object_name from all_objects where 1 = 2; Table created.
- 创建 B 树索引
SQL> create index idx_test on test(object_id); Index created.
- 写入数据,object_id=100 的记录只有一条,其余全为 object_id=1
SQL> insert into /*+ append */ test select 1 id, object_name from all_objects;
73004 rows created.
SQL> update test set object_id = 100 where rownum = 1;
1 row updated.
SQL> commit;
Commit complete.
SQL> select object_id, count(object_id) from test group by object_id;
OBJECT_ID COUNT(OBJECT_ID)
---------- ----------------
1 73003
100 1
- RBO 下 SQL 执行计划
SQL> set autotrace traceonly;
SQL> select /*+ rule */ * from test where object_id = 100;
执行计划
----------------------------------------------------------
Plan hash value: 2473784974
------------------------------------------------
| Id | Operation | Name |
------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST |
|* 2 | INDEX RANGE SCAN | IDX_TEST |
------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=100)
Note
-----
- rule based optimizer used (consider using cbo)
SQL> select /*+ rule */ * from test where object_id = 1;
73003 rows selected.
执行计划
----------------------------------------------------------
Plan hash value: 2473784974
------------------------------------------------
| Id | Operation | Name |
------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST |
|* 2 | INDEX RANGE SCAN | IDX_TEST |
------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=1)
Note
-----
- rule based optimizer used (consider using cbo)
从执行计划可以看出,RBO 的执行计划让人有点失望,对于 Id=1,几乎所有的数据全部符合谓词条件,走索引只能增加额外的开销(因为 Oracle 首先要访问索引数据块,在索引上找到了对应的键值,然后按照键值上的 ROWID 再去访问表中相应数据),既然我们几乎要访问所有表中的数据,那么全表扫描自然是最优的选择,而 RBO 显然选择了错误的执行计划。
- CBO 下 SQL 执行计划
SQL> set autotrace traceonly;
SQL> select * from test where object_id = 100;
执行计划
----------------------------------------------------------
Plan hash value: 2473784974
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 30 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST | 1 | 30 | 1 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TEST | 1 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=100)
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> select * from test where object_id = 1;
已选择73003行。
执行计划
----------------------------------------------------------
Plan hash value: 1357081020
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 85552 | 2506K| 103 (1)| 00:00:02 |
|* 1 | TABLE ACCESS FULL| TEST | 85552 | 2506K| 103 (1)| 00:00:02 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_ID"=1)
Note
-----
- dynamic sampling used for this statement (level=2)
CBO 下 SQL 的执行计划,显然它对数据敏感,执行计划及时的根据数据量做了调整,当查询条件为 1 时,它走全表扫描;当查询条件为 100 时,它走索引范围扫描。
优化器的基础知识
接来下,介绍一些优化器的基础知识,这些基础知识中的绝大部分与优化器的类型是没有关系的,也就说它们中的绝大部分不仅适用于CBO,同样也适用于 RBO。
优化器的模式
优化器的模式用于决定在 Oracle 解析目标 SQL 时所用优化器的类型,以及决定当使用 CBO 时计算成本值的侧重点。这里的 “侧重点” 是指当使用 CBO 来计算目标 SQL 各条执行路径的成本值时,计算成本值的方法随着优化器模式的不同而不同。
在 Oracle 数据库中,优化器的模式是由参数 OPTIMIZER_MODE 的值来决定的,OPTIMIZER_MODE 的各个可能的值的含义如下所示。
- RULE
RULE 表示 Oracle 将使用 RBO 来解析目标 SQL,此时目标 SQL 中所涉及的各个对象的统计信息对于 RBO 来说将没有任何作用。
- CHOOSE
CHOOSE 是 Oracle 9i 中 OPTIMIZER_MODE 的默认值,它表示 Oracle 在解析目标 SQL 时到底是使用 RBO 还是使用 CBO 取决于该 SQL 中所涉及的表对象是否有统计信息。具体来说就是: 只要该 SQL 中所涉及的表对象中有一个表有统计信息,那么 Oracle 在解析该 SQL 时就会使用 CBO;如果该 SQL 中所涉及的表对象均没有统计信息,那么此时 Oracle 就会使用 RBO。
- FIRST_ROWS_n(n = 1, 10, 100, 1000)
这里的 FIRST_ROWS_n(n = 1, 10, 100, 1000) 可以是 FIRST_ROWS_1、FIRST_ROWS_10、FIRST_ROWS_100 和 FIRST_ROWS_1000 中的任意一个值, 其含义是指当 OPTIMIZER_MODE 的值为 FIRST_ROWS_n(n = 1, 10, 100, 1000) 时,Oracle 会使用 CBO 来解析目标 SQL,且此时 CBO 在计算该 SQL 的各条执行路径的成本值时的侧重点在于以最快的响应速度返回头 n(n = 1, 10, 100, 1000) 条记录。
- FIRST_ROWS
FIRST_ROWS 是一个在 Oracle 9i 中就已经过时的参数,它表示 Oracle 在解析目标 SQL 时会联合使用 CBO 和 RBO。
- ALL_ROWS
ALL_ROWS 是 Oracle 10g 以及后续 Oracle 数据库版本中 OPTIMIER_MODE 的默认值,它表示 Oracle 会使用 CBO 来解析目标 SQL,且此时 CBO 在计算该 SQL 的各条执行路径的成本值时的侧重点在于最佳的吞吐量(即最小的系统 I/O 和 CPU 资源的消耗量)。
实际上,成本的计算方法随着优化器模式的不同而不同,主要体现在 ALL_ROWS 和 FIRST_ROWS_n(n = 1, 10, 100, 1000) 对成本值计算方法的影响上。当优化器模式为 ALL_ROWS 时,CBO 计算成本的侧重点在于最佳的吞吐量;当优化器模式为 FIRST_ROWS_n(n = 1, 10, 100, 1000) 时,CBO 计算成本的侧重点会变为以最快的响应速度返回头 n(n = 1, 10, 100, 1000) 条记录。这意味着同样的执行步骤,在优化器模式为 ALL_ROWS 时和 FIRST_ROWS_n(n = 1, 10, 100, 1000) 时 CBO 分别计算出来的成本值会存在巨大的差异,这也就意味着 优化器的模式对 CBO 计算成本有着决定性的影响。
结果集
结果集(Row Source) 是指 包含指定执行结果的集合。对于优化器而言(无论是 RBO 还是 CBO),结果集和目标 SQL 执行计划的执行步骤相对应,一个执行步骤所产生的执行结果就是该执行步骤所对应的输出结果集。
对于 RBO 而言,我们在执行计划中看不到对相关执行步骤所对应的结果集的描述,虽然结果集的概念对于 RBO 来说同样适用。
SQL> set autotrace traceonly;
SQL> select /*+ rule */ * from emp where empno = 7709;
执行计划
----------------------------------------------------------
Plan hash value: 2949544139
----------------------------------------------
| Id | Operation | Name |
----------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP |
|* 2 | INDEX UNIQUE SCAN | PK_EMP |
----------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=7709)
Note
-----
- rule based optimizer used (consider using cbo)
对于 CBO 而言,对应的执行计划中的列 Rows 反映的就是 CBO 对于相关执行步骤所对应输出结果集的记录数 Cardinality 的估算值。
SQL> set autotrace traceonly;
SQL> select * from emp where empno = 7709;
执行计划
----------------------------------------------------------
Plan hash value: 2949544139
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=7709)
对于上述使用 CBO 的执行计划而言,我们将 Id=1、2 的执行步骤所对应的输出结果集分别记为输出结果集 1 和输出结果集 2,这里 Oracle 会先执行 Id=2 的执行步骤。上述 Id=2 的执行步骤所对应的列 Rows 的值为 1,这说明 CBO 对输出结果集 2 的 Cardinality 的估算值为 1。同时,输出结果集 2 又会作为 Id=1 的执行步骤的输入结果集,上述 Id=1 的执行步骤所对应的列 Rows 的值也为 1,这说明 CBO 对输出结果集 1 的 Cardinality 的估算值也为 1。同时我们可以看到 Id=0 的执行步骤为 SELECT STATEMENT,这说明输出结果集 1 就是上述整个目标 SQL 的最终执行结果。
访问数据的方法
对于优化器而言,它在解析目标 SQL、得到其执行计划时至关重要的一点是决定访问数据的方法,即 优化器要决定采用什么样的方式和方法去访问目标 SQL 所需要访问的存储在 Oracle 数据库中的数据。
目标 SQL 所需要访问的数据一般存储在表里,而 Oracle 访问表中数据的方法有两种: 一种是直接访问表;另一种是先访问索引,再回表(如果目标 SQL 所要访问的数据只通过访问相关的索引就可以得到,那么此时就不需要再回表了)。
| 序号 | 分类 | 子分类 | 描述 |
| 1 | 访问表的方法 | 全表扫描 | TABLE ACCESS FULL |
| 2 | ROWID 扫描 | TABLE ACCESS BY USER|INDEX ROWID | |
| 3 | 访问索引的方法 | 索引唯一扫描 | INDEX UNIQUE SCAN |
| 4 | 索引范围扫描 | INDEX RANGE SCAN | |
| 5 | 索引全扫描 | INDEX FULL SCAN | |
| 6 | INDEX FULL SCAN (MIN/MAX) | ||
| 7 | 索引快速全扫描 | INDEX FAST FULL SCAN | |
| 8 | 索引跳跃扫描 | INDEX SKIP SCAN |
全表扫描
全表扫描是指 Oracle 在访问目标表里的数据时,会 从该表所占用的第一个区的第一个块开始扫描,一直扫描到该表的高水位线,这段范围内所有的数据块 Oracle 都必须读到。
需要注意的是,随着目标表数据量的递增,它的高水位线会一直不断往上涨,所以全表扫描该表时所需要读取的数据块的数量也会不断增加,这意味着全表扫描该表时所需要耗费的 I/O 资源会随之不断增加,当然完成对该表的全表扫描操作所需要耗费的时间也会随之增加。
ROWID 扫描
ROWID 扫描是指 Oracle 在访问目标表里的数据时,直接通过数据所在的 ROWID 去定位并访问这些数据,ROWID 表示的是 Oracle 中的数据行记录所在的物理存储地址,也就是说 ROWID 实际上和 Oracle 中数据块里的行记录是一一对应的。
我们可以通过 ROWID 伪列和 DBMS_ROWID 包,来查看 ROWID 的具体信息。
SQL> select deptno, dname, loc, rowid, dbms_rowid.rowid_relative_fno(rowid) || '_' || dbms_rowid.rowid_block_number(rowid) || '_' || dbms_rowid.rowid_row_number(rowid) location from dept;
DEPTNO DNAME LOC ROWID LOCATION
---------- -------------- ------------- ------------------ --------------------------
10 ACCOUNTING NEW YORK AAASZFAAEAAAACHAAA 4_135_0
20 RESEARCH DALLAS AAASZFAAEAAAACHAAB 4_135_1
30 SALES CHICAGO AAASZFAAEAAAACHAAC 4_135_2
40 OPERATIONS BOSTON AAASZFAAEAAAACHAAD 4_135_3
从上述显示的内容我们可以看出,DEPTNO 为 10 的行记录所对应的 ROWID 伪列的值为 AAASZFAAEAAAACHAAA,使用 DBMS_ROWID 包对该伪列翻译后的值为 4_135_0,这表示 DEPTNO 为 10 的行记录实际的物理存储地址位于 4 号文件的第 135 个数据块的第 0 行记录(数据块里数据行记录的记录号从 0 开始算起)。
- TABLE ACCESS BY USER ROWID
通过这种方式扫描的含义是: 根据用户在 SQL 语句中输入的 ROWID 的值直接去访问对应的数据行记录。
SQL> select rowid, d.* from dept d; ROWID DEPTNO DNAME LOC ------------------ ---------- -------------- ------------- AAASZFAAEAAAACHAAA 10 ACCOUNTING NEW YORK AAASZFAAEAAAACHAAB 20 RESEARCH DALLAS AAASZFAAEAAAACHAAC 30 SALES CHICAGO AAASZFAAEAAAACHAAD 40 OPERATIONS BOSTON SQL> set autotrace traceonly; SQL> select * from dept where rowid = 'AAASZFAAEAAAACHAAA'; 执行计划 ---------------------------------------------------------- Plan hash value: 3453257278 ----------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 20 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY USER ROWID| DEPT | 1 | 20 | 1 (0)| 00:00:01 | -----------------------------------------------------------------------------------
- TABLE ACCESS BY INDEX ROWID
通过这种方式扫描的含义是: 先去访问相关表的索引,然后根据访问索引后得到的 ROWID 再回表去访问对应的数据行记录。
SQL> set autotrace traceonly;
SQL> select * from dept where deptno = 10;
执行计划
----------------------------------------------------------
Plan hash value: 2852011669
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 20 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 20 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPTNO"=10)
索引唯一性扫描
索引唯一性扫描(INDEX UNIQUE SCAN)是针对唯一性索引的扫描,它仅仅适用于 where 条件里是等值查询的目标 SQL。因为扫描的对象是唯一性索引,所以唯一性扫描的结果 至多只会返回一条记录。
SQL> set autotrace traceonly;
SQL> select * from emp where empno = 7900;
执行计划
----------------------------------------------------------
Plan hash value: 2949544139
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=7900)
索引范围扫描
索引范围扫描(INDEX RANGE SCAN)适用于所有类型的 B 树索引,当扫描的对象是唯一性索引时,此时目标 SQL 的 where 条件一定是范围查询(谓词条件为 BETWEEN、<、> 等);当扫描的对象是非唯一性索引时,对目标 SQL 的 where 条件没有限制(可以是等值查询,也可以是范围查询)。索引范围扫描的结果 可能会返回多条记录,其实这就是索引范围扫描中 “范围” 二字的本质含义。
下面通过实例来验证上述结论。
- 创建一个测试表 EMP_TEST
SQL> drop table emp_test purge; SQL> create table emp_test as select * from emp; Table created.
- 在表 EMP_TEST 上创建一个唯一性索引和非唯一性索引
SQL> create unique index idx_emp_test_empno on emp_test(empno); Index created. SQL> create index idx_emp_test_deptno on emp_test(deptno); Index created.
- 收集表和索引的统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SCOTT',
tabname => 'EMP_TEST',
estimate_percent => 100,
method_opt => 'for all columns size 1',
cascade => TRUE);
end;
/
PL/SQL procedure successfully completed.
- 查看扫描对象是唯一性索引时的执行计划
SQL> set autotrace traceonly;
SQL> select * from emp_test where empno between 7709 and 7902;
7 rows selected.
执行计划
----------------------------------------------------------
Plan hash value: 1314747368
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 7 | 266 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP_TEST | 7 | 266 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_EMP_TEST_EMPNO | 7 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO">=7709 AND "EMPNO"<=7902)
- 查看扫描对象是非唯一性索引时的执行计划
SQL> select * from emp_test where deptno = 10;
执行计划
----------------------------------------------------------
Plan hash value: 4283119704
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 190 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP_TEST | 5 | 190 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_EMP_TEST_DEPTNO | 5 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPTNO"=10)
索引全扫描
索引全扫描(INDEX FULL SCAN)适用于所有类型的 B 树索引。所谓的 “索引全扫描”,就是指要 扫描目标索引所有叶子块的所有索引行。
在默认情况下,索引全扫描要从左至右依次顺序扫描目标索引所有叶子块的所有索引行,而索引是有序的,所以 索引全扫描的执行结果也是有序的,并且是按照该索引的索引键值来排序,这也意味着走索引全扫描能够达到排序的效果,又同时避免了对该索引的索引键值列的真正排序操作。
默认情况下,索引全扫描的扫描结果的有序性就决定了索引全扫描是不能够并行执行的,并且通常情况下索引全扫描使用的是 单块读,有序读取索引块。
对于索引全扫描,会话会产生 db file sequential reads 事件。
- INDEX FULL SCAN
SQL> set autotrace on;
SQL> select empno from emp;
EMPNO
----------
7369
7499
7521
7566
7654
7698
7782
7788
7839
7844
7876
7900
7902
7934
14 rows selected.
执行计划
----------------------------------------------------------
Plan hash value: 179099197
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 56 | 1 (0)| 00:00:01 |
| 1 | INDEX FULL SCAN | PK_EMP | 14 | 56 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------
从上述内容可以看出,该 SQL 的执行计划确实走的是对主键索引 PK_EMP 的索引全扫描,而且执行结果已经按照索引列 EMPNO 排好序了。
- INDEX FULL SCAN (MIN/MAX)
SQL> drop table t purge; SQL> create table t as select * from dba_objects; SQL> update t set object_id = rownum; SQL> commit; SQL> create index idx_t on t(object_id); SQL> set autotrace traceonly explain; SQL> select max(object_id) from t; 执行计划 ---------------------------------------------------------- Plan hash value: 3689784082 ------------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | 13 | 2 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 13 | | | | 2 | INDEX FULL SCAN (MIN/MAX)| IDX_T | 1 | 13 | 2 (0)| 00:00:01 | ------------------------------------------------------------------------------------ Note ----- - dynamic sampling used for this statement (level=2)
索引快速全扫描
索引快速全扫描(INDEX FAST FULL SCAN)和索引全扫描极为类似,它也适用于所有类型的 B 树索引。和索引全扫描一样,索引快速全扫描也需要 扫描目标索引所有叶子块的所有索引行。
对于索引快速全扫描,会话会产生 db file scattered reads 事件。
索引快速全扫描与索引全扫描相比有如下三点区别:
- 索引快速全扫描只适用于 CBO
- 索引快速全扫描可以使用 多块读,也可以并行执行
- 索引快速全扫描的执行结果不一定是有序的。这是因为索引快速全扫描时 Oracle 是根据索引行在磁盘上的物理存储顺序来扫描,而不是根据索引行的逻辑顺序来扫描的,所以扫描结果才不一定有序。
SQL> drop table t purge; SQL> create table t as select * from dba_objects; SQL> update t set object_id = rownum; SQL> commit; SQL> alter table t modify(object_id not null); SQL> set autotrace traceonly explain; SQL> select object_id from t; 执行计划 ---------------------------------------------------------- Plan hash value: 2497555198 ------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 79929 | 1014K| 57 (0)| 00:00:01 | | 1 | INDEX FAST FULL SCAN| IDX_T | 79929 | 1014K| 57 (0)| 00:00:01 | ------------------------------------------------------------------------------ Note ----- - dynamic sampling used for this statement (level=2) SQL> select count(*) from t; 执行计划 ---------------------------------------------------------- Plan hash value: 2371838348 ----------------------------------------------------------------------- | Id | Operation | Name | Rows | Cost (%CPU)| Time | ----------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 57 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | | | | 2 | INDEX FAST FULL SCAN| IDX_T | 79929 | 57 (0)| 00:00:01 | ----------------------------------------------------------------------- Note ----- - dynamic sampling used for this statement (level=2)
索引跳跃扫描
索引跳跃扫描(INDEX SKIP SCAN)适用于所有类型的复合 B 树索引,它使那些在 where 条件中没有对目标索引的前导列指定查询条件但同时又对该索引的非前导列指定了查询条件的目标 SQL 依然可以用上索引,这就像是在扫描该索引时跳过了它的前导列,直接从该索引的非前导列开始扫描一样。
为什么在 where 条件中没有对目标索引的前导列指定查询条件但 Oracle 依然可以用上该索引呢?这是因为 Oracle 帮你对该索引的前导列的所有 distinct 值做了遍历。
- 创建测试表 EMPLOYEE
SQL> drop table employee purge; SQL> create table employee(gender varchar2(1), employee_id number); Table created.
- 将该表的列 EMPLOYEE_ID 的属性设为 NOT NULL
SQL> alter table employee modify(employee_id not null); Table altered.
- 创建复合 B 树索引,列 GENDER 为索引前导列,列 EMPLOYEE_ID 为索引第二列
SQL> create index idx_employee on employee(gender, employee_id); Index created.
- 写入记录,其中 5000 条记录的列 GENDER 的值为 'F',另外 5000 条记录的列 GENDER 的值为 'M'
SQL> begin
2 for i in 1 .. 5000 loop
3 insert into employee values('F', i);
4 end loop;
5 commit;
6 end;
7 /
PL/SQL procedure successfully completed.
SQL> begin
2 for i in 5001 .. 10000 loop
3 insert into employee values('M', i);
4 end loop;
5 commit;
6 end;
7 /
PL/SQL procedure successfully completed.
- 收集表和索引的统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SCOTT',
tabname => 'EMPLOYEE',
estimate_percent => 100,
method_opt => 'for all columns size 1',
cascade => TRUE);
end;
/
PL/SQL procedure successfully completed.
- 指定查询条件为非索引前导列,并查看其执行计划
SQL> set autotrace traceonly;
SQL> select * from employee where employee_id = 100;
执行计划
----------------------------------------------------------
Plan hash value: 461756150
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 6 | 3 (0)| 00:00:01 |
|* 1 | INDEX SKIP SCAN | IDX_EMPLOYEE | 1 | 6 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("EMPLOYEE_ID"=100)
filter("EMPLOYEE_ID"=100)
从上述执行计划显示的内容可以看出,Oracle 在执行上述 SQL 时已经用上了索引 IDX_EMPLOYEE,并且其执行计划走的就是对该索引的索引跳跃式扫描。
接下来,我们看一种在 where 条件中没有对目标索引的前导列指定查询条件且同时 Oracle 不用该索引的情形。
- 创建测试表 DEPARTMENT
SQL> drop table department purge; SQL> create table department(id number, deptno number); Table created.
- 将该表的列 DEPTNO 的属性设为 NOT NULL
SQL> alter table department modify(deptno not null); Table altered.
- 创建复合 B 树索引,列 ID 为索引前导列,列 DEPTNO 为索引第二列
SQL> create index idx_department on department(id, deptno); Index created.
- 写入记录
SQL> begin 2 for i in 1 .. 10000 loop 3 insert into department select i, trunc(dbms_random.value(1, 10)) 4 from dual; 5 end loop; 6 commit; 7 end; 8 / PL/SQL procedure successfully completed.
- 收集表和索引的统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SCOTT',
tabname => 'DEPARTMENT',
estimate_percent => 100,
method_opt => 'for all columns size 1',
cascade => TRUE);
end;
/
PL/SQL procedure successfully completed.
- 指定查询条件为非索引前导列,并查看其执行计划
SQL> set autotrace traceonly;
SQL> select * from department where deptno = 10;
no rows selected
执行计划
----------------------------------------------------------
Plan hash value: 826413278
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 972 | 6804 | 7 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| DEPARTMENT | 972 | 6804 | 7 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("DEPTNO"=10)
从上述两个 SQL 可以看出,Oracle 中的索引跳跃式扫描仅仅适用于那些目标索引前导列的 distinct 数量较少、后续非前导列的可选择性又非常好的情形,因为索引跳跃式扫描的执行效率一定会随着目标索引前导列的 distinct 值数量的递增而递减。
表连接
顾名思义,表连接就是指多个表之间用连接条件连接在一起,使用表连接的目标 SQL 的目的就是从多个表获取存储在这些表中的不同维度的数据。
表连接的具体内容详见 http://www.opcoder.cn/article/17/
总结
本章详细介绍了 Oracle 数据库中与优化器相关的各个方面的内容,包括优化器的模式、结果集、集的势、可选择率以及可传递性等相关的内容。
- 成本是指 Oracle 根据相关对象的统计信息计算出来的一个值,它实际上代表了 Oracle 根据相关统计信息估算出来的目标 SQL 的对应执行路径的 I/O、CPU 和网络资源的消耗量。
- Cardinality 和 Selectivity 的值会直接影响 CBO 对于相关执行步骤成本值的估算,进而影响 CBO 对于目标 SQL 执行计划的选择。
- 可传递性的意义在于提供了更多的执行路径给 CBO 做选择,增加了走出更高效执行计划的可能性。
- 不是说全表扫描不好,事实上 Oracle 在做全表扫描操作时会使用多块读,这在目标表的数据量不太大时执行效率是非常高的,但全表扫描最大的问题就在于走全表扫描的目标 SQL 的执行时间会不稳定、不可控,这个执行时间一定会随着目标表数据量的递增而递增。
- 通过 B 树索引访问表里行记录的效率并不会随着相关表的数据量的递增而显著降低,即通过走索引访问数据的时间是可控的、基本稳定的,这也是走索引和全表扫描的最大区别。
参考资料
《基于 Oracle 的 SQL 优化 -- 崔华》
http://www.cnblogs.com/kerrycode/p/3842215.html
原创文章,转载请注明出处:http://www.opcoder.cn/article/24/