MapReduce 是一种分布式计算模型,是 Google 提出来的,主要用于搜索领域,解决海量数据的计算问题。
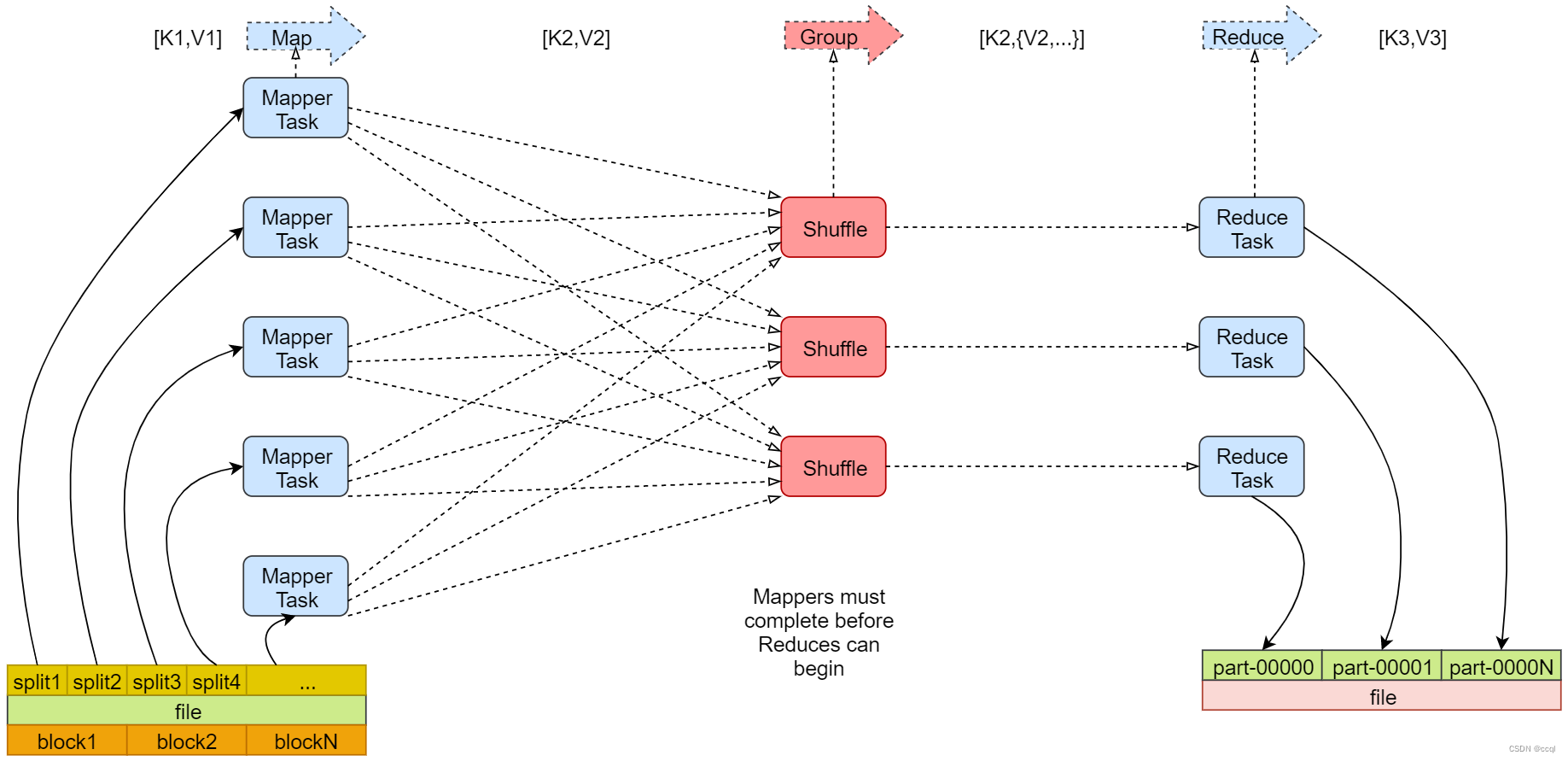
MapReduce 的全套过程分为三个大阶段,分别是 Map、Shuffle 和 Reduce。
Map 阶段
map 就是对数据进行局部汇总,reduce 就是对局部数据进行最终汇总。
把输入文件(夹)划分为很多 InputSplit(Split)
首先,一个 Block 的默认大小为 128M,之所以会有博客写为 64M,是因为在 Hadoop2.x 中修改了这个默认设置。Split 的默认大小为 128M,但并不是每一个 Split 都是 128M,具体分析过程如下,请看如下源码:
SplitSize = Math.max(minSize, Math.min(maxSize, BlockSize));
也就是说 Split 的默认大小取决于 minSize、maxSize 以及 BlockSize 这三个变量。
其中 minSize 的相关源码为:
Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
这行源码中 getFormatMinSplitSize() 的值为 1,getMinSplitSize(job) 的值为 0,因此 minSize 的值为 1。
maxSize 的相关源码为:
maxSize=getMaxSplitSize(job)=Long.MAX_VALUE
也就是说 maxSize 的值为 Long.MAX_VALUE。
BlockSize 的值默认为 128M, 所以最终 SplitSize=128M。
上面说的是 Split 的默认大小与 Block 相同,都是 128M,但并不是说一个 Block 就对应一个 Split,这里仅描述大小关系。之所以说并不是每一个 Split 都是128M,因为文件总不可能都是 128M 的整数倍,那么多出的那一部分怎么处理?源码中会判断 剩余待切分文件大小/splitsize 是否大于 SPLIT_SLOP(值为 1.1),如果大于 1.1,那么会继续切分;如果小于 1.1,会将剩下的部分切到同一个 Split。
举几个例子帮助理解:
- 一个 1G 的文件,会产生多少个 Split?
Block 块默认是 128M,所以 1G 的文件会产生 8 个 Block 块,默认情况下 Split 的大小和 Block 块的大小一致,也就是 8 个 Split。
- 1000 个文件,每个文件 100KB,会产生多少个 Split?
一个文件,不管再小,都会占用一个 Block,所以这 1000 个小文件会产生 1000 个 Block,默认情况下 Split 的大小和 Block 块的大小一致,那最终会产生 1000 个 Split。
- 一个 140M 的文件,会产生多少个 Split?
这个有点特殊,140M 的文件虽然会产生 2 个 Block,但 140M/128M=1.09375<1.1,所以这个文件只会产生一个 Split,这个文件其实再稍微大 1M 就可以产生 2 个 Split。
分配并执行 map 作业
默认一个 Split 对应一个 Map,框架调用 Mapper 类中的 map(…) 函数,map 函数的输入是 <k1,v1>,输出是 <k2,v2>。
Shuffle 阶段
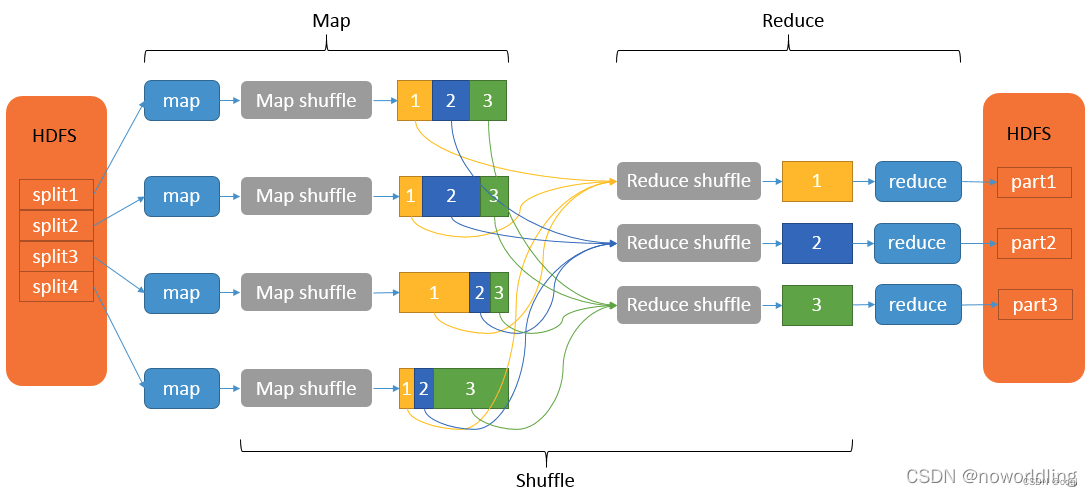
Shuffle 是介于 Map 和 Reduce 之间的一个过程,可以分为 Map 端的 Shuffle 和 Reduce 端的 Shuffle。MapReduce 中,Map 阶段处理的数据如何传递给 Reduce 阶段,是框架中最关键的一个流程,这个流程就叫 Shuffle。
Partition(分区)
分区默认使用 HashPartitioner,使用哈希方法对 key 进行分区,getPatition 方法相关源码为:
(key.hashcode()&Inyeger.MAX_VALUE)%numReduceTask
其中 numReduceTask 默认为 1,而任何数向 1 取余都为 0,因此默认只有一个分区,又因为一个分区对应一个 Reduce 任务,所以也只有一个 Ruduce。若要提高并行度,增加 Reduce 任务数,只需要修改 numReduceTask 数值即可。
但是使用这种哈希方法分区有可能会导致数据倾斜问题,就比如现在一个文件中包含 100 万条数据,每个数据都是一个十以内数字,其中数字 5 出现了 900 万次,现在设置 numReduceTask 为 10,那么根据哈希方法分区,其中的 900 万条数据都被分到分区 5 对应的 Reduce 任务下,这无疑是严重的影响了系统的运行效率。
Sort(排序)
按照 Key,采用字典顺序进行排序,Sort 操作无论是否需要,在逻辑上都必须执行。
Group(分组)
分组是根据 map<key, value> 中的 key 进行分组,目的是提高 Reduce 的并行度。
Combiner(规约)
规约是可选操作,在 map 端输出中先做一次合并,相当于做了一个局部的 reduce 操作。规约操作会将 map 输出的 <k1,v1>,<k1,v2>,<k2,v3> 这样的数据转化为 <k1,{v1,v2}>,<k2,{v3}>。
序列化并写入 Linux 磁盘内存
序列化(Serialization)是指把结构化对象转化为字节流,当要在进程间传递对象或持久化对象的时候,就需要进行这个操作。这里进行序列化是为了把 map 的执行结果写入内存。
反序列化读取数据到不同的 reduce 节点
反序列化(Deserialization)是序列化的逆过程,把字节流转为结构化对象,当要将接收到或从磁盘读取的字节流转换为对象,就要进行这个操作。这里进行反序列化是为了读取数据到不同的 reduce 节点。
Reduce 端数据进行合并、排序、分组
reduce 端接收到的是多个 map 的输出,对多个 map 任务中相同分区的数据进行合并、排序、分组。虽然之前在 map 中已经做了排序和分组,这边也做这些操作其实并不重复,因为 map 端是局部的操作,而 reduce 端是全局的操作,之前是每个 map 任务内进行排序,是有序的,但是多个 map 任务之间就是无序的了。
Reduce阶段
执行 reduce 方法
框架调用 Reducer 类中的 reduce 方法,reduce 方法的输入是 <k2,{v2}>,输出是 <k3,v3>。一个 <k2,{v2}> 调用一次 reduce 函数。程序员需要覆盖 reduce 函数,实现具体的业务逻辑。
保存结果到 HDFS
框架会把 reduce 的输出结果保存到 HDFS 中。
参考资料
【Hadoop】MapReduce原理剖析(Map,Shuffle,Reduce三阶段)
原创文章,转载请注明出处:http://www.opcoder.cn/article/100/